- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- Comparing two point files with one polygon
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am doing some QA to some addressing. I have two address point files.
One from several years ago that the address point is placed on the buildings (which I want the newer data to do). The second is a month old that the address points are at the centroid of the parcel layer.
I need to see where adjustments are needed. I was hoping to find a method to compare the two address points for changes in the address number and road name and the differences of the placement such as that number is not found within that parcel (polygon).
Anyone have any ideas? I have a Basic Licenses for ArcMap 10.5
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You poor address people... spaces sometimes 2, nulls, then concatenate... sometimes 3 fields, sometimes 6.
Notice I provided a LIST (ie there are square brackets around the fields... I just chose a random number of them
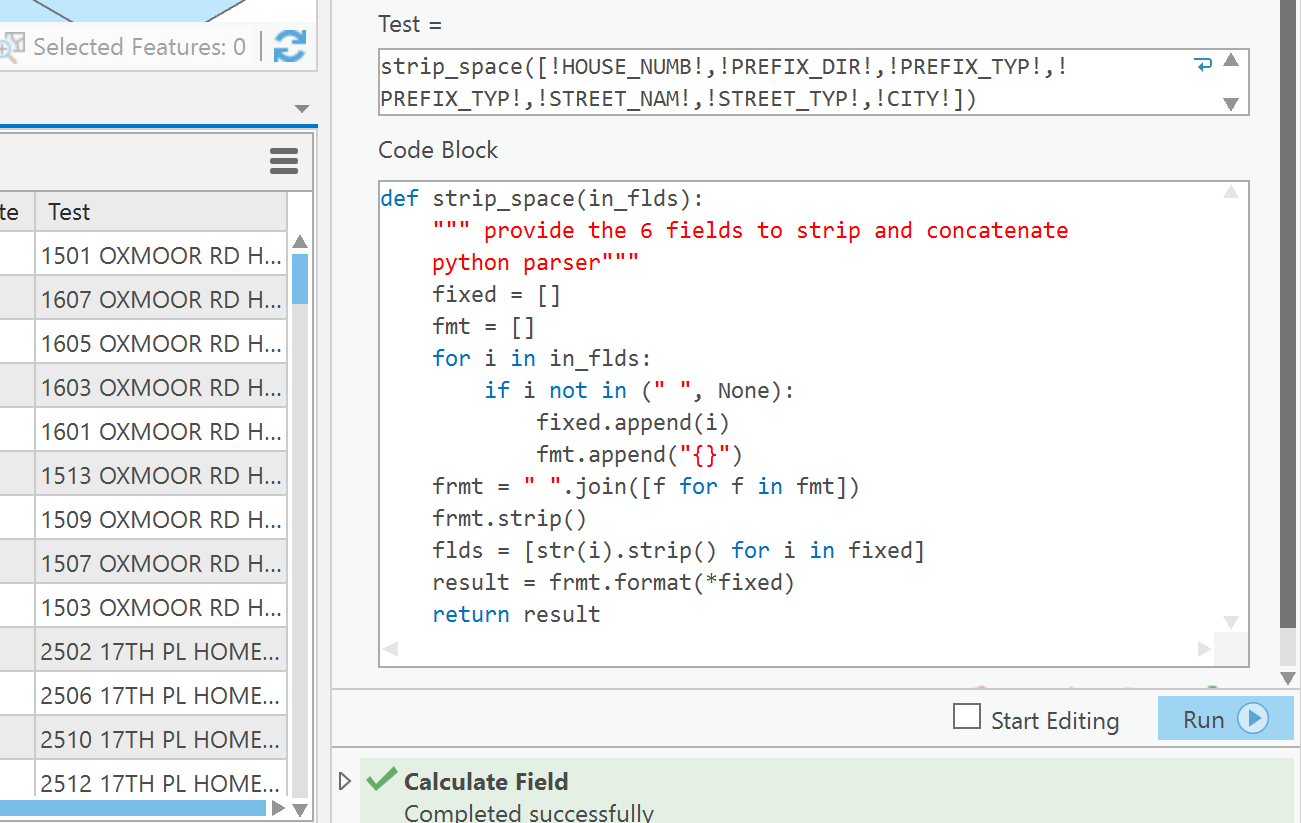
The code
def strip_space(in_flds):
""" provide the 6 fields to strip and concatenate
python parser"""
fixed = []
fmt = []
for i in in_flds:
if i not in (" ", None):
fixed.append(i)
fmt.append("{}")
frmt = " ".join([f for f in fmt])
frmt.strip()
flds = [str(i).strip() for i in fixed]
result = frmt.format(*fixed)
return resultand the cal attached
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hannah, can it be safe to assume the OBJECTID numbers between the two files aren't in direct correspondence?
If they were, then a join based on that common key would make things easier.
If there is not and the address is in one field then you could join on that field
If that is not the case, then you could concatenate the full address in a new file and try a join using those two common fields. This would at least give you the addresses that were the same, leaving you with the addresses that are different.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
They do not have the same object ID. That would make my life too easy. When trying to Concatenate the fields I get a ton of spaces when a field is empty. What is the process should I do to only get information if there is some in it?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You may have to do some prep work... like for now, select only the records that have all the data and don't concatenate those.
I don't know what the data looks like, but if it is a real mess and you have less than a 100 or so, it may just be faster to do a side-by-each comparison and provide a common 'key' field to both. A tax roll number would work, anything, but at some stage every address should have some kind of 'key' to tie it to attributes and location.
If you have a couple of made up records from each table (anonymize them) then some people that work specifically in that area may be able to leap in
jborgion any ideas?
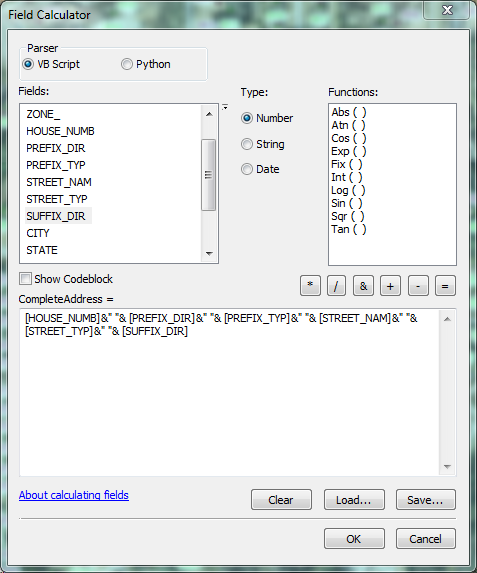
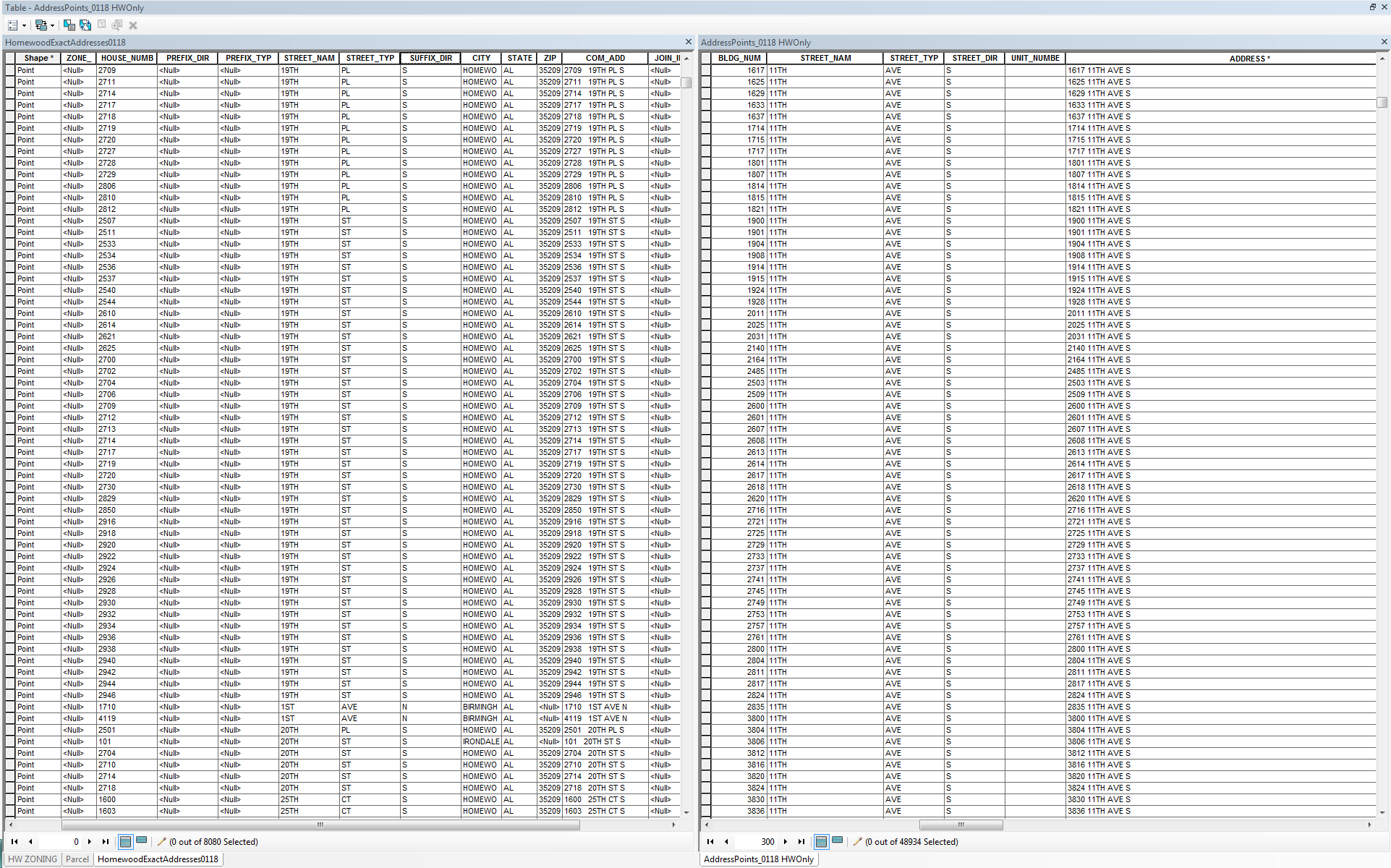
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Grief... well, I would certainly work with a selection to test the process first.
Your address column on the left, should be able to join with the address column on the right...
Have you tried that? The big thing to check is to ensure everything is exact.
There are a few things that you should consider when assessing the results
- hopefully your data columns don't have preceeding/trailing spaces
- there is no point in concatenating columns that contain <null>, so you might want to do a query for the records that are not null in one of the prominent fields that contain tons of nulls
- that will enable you to simplify the concat.. process.
so check the data... run a join, .... select by attributes a street or two and manually inspect the result and report back on any issues.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hooray for addressing changes! They keep us gainfully employed!
I'm thinking along the same lines as Dan: first thing I'd do is look for those that are identical in the components. That whittles down the ones you'll need to examine as far as the actual address (1234 S MAIN ST) goes. Additionally for those that are duplicate records, you need to see if they have the same location, and that might be tricky with a basic license. Add X and Y coordinates and calculate them accordingly in each of point in both feature classes.
Dan has bestowed upon me the way of numpy arrays for making fast comparisons and I'm currently working on an addressing project that deploys them; I won't go into them right now, but they do make comparisons a lot faster, and you'll amaze your co-workers with how cool they are.
First things first: if you don't have a "complete address" field in both feature classes add it. Calculate them accordingly. Then you can perform a relate between the two feature classes using the "complete address" field as the key. Select all of the 'old' and then see which of the new get selected via the relate. You can do the same sort of thing to look for duplicate x and y coordinates.
You'll then need to start looking at just street names: S MAIN ST in the old and S MAIN ST in the new: are there spatially near matches with different house numbers? Are there some new S MAIN ST addresses that are miles away from the old ones?
Does the parcel data have an address in them as well? You could perform a spatial join and then look to see if the address point address is different than the parcel address.
I could go on ad nauseam; there are lots of different ways to skin this cat. Give some of these ideas a spin and when you get stuck, let us know; if I don't see your post, Dan will, and then I'll know.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The newer version of the address points was created from the parcel data. So once I do a spatial join what should I do?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
What about joining the old data to the parcel data? If old address <> parcel address, that address point has changed with respect to address itself, right? Does knowing that have any value in your analysis?
If the new address points were created from the parcel data, is it safe to assume the addresses between them are the same? Does knowing if there might be a difference have any value in your analysis?
I suspect that what you really want to do is move any new address points that have the same address (and/or improved address) to the location of the old address, but before you do that, you really need to be sure the new one qualifies to replace the old one. That can be accomplished with a topology (I think). I can't recall offhand but does a spatial join for points allow for an off set distance? That is, if you were spatially join the new points to the old points and they are not exactly coincident, can the search radius be adjusted.