- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Using UpdateCursor to add content of pandas DataFr...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Using UpdateCursor to add content of pandas DataFrame to feature class attribute table
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'm creating a script tool where the user is able to map the trade of commodities from an exporting country to a set of importing countries. In the script, a Feature Class is created representing the latitude and longitude of the captial of the exporting country and the latitude and longitude of the capitals of the importing countries. A line is then drawn between these sets of points to indicate the flow of the commodity.
The commodity data used in the script tool were downloaded as a csv file and then converted to a pandas DataFrame. The individual using the tool is able to specify parameters to subset the pandas DataFrame. For example, a user could specify that they're interested in the trade of Coffee from Burundi for the years 2010 and 2011. The tool will then display the flow of coffee to Burundi's trade partners for the years 2010 and 2011. In subsetting the DataFrame, the only information left in the DataFrame is that which is needed to map the flows between trade partners.
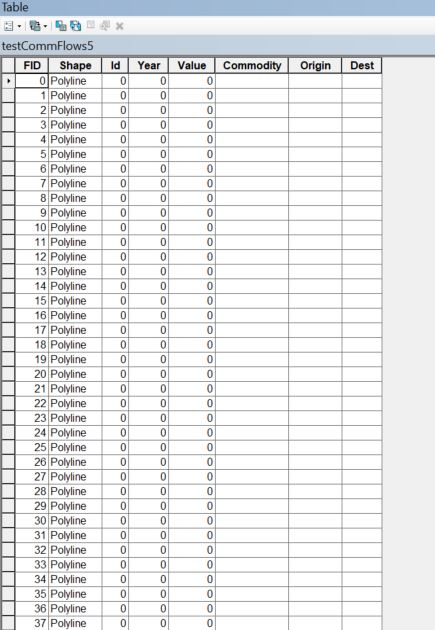
Unfortunately, I'm running into trouble when I attempt to add the content of the pandas DataFrame to the Feature Class. When the Feature Class is created it simply represents the connections between exporting and importing countries (the attribute table of the Feature Class at this stage is shown in the attached image CommodityFlows1). I then add columns for the data that I intend to bring in from the pandas DataFrame (the attribute table after these columns are added are shown in CommodityFlows2). I then attempt to use UpdateCursor to add the information from the pandas DataFrame to the Feature Class' attribute table. However, when I do this, I receive the error: "An error occurred: 0".
I've isolated the problem to this part of my code:
#add year, value, commodity name, origin, and destination information
j = 0
with arcpy.da.UpdateCursor(fc, ("Year", "Value", "Commodity", "Origin", "Dest")) as cursor:
for ROW in cursor:
ROW[0] = df_trade["year"][j]
ROW[1] = df_trade["export_val"][j]
ROW[2] = df_trade["comm_name"][j]
ROW[3] = df_trade["country_origin"][j]
ROW[4] = df_trade["country_dest"][j]
cursor.updateRow(ROW)
j += 1What I'm doing in the above snippet is updating the attribute table shown in CommodityFlows2 using UpdateCursor. I'm going line-by-line in the Feature Class and adding the value from the pandas DataFrame (df_trade) and adding the value for each row for the particular variable of interest. I'm iterating row-by-row in the pandas DataFrame using j += 1.
What is confusing to me is that my entire script runs just fine if I use IDLE (in other words, my Feature Class is created, the flows of commodities are drawn, and the information in the pandas DataFrame is added to the Feature Class). Am I somehow using the UpdateCursor incorrectly in the ArcGIS environment?
Solved! Go to Solution.
{kind=link}
{kind=link}
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
NumPyArrayToTable or NumPyArrayToFeatureclass
NumPyArrayToTable—Data Access module | ArcGIS Desktop
NumPyArrayToFeatureClass—Data Access module | ArcGIS Desktop
Just convert your dataframe to a numpy structured array (akin to a numpy recarray )
There is also
ExtendTable—Data Access module | ArcGIS Desktop
if you need to do attribute joins of a table to an existing table or featureclass
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
NumPyArrayToTable or NumPyArrayToFeatureclass
NumPyArrayToTable—Data Access module | ArcGIS Desktop
NumPyArrayToFeatureClass—Data Access module | ArcGIS Desktop
Just convert your dataframe to a numpy structured array (akin to a numpy recarray )
There is also
ExtendTable—Data Access module | ArcGIS Desktop
if you need to do attribute joins of a table to an existing table or featureclass
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you Dan. As you suggested, I converted my pandas DataFrame to a NumPy Array and then used the NumPyArrayToTable module to create a dBASE Table. I found this resource to be helpful in making the conversion:
pandas.DataFrame to ArcGIS Table - Community for Data Integration - myUSGS Confluence
Once the dBASE Table was created, I was able to add the dBASE content to my Feature Class. Thanks for the help!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Curtis Price, someone using your myUSGS Confluence content.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Now if I could only get Curtis Price to skip the Pandas part and just stick with numpy 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan,
My dates that are objects in the dataframe are being stored as text in my gdb table. Also, my population values are stored as float.
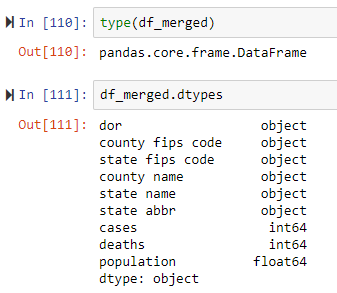
I'm using the NumPyArrayToTable. How am I able to have the date values stored as date data type and the population as an integer when populating a gdb table?
<source>
import numpy as np
import arcpy
x = np.array(np.rec.fromrecords(df_merged.values))
names = df_merged.dtypes.index.tolist()
x.dtype.names = tuple(names)
if not arcpy.Exists('C:/Coronavirus/covid19.gdb/nyt_covid19'):
arcpy.da.NumPyArrayToTable(x, 'C:/Coronavirus/covid19.gdb/nyt_covid19')
else:
arcpy.Delete_management('C:/Coronavirus/covid19.gdb/nyt_covid19')
arcpy.da.NumPyArrayToTable(x, 'C:/Coronavirus/covid19.gdb/nyt_covid19')
</source>
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The form and function of the Update Cursor don't change between environments. You say it runs in IDLE but not in "ArcGIS." Can you elaborate on how you are running it from within ArcGIS? Is this a script tool or are you trying to run it from the interactive Python window in ArcMap or Pro?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I should have been more clear. By "ArcGIS", I meant a script tool that I was running from ArcGIS.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Paul McCord,
I ran into similar issue when I was trying to add a list of records from a pandas dataframe to a feature class using arcpy. Since I was attempting to add features, I ended up using the InsertCursor class instead of UpdateCursor. I would assume you'd wanna use the UpdateCursor when updating existing features. Either way, below is the code snippet that ended up working for me without having to use the NumpyArrayToTable class.
import arcgis
import pandas as pd
import arcpy
from arcpy import env
import os
#Import the csv to pandas dataframe
pd.set_option('display.max_columns', None)
df = pd.read_csv(r'<File_Name>.csv', dtype=str, sep='|', encoding = "ISO-8859-1")
df.head(20)
#DataFrame consisting of 3 columns and 100 rows each
inputs = df.loc[0:100,['column1','column2', 'column3']].values.tolist()
fields = ['field1','field2','field3']
env.overwriteOutput = True
env.workspace = r"X:\<sde location>"
fcname = "Feature Class"
fc = os.path.join(env.workspace,fcname)
cursor = arcpy.da.InsertCursor(fc,fields)
for row in inputs:
cursor.insertRow(row)Notice how I have used values.tolist() method. This method is supposed convert the DataFrame to list of tuples that can then be iterated by row while inserting the features into the feature class in database.
Let me know what you think!
Thanks,
Imtiaz