- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Select and Create New Layer in SearchCursor
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a Python script I created after my ModelBuilder model got too clunky and slow, but I'm stuck. I have a point shapefile that I want to buffer then run Zonal Statistics on that buffered point. Following that, I need to run raster calculator, int, and raster to polygon geoprocessing tools so the value output by the Zonal Statistics tool can be copied to another shapefile. There is also another attribute that needs to persist throughout.
I've been having trouble with SearchCursor; it isn't iterating. It uses all the features in the input shapefile rather than the one it's on. So, I decided to try selecting the row it's on and exporting to a new shapefile, but I don't know how to include row[] in the SQL expression (I know the one in the code is incorrect).
I'd appreciate any help--please be kind, though! I'm learning!
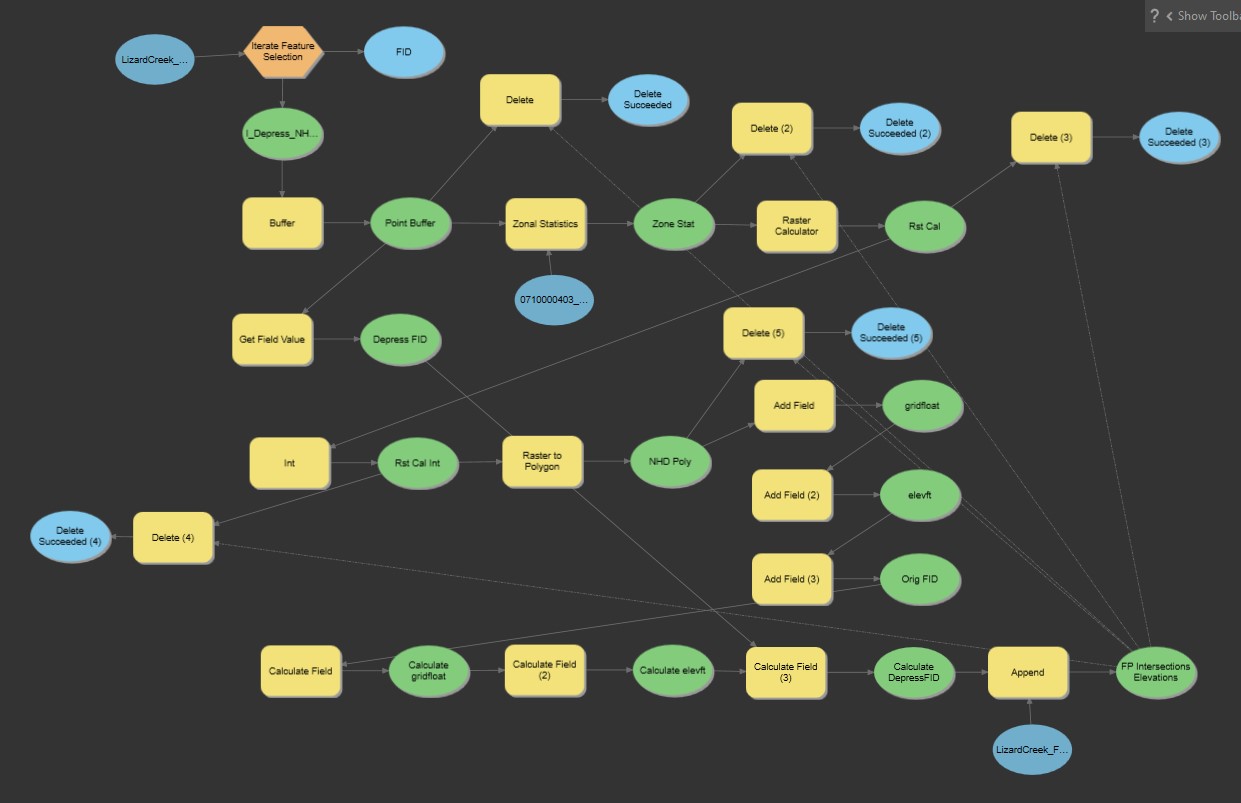
I've also included a screen shot of my model that works in ModelBuilder, in case that helps.
import sys
import arcpy
from arcpy.sa import *
import math
import os
arcpy.env.overwriteOutput = False
# Check out any necessary licenses.
arcpy.CheckOutExtension("spatial")
arcpy.CheckOutExtension("ImageAnalyst")
arcpy.CheckOutExtension("3D")
# Model Environment settings
Depression_NHD_Intersect_Layer = "D:\\Projects\\TESTING_Depression_NHD_Intersect.shp"
AOI_Raster = "D:\\Projects\\0710000404_DeerCreekDesMoinesRiver.tif"
HUC10_RSTFile_Path = "D:\\Projects\\RSTFiles\\"
HUC10_SHPFile_Path = "D:\\Projects\\SHPFiles\\"
Point_Buffer_Output = HUC10_SHPFile_Path + "Buffer.shp"
fields = ['FID', 'DepressFID']
#Create Empty Feature Class
FP_Intersections_Elev = arcpy.management.CreateFeatureclass(HUC10_SHPFile_Path, "FP_Intersections_Elev_TEST.shp", "POLYGON", "D:\\Projects\\FP_Intersections_Elev_TEMPLATE.shp", "DISABLED", "DISABLED", "D:\\Projects\\FP_Intersections_Elev_TEMPLATE.shp")
#Buffer
arcpy.Buffer_analysis(Depression_NHD_Intersect_Layer, Point_Buffer_Output, "3 Meters", "" , "" , "NONE", "" , "PLANAR")
with arcpy.da.SearchCursor(Point_Buffer_Output, fields) as cursor:
for row in cursor:
Make_Feature_Layer = HUC10_SHPFile_Path + str(row[1]) + '.shp'
Single_Buffer_Layer = HUC10_SHPFile_Path + "DepressFID_" + str(row[1]) + '.shp'
Zonal_Stats_Output = HUC10_RSTFile_Path + "ZoneStats_" + str(row[1]) + '.tif'
Raster_Calc_Output = HUC10_RSTFile_Path + "RasterCalc_" + str(row[1]) + '.tif'
Int_Output = HUC10_RSTFile_Path + "Int_" + str(row[1]) + '.tif'
Raster_to_Poly_Output = HUC10_SHPFile_Path + "NHD_Poly_" + str(row[1]) + '.shp'
sql = '"FID" = \'(row[0])\''
#Make Feature Layer
arcpy.Select_analysis(Point_Buffer_Output, Single_Buffer_Layer, sql)
#Zonal Statistics
outZonalStats = ZonalStatistics(Single_Buffer_Layer, "DepressFID", AOI_Raster, "MEAN")
outZonalStats.save(Zonal_Stats_Output)
#Raster Calculator to prepare to change value to integer
outRasCal = RasterCalculator([Zonal_Stats_Output], ["x"], "x*1000000")
outRasCal.save(Raster_Calc_Output)
#Int (integer) Raster
outInt = Int(Raster_Calc_Output)
outInt.save(Int_Output)
#Raster to Polygon
arcpy.conversion.RasterToPolygon(Int_Output, Raster_to_Poly_Output, "NO_SIMPLIFY", "VALUE")
#Add Fields to Polygon Layer
arcpy.management.AddField(Raster_to_Poly_Output, "DepressFID", "LONG")
arcpy.management.AddField(Raster_to_Poly_Output, "gridfloat", "FLOAT")
arcpy.management.AddField(Raster_to_Poly_Output, "elevft", "FLOAT")
#Calculate New Fields
arcpy.management.CalculateField(Raster_to_Poly_Output, "DepressFID", row[1])
arcpy.management.CalculateField(Raster_to_Poly_Output, "gridfloat", "!gridcode!/1000000", "PYTHON3")
arcpy.management.CalculateField(Raster_to_Poly_Output, "elevft", "!gridfloat!*3.2808", "PYTHON3")
#Append shapefile to FP_Intersections_Elev shapefile
arcpy.management.Append(Raster_to_Poly_Output, FP_Intersections_Elev, "TEST", "" , "" , "" , "" , "NOT_UPDATE_GEOMETRY")
#Delete Intermediate Files
arcpy.management.Delete(Zonal_Stats_Output)
arcpy.management.Delete(Raster_Calc_Output)
arcpy.management.Delete(Int_Output)
arcpy.management.Delete(Raster_to_Poly_Output)
print("Completed DepressFID: " + str(row[1]))
print("All DepressFIDs Completed!")
Solved! Go to Solution.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Very helpful!
I thought nesting meant what you explained and I thought that's what was happening in the revised script. But it ended, so it's not considered nested anymore. Woohoo!
As for your question: I'm not sure what was meant here; this was the part in the revised script where everyone was talking about loading all the data into memory first, so I thought I'd try it. Obviously it didn't work...
Thanks, all. Appreciate the help!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
with arcpy.da.SearchCursor(Point_Buffer_Output, fields) as cursor:
rows = [row for row in rows_to_dict(cursor)]
for row in rows_to_dict(cursor):Sorry for being a bit confusing here, I included the other line as an alternative, so your two options would be
with arcpy.da.SearchCursor(Point_Buffer_Output, fields) as cursor:
rows = [row for row in rows_to_dict(cursor)]
for row in rows:Or
with arcpy.da.SearchCursor(Point_Buffer_Output, fields) as cursor:
for row in rows_to_dict(cursor):With the first option building a list of all rows in memory and the second using something called a generator that only returns the next() row on each iteration. Which is good if you have a huge dataset that will fill up your ram. I usually use the second option with no issues, but included the first option in response to @VinceAngelo's comments.
I also wasn't able to test this code after I wrote it, so sorry if I typoed any of the paths, but the general structure of using r strings for hardcoded basepaths and os.path.join for all generated paths.
You also have the option of using the tempfile module instead of writing files to explicit temp directories and then cleaning up. This will put the temporary shapes in the tempfolder that your ArcPro/ArcMap instance is currently linked to.
The reason you don't want to nest cursors that are searching and inserting at the same time is because the rows you're searching might be modified as you're traversing them. You also don't really need to nest SearchCursors because of that. You can just load the rows into memory and iterate over the derived data (in this case a list of dictionaries that looks like [{'Field1', <value>}, {'Field2', <value>}] ). This also means you can pre-process data and prevent too many cursors from being active at the same time.
A good way to check this (if you're using ArcPro) is to open the Diagnostic Monitor under the Help ribbon and taking a look at how many cursors your script calls. If you nest them, you'll have one active cursor per feature in the outer cursor, while pre-building the data only creates one cursor per featureclass.
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »