- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Dynamic segmentation with respect to a control...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Re: Dynamic segmentation with respect to a control factor Additional Requirements
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I was able to figure out the error from earlier, but i have one more request.
If i have other fields in the table i want to also show on the out_table for example see table below:
| Data | UniqueID | Item ID | Begin | End | Input Table |
| Observation1 | 555 | 1000 | 0 | 1 | |
| 555 | 1001 | 0 | 5 | ||
| 555 | 1002 | 1 | 7 | ||
| 555 | 1003 | 4 | 5 | ||
| 555 | 1004 | 3 | 5 | ||
| Observation2 | 600 | 2001 | 0 | 3 | |
| 600 | 2002 | 2 | 6 | ||
| 600 | 2003 | 3 | 5 |
| Data | UniqueID | Begin | End | Item ID | Output Table |
| Observation1 | 555 | 0 | 1 | 1001 | |
| 555 | 1 | 3 | 1001; 1002 | ||
| 555 | 3 | 4 | 1001; 1002; 1004 | ||
| 555 | 4 | 5 | 1001; 1002; 1003; 1004 | ||
| 555 | 5 | 7 | 1002 | ||
| Observation2 | 600 | 0 | 2 | 2001; 2002 | |
| 600 | 2 | 3 | 2001; 2002 | ||
| 600 | 3 | 5 | 2002; 2003 | ||
| 600 | 5 | 6 | 2003 |
Is there a way to differentiate between records that are within a certain range(with UniqueID) as shown in the table above, plus have other fields for that range (with same uniqueID) in the output table?
I am really grateful for your help thus far guys, Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Most likely you are viewing the thread in your inbox, which doesn't enable attachments. If you click the title of this thread, you will view it outside of your inbox, and they should appear.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You're correct about the gaps in the dataset.
Sorry about that, It skipped my mind.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Is it okay to have the gaps? The code can be adjusted if you need to leave those out.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Yes, it is ok to have segments with gaps (and without ItemIDs).
And I think the code should be fine with the result of your test, but i still can't see the attachments.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here's the code that is in the attachment. I posted this issue in the GeoNet Help place in hopes of getting an answer on the attachment issue.
Some users unable to get attachments.
def main():
import arcpy
import os
# Local variables
sourcegdb = r"N:\TechTemp\BlakeT\Work\TEMP.gdb"
table_in = os.path.join(sourcegdb, "SegmentSequence_input")
# Create output table
arcpy.CreateTable_management(sourcegdb, "SegmentSequence_output")
table_out = os.path.join(sourcegdb, "SegmentSequence_output")
arcpy.AddField_management(table_out, "UniqueID", "LONG")
arcpy.AddField_management(table_out, "Begin", "DOUBLE")
arcpy.AddField_management(table_out, "End", "DOUBLE")
arcpy.AddField_management(table_out, "SegmentItems", "TEXT", "", "", 255)
arcpy.AddField_management(table_out, "MaxDate", "DATE")
# Identify observation groups
sqlprefix = "DISTINCT UniqueID"
sqlpostfix = "ORDER BY UniqueID"
observations = tuple(uid[0]
for uid in arcpy.da.SearchCursor(
table_in,
["UniqueID"],
sql_clause=(sqlprefix, sqlpostfix)
)
)
fields_in = [
"ItemID",
"Begin_Station_Num_m",
"End_Station_Num_m",
"TestDate"
]
fields_out = [
"UniqueID",
"Begin",
"End",
"SegmentItems",
"MaxDate"
]
with arcpy.da.InsertCursor(table_out, fields_out) as i_cursor:
for obsv in observations:
# Read table into dictionary with rows as item: (begin, end, date)
where_clause = "UniqueID = {}".format(obsv)
itemsdict = {r[0]:(r[1], r[2], r[3])
for r in arcpy.da.SearchCursor(
table_in,
fields_in,
where_clause
)
}
# Identify segments
allsegments = [s[0] for s in itemsdict.values()] + [s[1] for s in itemsdict.values()]
segments = tuple(sorted(set(allsegments))) ## creates only unique segments
del allsegments
# Identify items and date in each segment
for i in range(len(segments)-1):
begin = segments
end = segments[i + 1]
seg_itemsdict = {k: v[2]
for k, v in itemsdict.items()
if v[0] <= begin and v[1] >= end
}
# Write segment items to output table
itemstext = str(seg_itemsdict.keys()).strip('[]')
itemsdates = [i for i in seg_itemsdict.values() if i is not None]
## Do not attempt to find max date if there
## are no dates for the items in the segment.
if len(itemsdates) > 0:
itemsdates_max = max(itemsdates)
else:
itemsdates_max = None
row = (obsv, begin, end, itemstext, itemsdates_max)
i_cursor.insertRow(row)
if __name__ == '__main__':
main()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Got it now...running a test on it and will let you know ASAP the outcome. Thanks
also thanks for the attachment issue on GeoNet
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Just finish running it and i got an error (kindly see image below), also i still have the duplicate segments.
The resultant table has over 12600 duplicate records of one uniqueID.
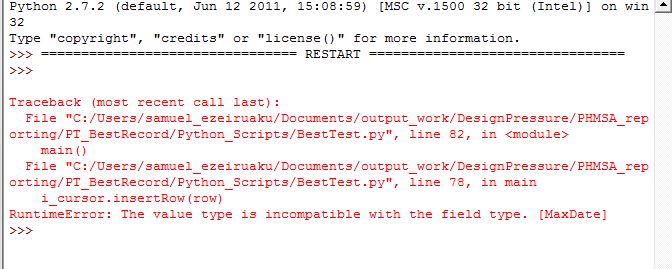
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The code from earlier worked perfectly, but the only thing is it doesn't include syntax for the UniqueIDs.
Is there a way to modify it to include the UniqueIDs also if its ok with you we can scrap out the dates from the script. Thanks (see code below)
def main():
import arcpy
import os
# Local variables
mygdb = r"C:\Users\samuel_ezeiruaku\Documents\output_work\DesignPressure\PHMSA_reporting\PT_BestRecord\HT_Overlap_Inscope.gdb"
mytable = os.path.join(mygdb, "PNGTS_RefinedPT")
# Read input table into dictionary
itemsdict = {}
with arcpy.da.SearchCursor(mytable, ["HT_Item_Number", "Begin_Station_Num_m", "End_Station_Num_m"]) as s_cursor:
for item, begin, end in s_cursor:
itemsdict[item] = (begin, end)
# Identify segments
allsegments = [i[0] for i in itemsdict.values()] + [i[1] for i in itemsdict.values()]
segments = tuple(sorted(set(allsegments)))
del allsegments
# Create output table
arcpy.CreateTable_management(mygdb, "SegmentSequence_output")
mytable_out = os.path.join(mygdb, "SegmentSequence_output")
arcpy.AddField_management(mytable_out, "BeginFt", "FLOAT")
arcpy.AddField_management(mytable_out, "EndFt", "FLOAT")
arcpy.AddField_management(mytable_out, "SegmentItems", "TEXT", field_length=255)
# Write segment items to output table
with arcpy.da.InsertCursor(mytable_out, ["BeginFt", "EndFt", "SegmentItems"]) as i_cursor:
for enum, seg in enumerate(segments):
try:
begin = seg
end = segments[enum + 1]
except IndexError:
break
seg_items = [k for k, v in itemsdict.items() if v[0] <= begin and v[1] >= end]
row = (begin, end, str(seg_items).strip('[]'))
i_cursor.insertRow(row)
if __name__ == '__main__':
main()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I noticed in the attribute table screenshot you posted earlier that the ItemIDs are coming through with a decimal. I originally assumed they were integer (LONG) but if they have a decimal it has to be DOUBLE. Please list all your fields and their data type so we are on the same page.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
| Fields | Data Type |
| UniqueID | Long |
| ItemID | Long |
| Begin_Station_Num_m | Double |
| End_Station_Num_m | Double |
| TestDate | Date |