Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Cancel
Python Blog - Page 8
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Blog
- :
- Python Blog - Page 8
Options
- Mark all as New
- Mark all as Read
- Float this item to the top
- Subscribe to This Board
- Bookmark
- Subscribe to RSS Feed
Subscribe to This Board
Latest Activity
(198 Posts)

MVP Emeritus
05-13-2019
08:25 AM
2
0
749
MVP Emeritus
05-08-2019
05:18 PM

1
0
862
MVP Emeritus
04-17-2019
05:00 AM
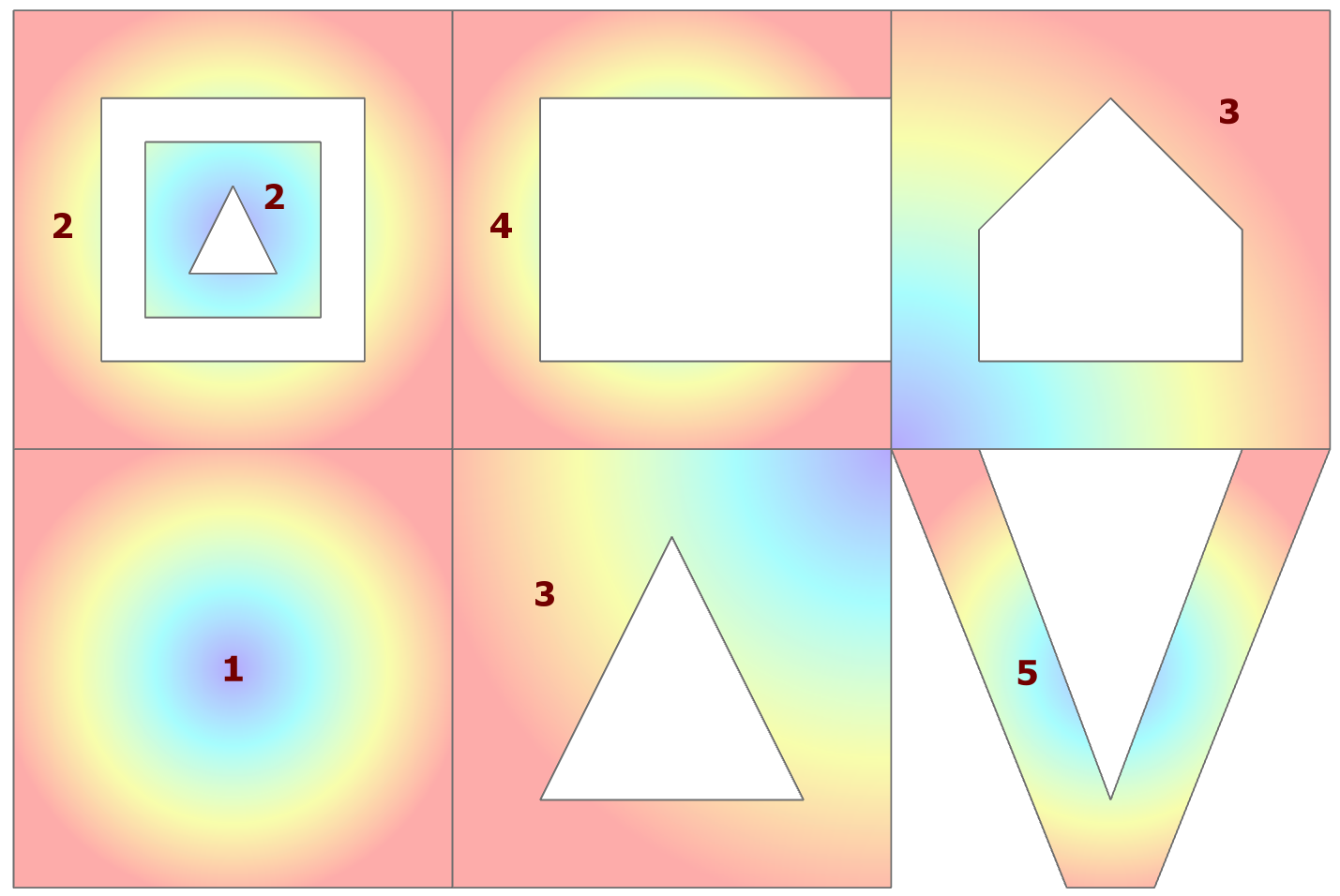
 The polygons that I will be using are shown to the right.
The polygons that I will be using are shown to the right.
0
0
871
MVP Emeritus
04-17-2019
05:00 AM
0
0
722
MVP Emeritus
04-10-2019
04:24 PM
0
0
745
MVP Emeritus
04-10-2019
06:19 AM
1
0
2,150
MVP Emeritus
03-28-2019
07:53 PM

3
0
635
MVP Emeritus
03-18-2019
01:02 AM
2
3
2,983
229 Subscribers
Popular Articles
Turbo Charging Data Manipulation with Python Cursors and Dictionaries
RichardFairhurst
MVP Alum
47 Kudos
91 Comments
The ...py... links
DanPatterson_Retired
MVP Emeritus
18 Kudos
6 Comments
Code Formatting... the basics++
DanPatterson_Retired
MVP Emeritus
16 Kudos
0 Comments