- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Enterprise
- :
- ArcGIS Enterprise Questions
- :
- Re: Portal Database Backup Increment
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Guys,
I'm seeing an issue in HDD space with a 10.6.1 HA enterprise environment in which daily around ~15Gb worth of the primary portals db folder gets backed up every 6 minutes to the local portal drive on each server.
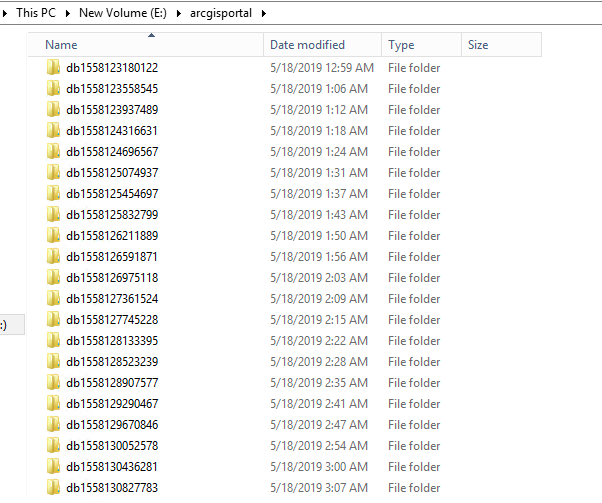
It seems that the pg_basebackup.exe is creating a backup of the primary portal on each of the machines rather quickly, and once full, the portal grinds to a halt and both of the portals are no longer contactable (even the portal with available hard drive space does not appear operational)

It does seem to have started following running the webgisdr utility, which does seem to clean out the backup WAL archive folder, but not the databases created as above.
I have set the webgisdr to run a full backup once a week, thought unfortunately the drives are filling quite rapidly at ~15Gb a day. I don't want to play around with the postgresql configuration manually if I'm missing something simple!
Thanks,
Dean
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dean,
I had seen the similar issue with Highlay available installation (10.6.1). In my case, I had an error in portal :
Creation of recovery.conf file
Erreur du plugin HA. java.lang.Exception: Failed to start the database server. The startup timed out. Please check the log file at \\wsvsgisfile\ArcGISESRI\logs\\database\pgsql.log
With my furrther investigations I got solved my problem. Infact during the configuration, client asked me to move all log files towards a file share. I completely missed the point that the log file must be a local path and not the network path.
As you know that there are two types of log in portal for arcgis :
- Portal log
- Database log
While moving the log towards network share, I had 2 folders for my portal log in the directory which was named after the machine name. On the other had, I only had the log of one Database primary one. The secondary database was unable to start properly. So this was resulting in continous synchronisation of db folders, which were staurating my disk.
Once I move them to local paths and restarted my portals. Everything came in order.
Ayyaz
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
On the primary machine in an HA configuration, the dbXXXX folder is created during a restore. On standby, it's created when the machine is coming back from a failure. Other than that, it shouldn't be getting created on primary. The only situation I'm aware of that will continually create dbXXXX folders on standby is the presence of the promote.dat file within the db directory on the primary machine. Can you see if that file is there and if it is, delete it? It'll create one more dbXXXX folder on standby but should be stable after that.
Can you check the logs and see if there are any indications as to why it's creating the db snapshots on the machines?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Jonathan,
Thanks for getting back so quickly, I thought you might have some idea!
Exactly correct, once moved from the primary server the dbXXXX folders are not recreated, only the walarchive is propagating on primary. Only on the standby the dbXXXX are continually created.
Neither of the servers have a promote.dat within the db folder.
One thing I'm not sure of is whether the standby machine is successfully acting as the standby server, even though it seems to be reporting as so in portaladmin :
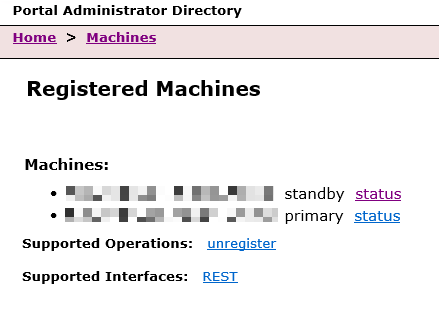
With both reporting as:

I am seeing the following error on the standby machine in the portal logs:

The pgsql.log list only the following:
And on closer inspection there are no postgres.exe services running on the standby which makes it seem it's not "recovered" properly.
I can see in the nodes.properties file in the shared HA configuration directory that the standby machine is not listed:

On the primary server I see this in the DB folder:
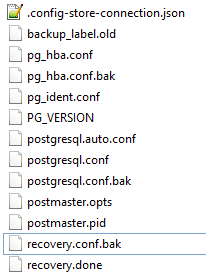
and on the standby in the DB folder:
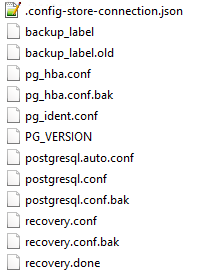
I can see the postmaster files appear to be missing, and they are present in the database backup folders that get copied into the primary db folder.
I have tried replacing the primary db with the backup db from the primary server, but this doesn't resolve I'm afraid.
It seems the key would be to get postgres up and running on the standby server.
I'm guessing it will be something fairly simple as you've specified above related to deleting a status file in the configuration somewhere.
Probably an important point to note is that the now standby machine had its HDD filled due to the WAL archives, and similar things have happened where portal is unable to write or complete writing to a failover configuration file, so is possibly related to this.
Thanks,
Dean
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Check the Event Viewer. When you see "database startup timed out" type errors, that means that the database isn't starting correctly and the only place the cause is logged is in the Event Viewer. You'll see a bunch of errors in there, but there will be one that tells you why the database can't start.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Jonathan,
I've taken a look and can find several references to the DB not starting correctly in the server event logs:



I've tried copying the postmaster.pid from the production system, but then get the following error appearing in the logs:

as the 17200 value in the PID file seems to relate to the postgres.exe process on the primary machine.
So I then attempted to start a postgresql service manually in a cmd running as the portal for arcgis service account (the same domain account as is running the primary portal), and get the following:

I attempted the same on the primary server to see whether this is expected and got the same result attempting to run the process, so I'm assuming something else is going on in the background to get it to run as this user, as it is running with that user on the primary.
As a temporary workaround I have created a test user account that successfully starts the postgres.exe server and stops the creation of the db backups every six minutes, but obviously not a great workaround.
This has populated the standby node into the nodes.properties for portal-ha, so getting the db running as the service account seems to be what needs to happen.
If you have any thoughts on why this may be happening from a Portal / Esri perspective that'd be incredibly appreciated!!
Dean
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The important error is the "not a database cluster directory" error. What are the contents of the latest dbxxxx folder? Do they match the contents of the db folder on the primary machine?
What's likely happening is that the standby is detecting that the database is not running so it thinks it's coming back from a failure and gets a new DB snapshot. The standby can't start the DB again, (due to the not a database cluster directory error), and then again, it thinks it's coming back from a failure because the database isn't running. That's likely the loop it's stuck in. Figuring out what the PG doesn't like about the db directory is the first step by looking at the contents.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Jonathan,
I've done a couple of comparisons which might shed some light.
Compare 1 - primary db and backed up dbXXXX on standby:
I could find the following files not present in one or the other between the primary db and the backed up dbXXXX:

So the backed up db is missing a few pg_internal.init files in the \base and \global folders.
Given the problem appears to be starting the database, could these few files these be the culprits?
There were also quite a few binary file differences between these two, which I imagine is just the database contents itself, so probably not the issue:

And the following text files had different contents:

With the postmaster.opts only having a difference in "/" vs "\" for directory paths for some reason

Compare 2 primary db and standby db:
I've also performed a comparison between the primary db and the standby db folders (i.e. not a dbXXXX backup folder) to see whether the process moving from dbXXXX to db folder on the standby reduces some of the differences in the db.
The following are the differences between primary and standby db folders:

there are as in compare 1 plenty of binary file differences.
and the following files are largely present only in the primary db, with the recovery.conf in the db on the standby machine which sounds about right:
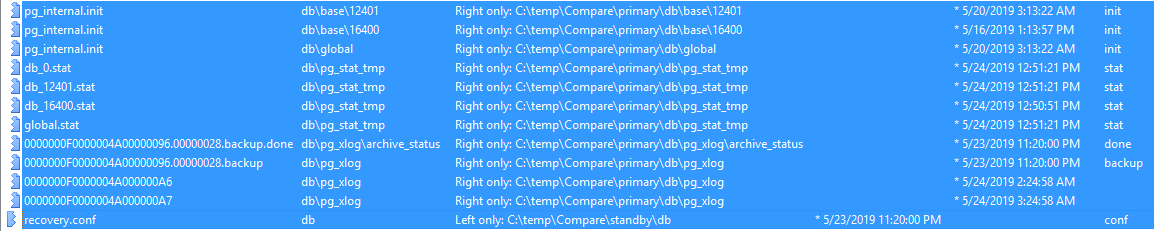
I am able to connect to each of the two servers postgres instances via pgadmin using the psa credentials and accessing the gwdb.
If I'm understanding you correctly there should possibly be fewer differences between the primary and standby databases than I've shown above? If so would it be worth copying the primary db to replace the standby db and keeping the recovery.conf file, or similar?
Thanks!
Dean
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I believe the only time you'll see the "not a database cluster directory" error is if PG determines that the contents of the db folder are invalid or missing files/folders. So yes, any of those differences could be causing a problem, (aside from the backward vs forward slash, that can be ignored). Unfortunately, I don't know enough about PG to know what it doesn't like.
Yes, moving the primary db to the standby machine is a a good test. That'll tell you if the db folder was moved over correctly via the "failback" logic, things would work normally. It'll tell you whether the db is good on primary, which I assume is the case otherwise primary would be broken as well. Stop standby, move over the db folder, and start the db manually via pg_ctl. If that works, then something is happening when standby is asking the primary for a snapshot via the pg_basebackup utility.
Unfortunately, this may require more in-depth troubleshooting than what Geonet can provide, so I suggest you reach out to Tech Support. You can let them know to keep me in the loop if you'd like.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dean,
I had seen the similar issue with Highlay available installation (10.6.1). In my case, I had an error in portal :
Creation of recovery.conf file
Erreur du plugin HA. java.lang.Exception: Failed to start the database server. The startup timed out. Please check the log file at \\wsvsgisfile\ArcGISESRI\logs\\database\pgsql.log
With my furrther investigations I got solved my problem. Infact during the configuration, client asked me to move all log files towards a file share. I completely missed the point that the log file must be a local path and not the network path.
As you know that there are two types of log in portal for arcgis :
- Portal log
- Database log
While moving the log towards network share, I had 2 folders for my portal log in the directory which was named after the machine name. On the other had, I only had the log of one Database primary one. The secondary database was unable to start properly. So this was resulting in continous synchronisation of db folders, which were staurating my disk.
Once I move them to local paths and restarted my portals. Everything came in order.
Ayyaz
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
FYI sounds like you're aware of this now, but the initial arcgisportal directory, (the path defined during the setup) must be a local path. This defines the path for the logs, index, temp, and most importantly, the database directories. We've been validating that the directory is not a share since 10.3:
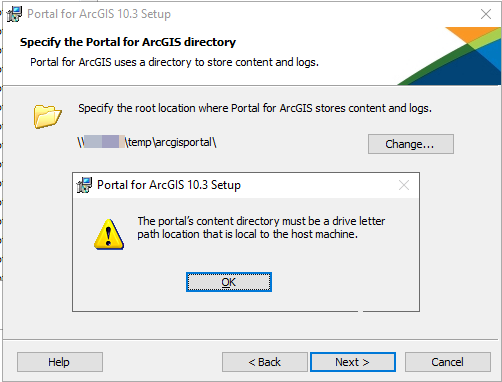
Can you describe how you configured the logs for the database to be under the share? I think the only way to update the log path after the portal is created is by modifying the DB config files manually.