- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Dynamic segmentation with respect to a control...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Re: Dynamic segmentation with respect to a control factor Additional Requirements
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I was able to figure out the error from earlier, but i have one more request.
If i have other fields in the table i want to also show on the out_table for example see table below:
| Data | UniqueID | Item ID | Begin | End | Input Table |
| Observation1 | 555 | 1000 | 0 | 1 | |
| 555 | 1001 | 0 | 5 | ||
| 555 | 1002 | 1 | 7 | ||
| 555 | 1003 | 4 | 5 | ||
| 555 | 1004 | 3 | 5 | ||
| Observation2 | 600 | 2001 | 0 | 3 | |
| 600 | 2002 | 2 | 6 | ||
| 600 | 2003 | 3 | 5 |
| Data | UniqueID | Begin | End | Item ID | Output Table |
| Observation1 | 555 | 0 | 1 | 1001 | |
| 555 | 1 | 3 | 1001; 1002 | ||
| 555 | 3 | 4 | 1001; 1002; 1004 | ||
| 555 | 4 | 5 | 1001; 1002; 1003; 1004 | ||
| 555 | 5 | 7 | 1002 | ||
| Observation2 | 600 | 0 | 2 | 2001; 2002 | |
| 600 | 2 | 3 | 2001; 2002 | ||
| 600 | 3 | 5 | 2002; 2003 | ||
| 600 | 5 | 6 | 2003 |
Is there a way to differentiate between records that are within a certain range(with UniqueID) as shown in the table above, plus have other fields for that range (with same uniqueID) in the output table?
I am really grateful for your help thus far guys, Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
My eyes are starting to cross. Please test this and see if it's accurate.
def main():
import arcpy
import os
# Local variables
sourcegdb = r"N:\TechTemp\BlakeT\Work\TEMP.gdb"
table_in = os.path.join(sourcegdb, "SegmentSequence")
# Create output table
arcpy.CreateTable_management(sourcegdb, "SegmentSequence_output")
table_out = os.path.join(sourcegdb, "SegmentSequence_output")
arcpy.AddField_management(table_out, "UniqueID", "LONG")
arcpy.AddField_management(table_out, "Begin", "DOUBLE")
arcpy.AddField_management(table_out, "End", "DOUBLE")
arcpy.AddField_management(table_out, "SegmentItems", "TEXT", "", "", 255)
arcpy.AddField_management(table_out, "MaxDate", "DATE")
# Identify observation groups
sqlprefix = "DISTINCT UniqueID"
sqlpostfix = "ORDER BY UniqueID"
observations = tuple(uid[0]
for uid in arcpy.da.SearchCursor(
table_in,
["UniqueID"],
sql_clause=(sqlprefix, sqlpostfix)
)
)
fields_in = [
"ItemID",
"Begin_Station_Num_m",
"End_Station_Num_m",
"TestDate"
]
fields_out = [
"UniqueID",
"Begin",
"End",
"SegmentItems",
"MaxDate"
]
with arcpy.da.InsertCursor(table_out, fields_out) as i_cursor:
for obsv in observations:
# Read table into dictionary with rows as item: (begin, end, date)
where_clause = "UniqueID = {}".format(obsv)
itemsdict = {r[0]:(r[1], r[2], r[3])
for r in arcpy.da.SearchCursor(
table_in,
fields_in,
where_clause
)
}
# Identify segments
allsegments = [s[0] for s in itemsdict.values()] + [s[1] for s in itemsdict.values()]
segments = tuple(sorted(set(allsegments))) ## creates only unique segments
del allsegments
# Identify items and date in each segment
for i in range(len(segments)-1):
begin = segments
end = segments[i + 1]
seg_itemsdict = {k: v[2]
for k, v in itemsdict.items()
if v[0] <= begin and v[1] >= end
}
# Write segment items to output table
itemstext = str(seg_itemsdict.keys()).strip('[]')
maxsegdate = max(seg_itemsdict.values())
row = (obsv, begin, end, itemstext, maxsegdate)
i_cursor.insertRow(row)
if __name__ == '__main__':
main()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Blake, i'll test it and let you know...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Blake, hope you had a good weekend?
I just tested the code and it worked the only thing i noticed is that the process repeats so many times and resulted in huge redundancy (repetition of rows). Is there a way to stop it after the first segmentation?
I will provide a snapshot of the output table
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I counted the number times the repetition happened and the "UniqueID 1104401" occurred 3 times while the "UniqueID 1107700" occurred 48 times.
I also noticed that it is the same data that's written for this number of times mentioned above.
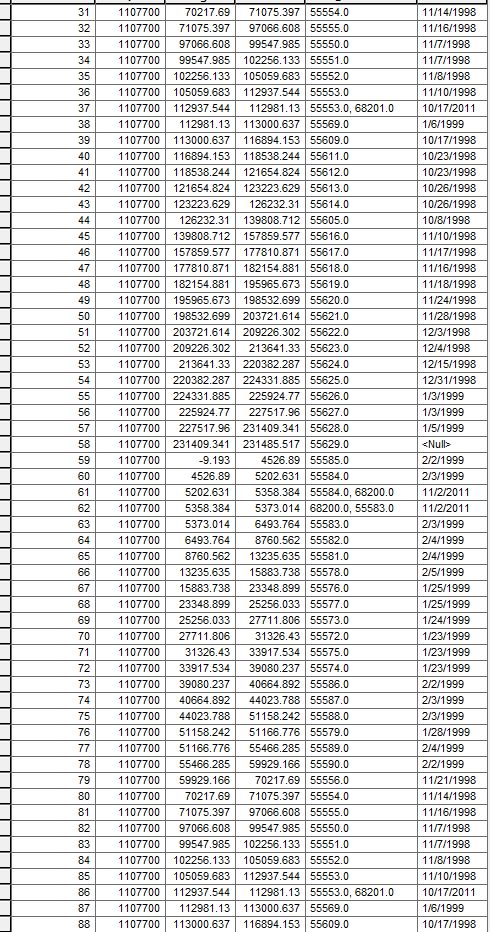
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
the highlighted section shows the repetition
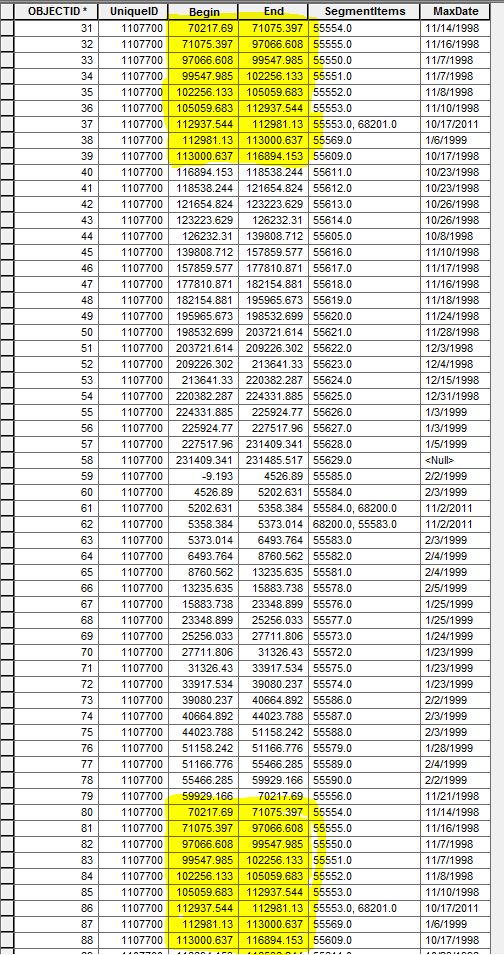
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
thats the link to the
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I just posted the complete table, i tried to use the code on it and i got the error below:

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
That error is because some of your records are missing Date values. My code does not have any error handling and assumes there will always be at least one date.