- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: split text and use parts as variables?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I want to use the numbered parts of this script in the screenshot below as variables. Any suggestions?
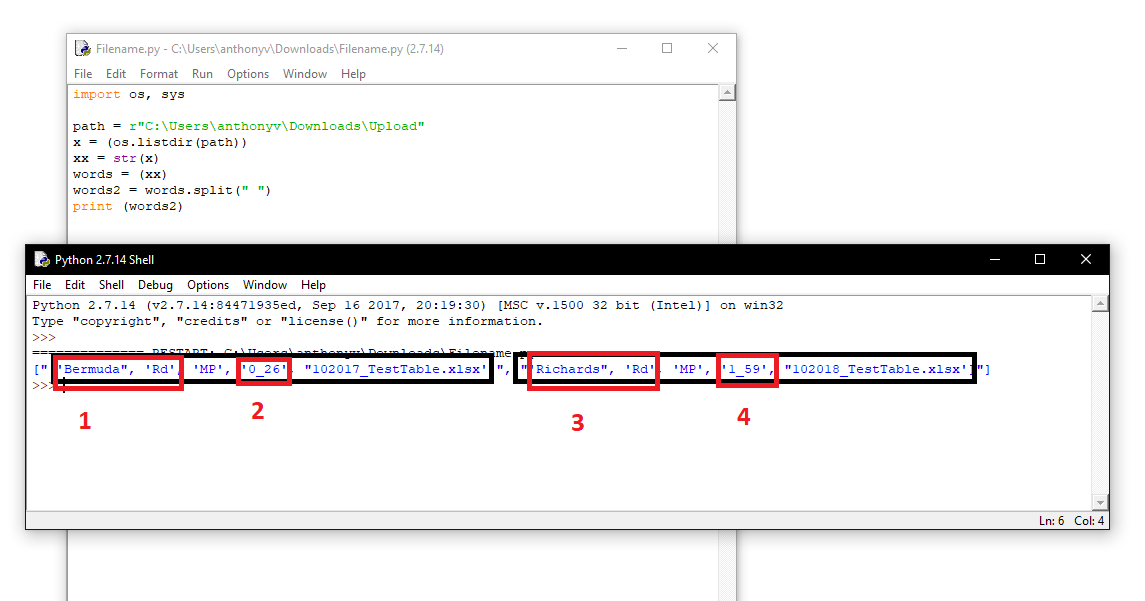
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If the filename format is consistent, you could use a couple of splits:
filename = 'Bermuda Rd MP 0_26 102017_TestTable.xlsx'
f = filename.split(' MP ')
address = f[0]
mile = f[1].split(' ')[0]
print address
# Bermuda Rd
print mile
# 0_26
# and if the underscore in mile represents a decimal point
print '.'.join(mile.split('_'))
# 0.26
# or
mile = '.'.join(f[1].split(' ')[0].split('_'))And using listdir to get filenames in directory:
import os
path = r"C:\Users\anthonyv\Downloads\Upload"
files = os.listdir(path)
for filename in files:
f = filename.split(' MP ')
address = f[0]
# mile = f[1].split(' ')[0] # keep underscore
mile = '.'.join(f[1].split(' ')[0].split('_')) # convert underscore to period
print address, mile- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This is exactly what I was looking for!
-Thanks for your help
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Randy,
The last part of this would be to use address and mile variables for use in creating a excel file. Do you know how I could use the results of the first script in some sort of loop to generate a xlsx document? Below is the script I need to combine it with. The end result would be a column of the address results and a column for the mile results.
import os
os.remove("MetroReportAGOL.xlsx")
print ("Previous Report Deleted")
import os, pandas as pd
# Create a Pandas dataframe from the data.
df = pd.DataFrame({'MP': ["{}".format(mile)],'RdNm': ["{}".format(address)]})
# Create a Pandas Excel writer using XlsxWriter as the engine.
writer = pd.ExcelWriter('MetroReportAGOL.xlsx')
# Convert the dataframe to an XlsxWriter Excel object.
df.to_excel(writer, sheet_name='Sheet1')
# Close the Pandas Excel writer and output the Excel file.
writer.save()
print ("Complete")- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I was able to integrate it into the script above but it's not listing both file names.
import os, sys, pandas as pd
path = r"C:\Users\anthonyv\Downloads\Metro\New folder"
files = os.listdir(path)
for filename in files:
f = filename.split(' MP ')
address = f[0]
mile = '.'.join(f[1].split(' ')[0].split('_')) # convert underscore to period
df = pd.DataFrame({'MP': ["{}".format(mile)],'RdNm': ["{}".format(address)]})
writer = pd.ExcelWriter('MetroReportAGOL.xlsx')
df.to_excel(writer, sheet_name='Sheet1')
writer.save()
print ("Complete")
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »