- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS for Power BI
- :
- ArcGIS for Power BI Questions
- :
- Re: ArcGIS Map symbol size not proportional
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
ArcGIS Map symbol size not proportional
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi!
I'm making a size and color map and get problems with symbol size not being proportional to the value of the variable. I've tried different scaling for minimum and maximum size, but the problem persists.
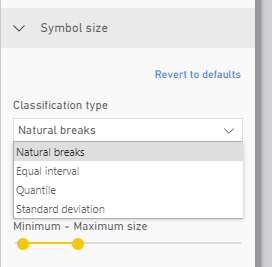
I'm only allowed to choose from the top four classifications in the following list (from the tutorial pages 😞
-Natural breaks
-Equal interval
-Quantile
-Standard deviation
-Manual breaks
-None
I'm guessing that I should have chosen "none" or "manual breaks". Is my data wrongly formatted? In the size field I've added a variable that is defined as numbers?
All the best, Oystein
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Oystein,
Thank you for reaching out! I apologize for the long gap between this post and a response.
I am a Product Engineer for the ArcGIS Maps for Power BI application here at Esri, and I wanted to get in touch to respond.
I have attempted to reproduce this issue in the latest version of ArcGIS Maps for Power BI and I could not reproduce the problem. Based on the time this was posted we have had many fixes which may have addressed this issue.
For reference, here is some documentation on Symbol Sizes and Classification processed in ArcGIS Maps for Power BI
Please reach out to us again if you need any further assistance!
Thank you,
Anthony
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Anthony! Thanks for responding!
I tested this again today, with a recently updated version of Power BI. Problem persists...
Would be extremely helpful if you could test a very simple dataset and see where I'm erring..a lot of people have trouble with this in Power BI's maps as well and they're not fixing the issue.
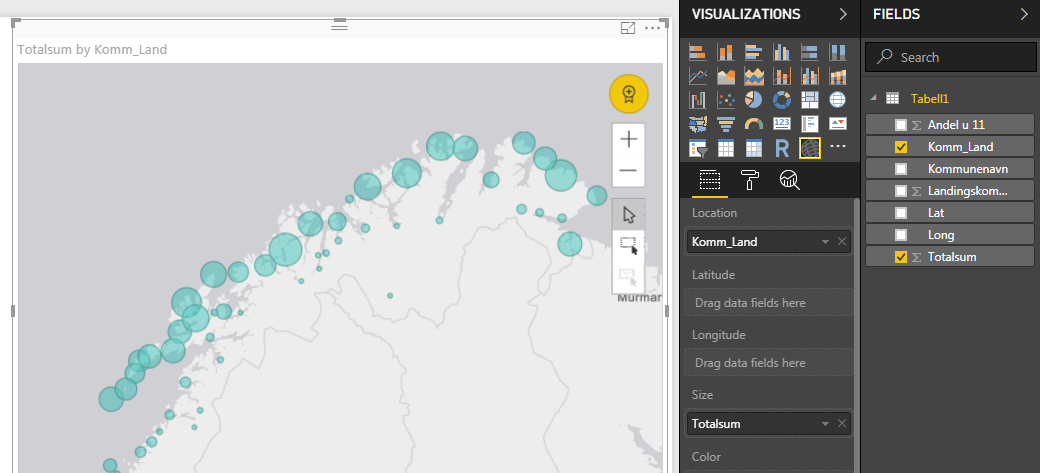
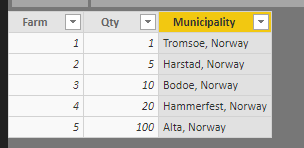
I've pasted screenshots of the data and resulting map below. As you can see, the circles are not proportional in size.
I'm not able to choose the parameters for symbol size that are described in the tutorial.
Btw: the link you provided didn't work!

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey Øystein,
First up, here's a fixed version of the link Anthony provided that will be accessible externally: Change the symbol style—ArcGIS Maps for Power BI | ArcGIS
I'd like to get some perspective on what you mean by "proportional" in this context. My guess is this - the points are scaling based on the image that you pasted above, but a point that has a value of "100" is not 100 times larger than a point that has a value of "1". Is that what you mean?
In case what I've written above is an accurate representation of the issue, I'm going to tag in Alagiri Venkatachalto this post as well so that he can comment on the way that scaling is handled for points, since I don't know if there is an option to scale them at exactly relative sizes.
Josh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Øystein,
Can you tell us what classification type and the number of classes you are using? The classification itself are working as expected, you can read more about the four Classifications available for Size here:
Classification types—ArcGIS Maps for Power BI | ArcGIS
It would be good to get some clarification on what you mean by proportional size. Are you talking about relative size of Points as you zoom in and out of the Map? Or are you talking about the relative size of the Points based on the values in the field that was used in the "Size" field well (that, a Point with a value of 20 does not have a proportional symbol size to a Point with a value of 100)?
Thanks,
Alagiri
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Josh and Alagiri!
Proportional size: I would like to have the area of the symbol to be proportional to the value of the variable. In my example, the 100 should be 10 times the area of the 10.
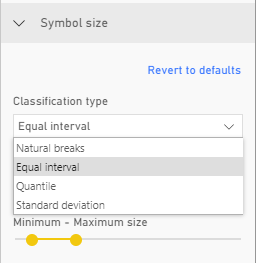
Classification type: I suspect this is where my problem originates. In the tutorial that Josh and Anthony linked to, you can choose between the following classification types (screenshot below). I'm however restricted to the the top five and guess i should have chosen the "none" option to get proportional size. Following the link "classification type" the "none" option is not described.

Would be very helpful if you could provide this option. A lot of users of PowerBI have complained about this error in the PowerBI maps as well, so fixing this could get you quite a few more users 🙂
Here's the link to the PowerBI forum complaining about this: Map dot/bubble sizes should scale properly (with zero= a tiny dot) – Microsoft Power BI
Oystein
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Øystein,
Thanks for clarifying! Now, we understand what you meant by proportional size.
The classification tries to create buckets and puts your data in each bucket based on a predefined range of values that categorize these buckets. These options are configurable through classification types and number of classes. For example, in your case with Qty values of 1, 5, 10, 20, 100. The Map for example tries to create 3 buckets "<20", "20 to 50", ">50". So 1, 5, 10 get put in the first bucket (<20), 20 gets into the second bucket and 100 gets into the last buckets. Each bucket is assigned a proportional symbol size which means that 1,5 and 10 will have the same symbol size, 20 has a slightly larger symbol size and 100 has a larger symbol size. Also, the documentation that you refer to for the Size based classification lists out incorrect classifications. Manual breaks and None are not available for Size based classification.
We will certainly take your input about the proportional symbol size back to the team for consideration.
Thanks,
Alagiri