- Home
- :
- All Communities
- :
- Services
- :
- Implementing ArcGIS
- :
- Implementing ArcGIS Blog
- :
- Using Egdbhealth in System Design
Using Egdbhealth in System Design
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Introduction
- Information Objectives for System Design
- Machine Resources and Utilization
- The Machine
- The Utilization
- Processor
- Memory
- Storage
- Data Inventory and Data Exchange
- Record Counts and Storage By ObjectClass
- Versioning, Archiving, and Replication Status
- Distributed Data Design Consideration
- Versioned Data and Geodatabase Replication
- Archiving Data and Data Exchange
- Attachment Size and Mobile Synchronization
- Summary
Note: This blog post is the third in the series of three planned posts about egdbhealth. The first described introduced the tool, how to install it, and how to run it. The second in the series addressed how to use the tool to evaluate the health of an Enterprise Geodatabase; its primary purpose. This article addresses using egdbhealth in a system design context.
Introduction
Egdbhealth is a tool for reporting on various characteristics of Enterprise Geodatabases (eGDBes). The primary purpose of the tool is to evaluate the “health” of eGDBes. However, the output can also be used in a system design context. This article addresses the system design use case.
For information about installing and running the tool, please refer to the first blog post in this series "What is Egdbhealth?"
Information Objectives for System Design
The Esri system design practice focuses on planning the hardware, software, and network characteristics for the future state of systems based on new or changing requirements.
The current health of an existing system will not necessarily have a strong relationship to a future system that has different requirements. However, depending on the design objectives, information about the current system can be relevant.
For example, in the case of a planned migration from an on-premises system to a cloud platform, it would be quite useful to describe the current system such that it can be faithfully rendered on a cloud platform. Or, requirements driving a design may indicate a need to exchange (replicate, move, synchronize, transform, copy, etc.) large portions of a Geodatabase to another repository. In that case, an inventory of the Geodatabase content can be useful to establish important details about the nature and quantity of data that would need to be exchanged and the optimal ways for that data exchange to occur.
Thus, at a high level, it is the primarily the descriptive information from egdbhealth, rather than the evaluative information, which is pertinent to system design.
This article discusses examples for a SQL Server backed eGDB. However, the principles are the same for eGDBes that are backed by Oracle and PostgreSQL.
Machine Resources and Utilization
For system design cases where the eGDB machine platform will change, it can be useful to understand the current machine resources that support the eGDB and their degree of utilization. For example, if you are migrating an eGDB to a cloud platform, the number of processor cores that the system has on premises has some relevance to the number you might deploy on the cloud.
The Machine
The HTML metadata file produced by egdbhealth will provide resource information about the machine platform on which the RDBMS runs.
In the example below, the SQL Server instance runs on a machine with one processor which presents 8 logical processor cores.
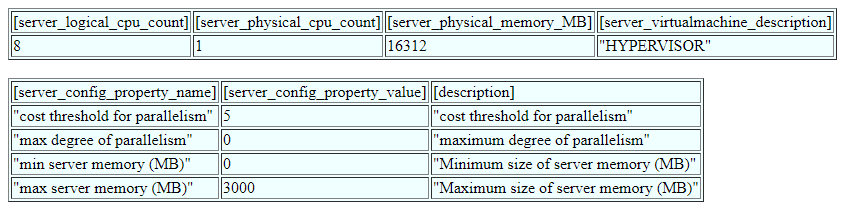
This information from SQL Server leaves some information unclear. For example, SQL Server is not able to report on whether the logical cores are a result of hyperthreading. If they are, then the physical cores would be half of the logical cores (4 physical cores). And, it is the number of physical cores that is most useful for capacity planning in system design. So, this information is good but imperfect.
The HTML also reports the physical memory on the machine (16GiB) and the minimum and maximum memory configured for the SQL Server instance (0 and 3GB). Here we see that the configuration of the SQL Server instance is quite relevant to understanding the relevant memory resources for capacity planning. Although the machine has 16GiB of memory, this SQL Server instance (and the eGDB it supports) does not have access to all of that memory.
The Utilization
The characteristics of the machine, and the configuration of the instance, offers incomplete insight into the degree to which the machine resources are utilized and what resources are truly needed for the current workload.
We can be certain that SQL Server does not use more than 3GB of memory. But, does it use it thoroughly? And, what about the processor resources; are the busy or idle?
Much of the utilization information appears in the Expert Excel file because it is relatively volatile.
Processor
In the case of SQL Server, there is an evaluation in the Expert Excel file called “ProcessorUtil” (Processor Utilization; the Category is “Instance”). It provides a sample of the recent per-minute processor utilization by SQL Server on the machine. In this case, we can see that, for the sampling period, SQL Server uses almost none of the total processor resources of the machine on which it runs.
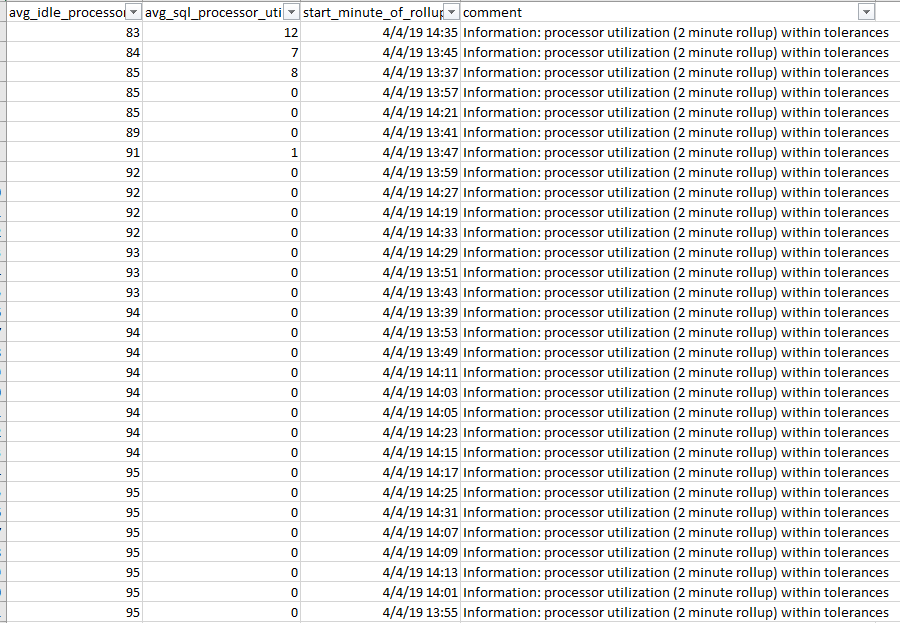
From this, we infer that, if this period is typical, the existing machine has many more processor resources than it needs. If all else is equal, the future system design can specify fewer processor cores to support the eGDB workload. Naturally, for this inference to have any integrity, you must run the tool during typical and/or peak workload periods.
There is another evaluation, CpuByDb (Instance category), which reports which databases in the instance consume the most processor resources. So, in the case that the instance did have significant processor utilization, this information could be used to determine whether that processor utilization related to the eGDB of interest or some other workload in the same SQL Server instance.

Memory
In the case of SQL Server, there are several evaluations which provide insight into the memory utilization inside the instance. Most of these are in the Instance category of the Expert Excel file.
MemoryByDb allows you to see the amount of memory (in this case, rows of data as opposed to SQL statements or other memory consumption) used by each database.
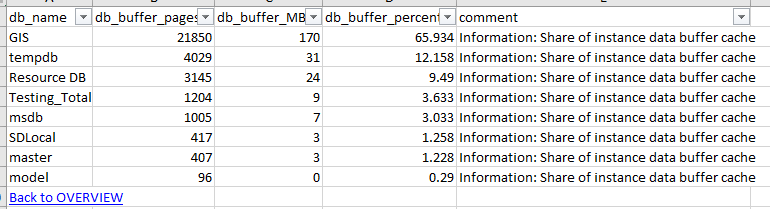
In this case, we see that the “GIS” eGDB is the primary memory consumer in the SQL Server instance. So, it appears reasonable to understand that the eGDB can make use of the better part of the 3GB of instance memory. But, is that too much or not enough for good performance and system health?
The MemoryMetrics evaluation reports on several memory metrics that can offer hints about how much in-demand the instance memory is. In this case, we see that there are warnings that suggest that the existing memory available the instance may be too low for the workload. Thus, we do not know if 16GiB of machine memory is too much or too little. But, we do have reason to believe that 3GB of instance memory is too little.

There are several other memory evaluations in the Expert Excel file. It takes experience and judgement to integrate these observations into an informed judgement about the true memory needs of the system. In this case, as in many cases, the inferences that one can make are incomplete. But, they are better than nothing.
Storage
SQL Server does not provide complete information about the local storage on the machine on which it runs. However, it does provide information about the size of the files in which the eGDB is stored. Much of this information is available in the “Database” category of the Expert Excel file.
The FileSpace evaluation sheet reports on the files in which the eGDB is stored. In this example, we see that there is a single data file (“ROWS”) which is about 6GB in size and a single transaction log file (“LOG”) which has used about 650MB in the past. You can also see the maximum file limits established by the DBA, presumably being an indication of the maximum expected storage for the eGDB.

These data are good indications of the amount of storage that would be needed for a “lift and shift” scenario where the entire eGDB will need to move to a different platform.
Data Inventory and Data Exchange
Another system design case is eGDB data needs to be exchanged with a different repository, perhaps another Geodatabase in a different data center. In these cases, it may be relevant to establish the storage size and other characteristics of the data that will be exchanged, as opposed to the storage size of the entire eGDB.
Record Counts and Storage By ObjectClass
If you know the identity of the ObjectClasses to be exchanged there is information in the Content Excel file to report on the storage size and record counts of those item.
In the Storage category, there is a sheet called “ObjClass” (ObjectClasses). It reports, in considerable detail, the tables from which various eGDB ObjectClasses are composed, the number of rows that they contain, and the amount of storage that is allocated to each of them.
In the example below, there are three ObjectClasses of interest (filtered in the first column): BUILDINGS_NV, COUNTRIES, and SSFITTING. BUILDINGS_NV has about 4,400 records and consumes just over 1.25MB of space. COUNTRIES is versioned, with 249 records in the base table, 66 adds, and 5 deletes (the TableName column calls out the “A” and “D” table names for versioned ObjectClasses).

Thus, we can establish the record counts and approximate storage characteristics of ObjectClasses of interest in the eGDB. At the same time, we can also see which ObjectClasses are registered as versioned. This is critical information for establishing the range of options available for data exchange.
Versioning, Archiving, and Replication Status
In the same Context Excel file, the ObjClassOverview (Inventory category) provides an overview of the versioning, archiving, and replication statuses of all of the ObjectClasses in the eGDB. This provides a more convenient mechanism for planning the range of data interchange mechanisms that would be appropriate for different ObjectClasses.
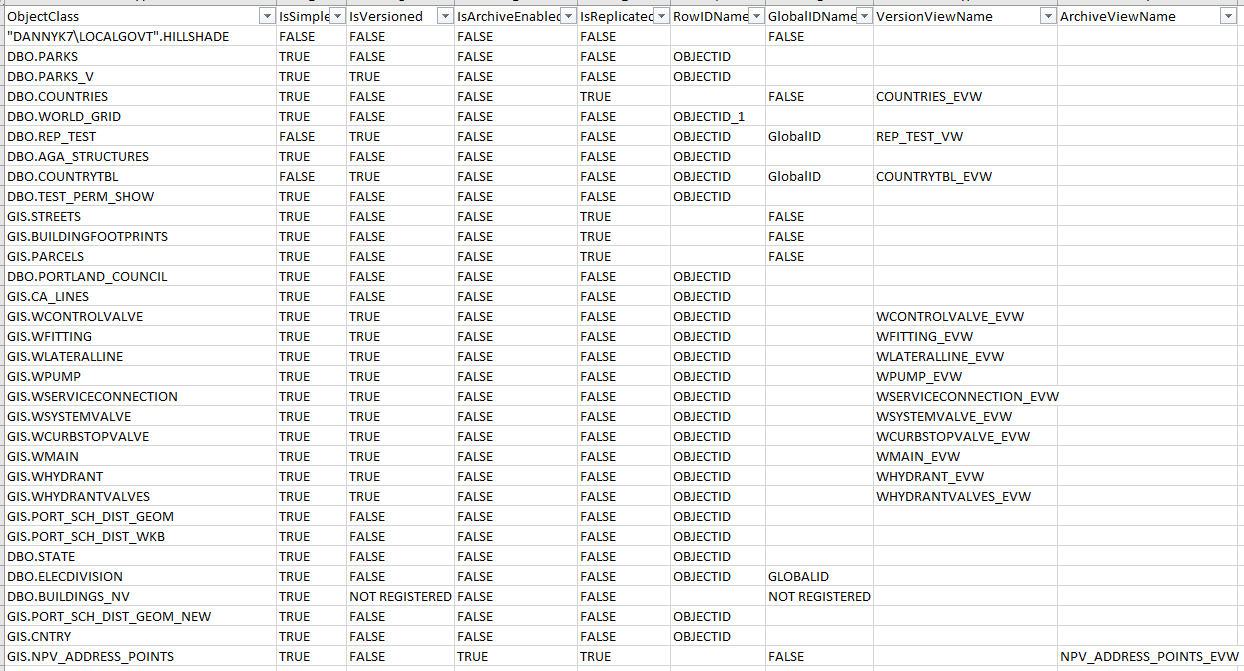
Distributed Data Design Consideration
The ArcGIS documentation refers to this thematic area as “distributed data” and offers general guidance about the various strategies that can be used to move data around: http://desktop.arcgis.com/en/arcmap/latest/manage-data/geodatabases/understanding-distributed-data.h....
Versioned Data and Geodatabase Replication
If an ObjectClass is not already registered as versioned it may or may not be appropriate to do so for the purposes of making use of Geodatabase Replication. This relates to how the data is updated. Most data that is registered as versioned is updated “transactionally”, meaning that only a small percentage of the total records are changed at any given time. This kind of updating is compatible both with versioning and Geodatabase Replication. Other data is updated with methods like “truncate and add”, “delete and replace”, or “copy and paste”. In these cases, most of the records are updated, physically (even if the majority of record values happen to be the same, the physical records have been replaced). That kind of updating is not particularly well-suited to Geodatabase Replication. The information in egdbhealth can tell you about the versioning and replication status of ObjectClasses. But, it does not know how those ObjectClasses are actually updated. Hopefully, those that are registered as versioned are transactionally updated and therefore suitable candidates for Geodatabase Replication.
Archiving Data and Data Exchange
If an ObjectClass has archiving enabled, there may be additional considerations. For example, if the planned data exchange might increase the rate of updates, this could cause the quantity of archive information to grow in ways that are undesirable.
For versioned ObjectClasses that are archive-enabled, the archive information is stored in a separate “history” table. The size of that table does not impact the query performance of the versioned data. In this case, the main design consideration is whether it is practical to persist and use all of the archiving information. In many cases, it will be. But, making the determination requires knowing the archiving status of the ObjectClass and the planned rate of updates.
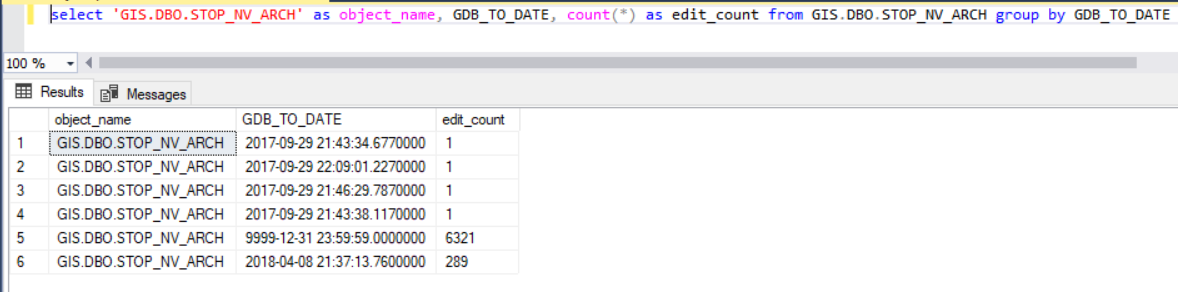
In the case of non-versioned ObjectClasses that are archive-enabled (and branch-versioned ObjectClasses), the archive information is in the main table. Thus, rapid growth of archive information can change the performance tuning needs of ObjectClasses and/or eGDB. Egdbhealth cannot know the future update needs for the data. However, it can report on the historical patterns of updates to non-versioned, archive-enabled ObjectClasses. The Context Excel file contains a “NvArchEditDatesSql” sheet that contains SQL statements for each non-versioned, archive-enabled ObjectClass in the eGDB. These statements are not run automatically because they are resource-intensive queries that do not provide information which is relevant to all circumstance.

In this system design case, however, establishing the rate at which record have accumulated over time may be quite pertinent to planning a data exchange strategy. Use a SQL client such as SQL Server Management Studio to run the queries for the ObjectClasses in question to get a sense of the rate of data update. In this example, we can see a pattern for record updates where the typical update is small (1 record), but there was at least one occasion where there was a large update relative to the size of the ObjectClass (289 records on 8 April 2018):
Attachment Size and Mobile Synchronization
Another design case which relates to distributed data is field-based data collection and attachments. Collector for ArcGIS makes use of efficient mechanisms that are similar to Geodatabase Replication to synchronize “deltas” between client and server. However, the ability to collect large quantities of data in attachments (such as images) and the often limited network conditions in which the data can be synchronized can raise system design issues.
The Expert Excel file has an evaluation “LargeAttachments” that will automatically bring cases of likely concern to your attention. In the example below, the threshold values were not violated, so there was no negative evaluation:

However, it may still be useful to know something about the nature of the existing attachments. The Context Excel file contains a sheet “AttachmentSizeSql” (“Inventory” category) that contains several SQL statements for each ObjectClass that has attachments.

Running these SQL statements in a client such as SQL Server Management Studio allows you to statistically characterize the attachments in various ways: aggregate statistics, top 100 by size, and percentile distribution.
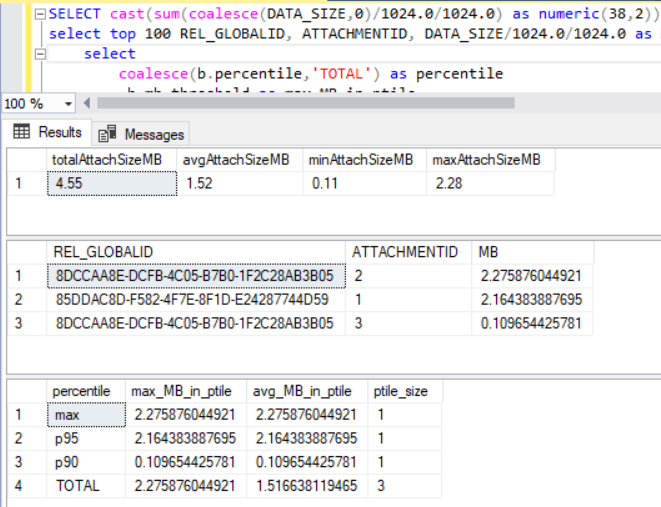
With these statistics, you can understand not only the total amount of information, but whether it is due to a large number of small attachments or a small number of large attachments. Large attachments might be a greater risk for synchronizing over poor network conditions and might lead you to make a recommendation that data collection operate in a disconnected mode and synchronization occur under specific network conditions only.
Attachment size considerations might also lead you to offer recommendations about whether and how it would be practical to handle two-way synchronization (as opposed to one-way). While field-based users might have sufficient network circumstances to upload the attachments that they collect individually, two-way synchronization would mean that all of the attachments collected by other individuals (in the area of synchronization) would have to be downloaded. In some cases, this could be many times the amount of information that would need to be uploaded.
Summary
As a designer of GIS systems, it is not practical for you to have profound expertise in all of the technology areas that pertain to the system. For this reason, your understanding of egdbhealth outputs and what you can do with them has limits. The purpose of this article is to identify some of the most common use cases for egdbhealth outputs for system design. The main areas of interest are (1) machine sizing / resource utilization and (2) data characteristics relevant to data interchange. Following the examples in this article, and generalizing from them for the Oracle and PostgreSQL databases, will allow you to extract useful information from the egdbhealth tool for your design work.
I hope you find this helpful, do not hesitate to post your questions here: https://community.esri.com/thread/231451-arcgis-architecture-series-tools-of-an-architect
Note: The contents presented above are recommendations that will typically improve performance for many scenarios. However, in some cases, these recommendations may not produce better performance results, in which case, additional performance testing and system configuration modifications may be needed.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.