- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Enterprise
- :
- ArcGIS Enterprise Questions
- :
- Portal Database Backup Increment
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Guys,
I'm seeing an issue in HDD space with a 10.6.1 HA enterprise environment in which daily around ~15Gb worth of the primary portals db folder gets backed up every 6 minutes to the local portal drive on each server.
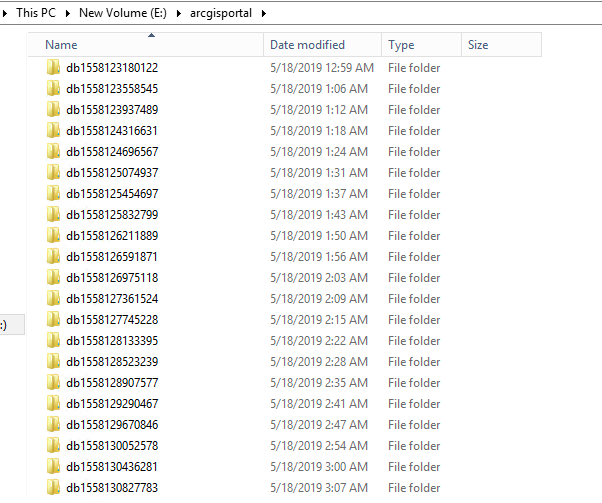
It seems that the pg_basebackup.exe is creating a backup of the primary portal on each of the machines rather quickly, and once full, the portal grinds to a halt and both of the portals are no longer contactable (even the portal with available hard drive space does not appear operational)

It does seem to have started following running the webgisdr utility, which does seem to clean out the backup WAL archive folder, but not the databases created as above.
I have set the webgisdr to run a full backup once a week, thought unfortunately the drives are filling quite rapidly at ~15Gb a day. I don't want to play around with the postgresql configuration manually if I'm missing something simple!
Thanks,
Dean
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
HI Jon,
Yes you are right. I configured my portal and I changed the directory throught portaladmin interface. Then I had three folders in my shared log folder (as shown in the figure):
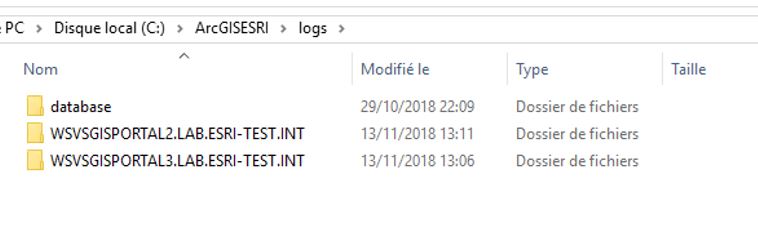
As I told you that I completely missed this point. As soon as I configured the log directory towards a local path D:\arcgisportal\logs. The problem was solved.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
thank you so much for your insights, as soon as you said that I had a feeling that it just had to be exactly that as I had been streamlining both test and production environments to utilise common application, widget, logs and backup locations and as you say you can update the logs to a shared folder for which I had not anticipated such a catastrophe, as it's the log files and not the applications themselves and the admin portal allows you to change it:
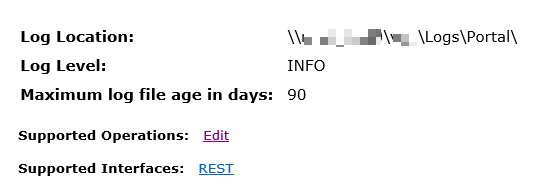
Once I amended the log path back to the local directory in Portal Admin the postgres.exe that I was running with a local testuser account on the failover server stopped and the postgres.exe services started running with the correct service account:
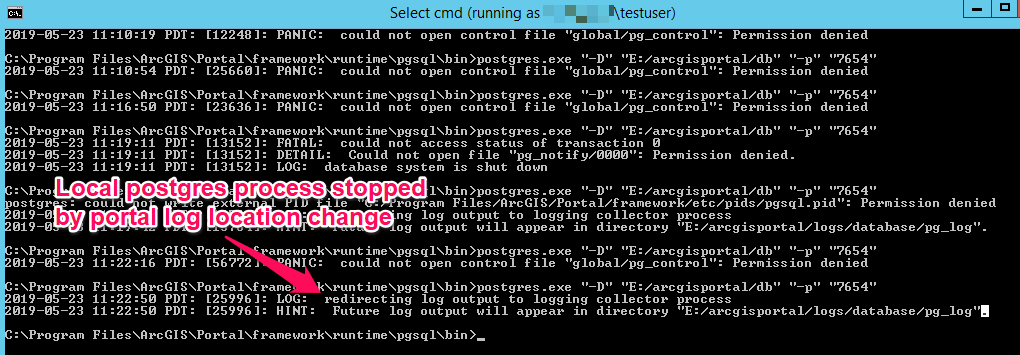
Failover Server:

Both portals are now up and running as they should be.
and obviously Jonathan Quinn Thanks so much for helping out with the troubleshooting, it was incredibly useful to run through troubleshooting this one with you. It's not so obvious that the logs create such an issue, and as you say you can't set as a network share in the configuration and this is one that slipped past me.
These decision to migrate the logs paths to a network share were actually kicked into action by the webgisdr utility filling up the backup\walarchive folder causing HDD space issues and Portal downtime, ironically the opposite effect intended creating the backups.
As a workaround we'll write a script that clears the local log folders once they reach a particular age / size and will keep the webgisdr running at weekly intervals, though I'm sure there is a better internal solution that could be put into Portal to protect against such things happening.
Thanks again so much for your help guys!
Dean
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »