- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Select and Create New Layer in SearchCursor
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a Python script I created after my ModelBuilder model got too clunky and slow, but I'm stuck. I have a point shapefile that I want to buffer then run Zonal Statistics on that buffered point. Following that, I need to run raster calculator, int, and raster to polygon geoprocessing tools so the value output by the Zonal Statistics tool can be copied to another shapefile. There is also another attribute that needs to persist throughout.
I've been having trouble with SearchCursor; it isn't iterating. It uses all the features in the input shapefile rather than the one it's on. So, I decided to try selecting the row it's on and exporting to a new shapefile, but I don't know how to include row[] in the SQL expression (I know the one in the code is incorrect).
I'd appreciate any help--please be kind, though! I'm learning!
I've also included a screen shot of my model that works in ModelBuilder, in case that helps.
import sys
import arcpy
from arcpy.sa import *
import math
import os
arcpy.env.overwriteOutput = False
# Check out any necessary licenses.
arcpy.CheckOutExtension("spatial")
arcpy.CheckOutExtension("ImageAnalyst")
arcpy.CheckOutExtension("3D")
# Model Environment settings
Depression_NHD_Intersect_Layer = "D:\\Projects\\TESTING_Depression_NHD_Intersect.shp"
AOI_Raster = "D:\\Projects\\0710000404_DeerCreekDesMoinesRiver.tif"
HUC10_RSTFile_Path = "D:\\Projects\\RSTFiles\\"
HUC10_SHPFile_Path = "D:\\Projects\\SHPFiles\\"
Point_Buffer_Output = HUC10_SHPFile_Path + "Buffer.shp"
fields = ['FID', 'DepressFID']
#Create Empty Feature Class
FP_Intersections_Elev = arcpy.management.CreateFeatureclass(HUC10_SHPFile_Path, "FP_Intersections_Elev_TEST.shp", "POLYGON", "D:\\Projects\\FP_Intersections_Elev_TEMPLATE.shp", "DISABLED", "DISABLED", "D:\\Projects\\FP_Intersections_Elev_TEMPLATE.shp")
#Buffer
arcpy.Buffer_analysis(Depression_NHD_Intersect_Layer, Point_Buffer_Output, "3 Meters", "" , "" , "NONE", "" , "PLANAR")
with arcpy.da.SearchCursor(Point_Buffer_Output, fields) as cursor:
for row in cursor:
Make_Feature_Layer = HUC10_SHPFile_Path + str(row[1]) + '.shp'
Single_Buffer_Layer = HUC10_SHPFile_Path + "DepressFID_" + str(row[1]) + '.shp'
Zonal_Stats_Output = HUC10_RSTFile_Path + "ZoneStats_" + str(row[1]) + '.tif'
Raster_Calc_Output = HUC10_RSTFile_Path + "RasterCalc_" + str(row[1]) + '.tif'
Int_Output = HUC10_RSTFile_Path + "Int_" + str(row[1]) + '.tif'
Raster_to_Poly_Output = HUC10_SHPFile_Path + "NHD_Poly_" + str(row[1]) + '.shp'
sql = '"FID" = \'(row[0])\''
#Make Feature Layer
arcpy.Select_analysis(Point_Buffer_Output, Single_Buffer_Layer, sql)
#Zonal Statistics
outZonalStats = ZonalStatistics(Single_Buffer_Layer, "DepressFID", AOI_Raster, "MEAN")
outZonalStats.save(Zonal_Stats_Output)
#Raster Calculator to prepare to change value to integer
outRasCal = RasterCalculator([Zonal_Stats_Output], ["x"], "x*1000000")
outRasCal.save(Raster_Calc_Output)
#Int (integer) Raster
outInt = Int(Raster_Calc_Output)
outInt.save(Int_Output)
#Raster to Polygon
arcpy.conversion.RasterToPolygon(Int_Output, Raster_to_Poly_Output, "NO_SIMPLIFY", "VALUE")
#Add Fields to Polygon Layer
arcpy.management.AddField(Raster_to_Poly_Output, "DepressFID", "LONG")
arcpy.management.AddField(Raster_to_Poly_Output, "gridfloat", "FLOAT")
arcpy.management.AddField(Raster_to_Poly_Output, "elevft", "FLOAT")
#Calculate New Fields
arcpy.management.CalculateField(Raster_to_Poly_Output, "DepressFID", row[1])
arcpy.management.CalculateField(Raster_to_Poly_Output, "gridfloat", "!gridcode!/1000000", "PYTHON3")
arcpy.management.CalculateField(Raster_to_Poly_Output, "elevft", "!gridfloat!*3.2808", "PYTHON3")
#Append shapefile to FP_Intersections_Elev shapefile
arcpy.management.Append(Raster_to_Poly_Output, FP_Intersections_Elev, "TEST", "" , "" , "" , "" , "NOT_UPDATE_GEOMETRY")
#Delete Intermediate Files
arcpy.management.Delete(Zonal_Stats_Output)
arcpy.management.Delete(Raster_Calc_Output)
arcpy.management.Delete(Int_Output)
arcpy.management.Delete(Raster_to_Poly_Output)
print("Completed DepressFID: " + str(row[1]))
print("All DepressFIDs Completed!")
Solved! Go to Solution.
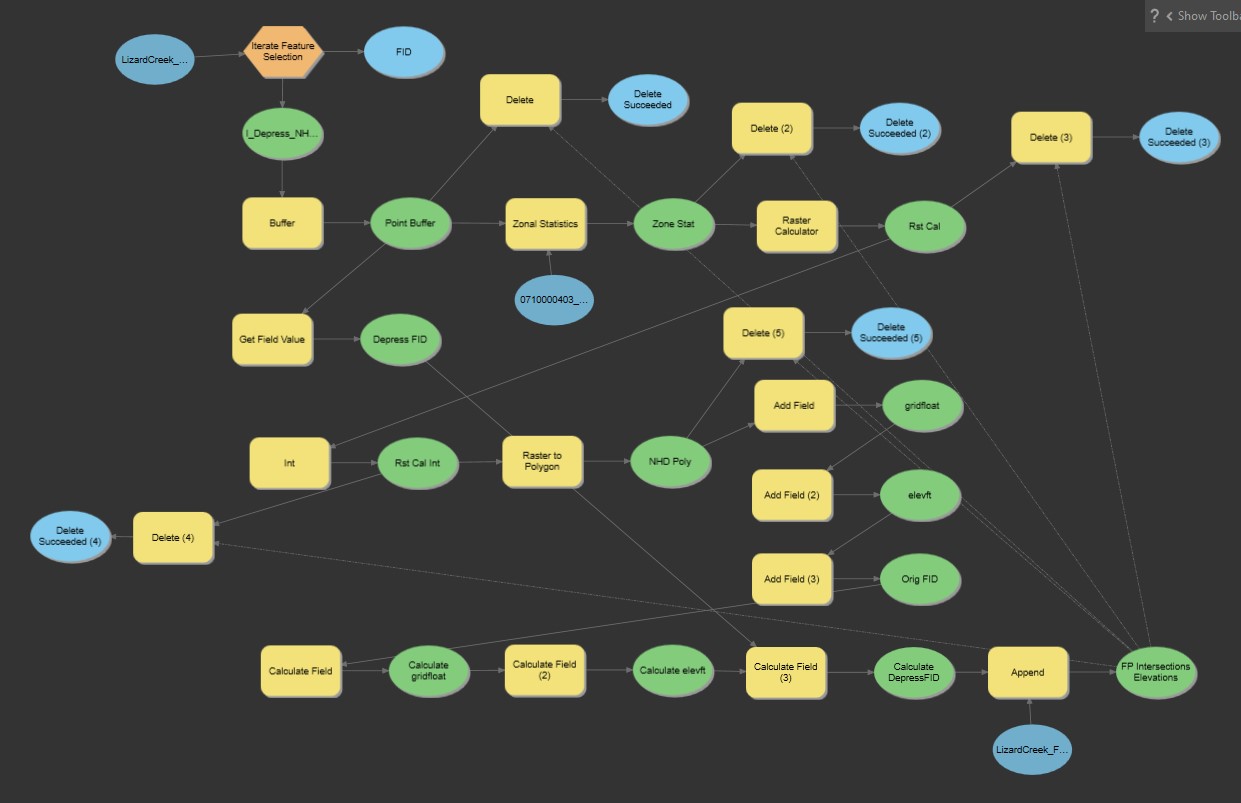{kind=link}
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So, two things I notice at first glance.
In line 31, you make the "Make_Feature_Layer" variable, but never do anything with.
The other thing is that in line 40 you make a whole new shapefile, not a layer like you say. It may be more efficient to do a select by attribute, then use that selection as a input in other things.
Single_Buffer_Layer = aarcpy.management.SelectLayerByAttribute(featureclass, where_clause= sql)
Also, your sql clause is going to be read by the computer as find everything where FID is equal to the text "(row[0])".
Several ways to take care of it, but the one I prefer is using an f-string, which will pop in the values in the brackets (see string.format() for alternate syntax)
sql = f'FID = {row[0]}'This sql shoooould work? If it fails, I'd try adding quotes to "FID".
If you need to cast row[0] to a different data type (string, int, etc.) do it within the brackets, but I don't think it'll be necessary.
sql = f'FID = {str(row[0])}'
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So, two things I notice at first glance.
In line 31, you make the "Make_Feature_Layer" variable, but never do anything with.
The other thing is that in line 40 you make a whole new shapefile, not a layer like you say. It may be more efficient to do a select by attribute, then use that selection as a input in other things.
Single_Buffer_Layer = aarcpy.management.SelectLayerByAttribute(featureclass, where_clause= sql)
Also, your sql clause is going to be read by the computer as find everything where FID is equal to the text "(row[0])".
Several ways to take care of it, but the one I prefer is using an f-string, which will pop in the values in the brackets (see string.format() for alternate syntax)
sql = f'FID = {row[0]}'This sql shoooould work? If it fails, I'd try adding quotes to "FID".
If you need to cast row[0] to a different data type (string, int, etc.) do it within the brackets, but I don't think it'll be necessary.
sql = f'FID = {str(row[0])}'
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
@AlfredBaldenweckf strings are definitely the way to go, and any string operations you ever use in a python 3 environment should use them because of how python has immutable strings (f strings build a single string like the .format() method while str + str creates 3 string objects in memory).
For your second sql, I don't think that casting the row to a string in python will fix the sql if the field is text, because SQL expects a ' delimiter in the actual query string.
So the better solutions would be:
# Use this if your FID is a string/text field
# the '' around the value is so SQL knows it's a string
sql = f"FID = '{row['FID']}'"
# Use this if your FID is a number field
# Not using '' around the value since it's a number
sql2 = f"FID = {row['FID']}"
I've also re-worked the rest of the script to use f strings and os path joins for better maintainability and readability:
import sys
import arcpy
from arcpy.sa import *
import math
import os
def row_to_dict(cursor:arcpy.da.SearchCursor) -> dict():
"""Converts a row from an arcpy.da.SearchCursor into a dictionary with field names as keys"""
for row in cursor:
yield dict(zip(cursor.fields, row))
arcpy.env.overwriteOutput = False
# Check out any necessary licenses.
arcpy.CheckOutExtension("spatial")
arcpy.CheckOutExtension("ImageAnalyst")
arcpy.CheckOutExtension("3D")
# Model Environment settings
Depression_NHD_Intersect_Layer = r"D:\Projects\TESTING_Depression_NHD_Intersect.shp"
AOI_Raster = r"D:\Projects\0710000404_DeerCreekDesMoinesRiver.tif"
HUC10_RSTFile_Path = r"D:\Projects\RSTFiles"
HUC10_SHPFile_Path = r"D:\Projects\SHPFiles"
Point_Buffer_Output = os.path.join(HUC10_SHPFile_Path, "Buffer.shp")
fields = ['FID', 'DepressFID']
#Create Empty Feature Class
FP_Intersections_Elev = arcpy.CreateFeatureclass_management(
out_path = HUC10_SHPFile_Path,
out_name = "FP_Intersections_Elev_TEST.shp",
geometry_type = "POLYGON",
template = r"D:\Projects\FP_Intersections_Elev_TEMPLATE.shp", )
#Buffer
arcpy.Buffer_analysis(
in_features = Depression_NHD_Intersect_Layer,
out_feature_class = Point_Buffer_Output,
buffer_distance_or_field = "3 Meters",
method = "PLANAR")
with arcpy.da.SearchCursor(Point_Buffer_Output, fields) as cursor:
for row in row_to_dict(cursor):
Make_Feature_Layer = os.path.join(HUC10_SHPFile_Path, f"{str(row['DepressFID'])}.shp")
Single_Buffer_Layer = os.path.join(HUC10_SHPFile_Path, f"DepressFID_{str(row['DepressFID'])}.shp")
Zonal_Stats_Output = os.path.join(HUC10_RSTFile_Path, f"ZoneStats_{str(row['DepressFID'])}.tif")
Raster_Calc_Output = os.path.join(HUC10_RSTFile_Path, f"RasterCalc_{str(row['DepressFID'])}.tif")
Int_Output = os.path.join(HUC10_RSTFile_Path, f"Int_{str(row['DepressFID'])}.tif")
Raster_to_Poly_Output = os.path.join(HUC10_SHPFile_Path, f"NHD_Poly_{str(row['DepressFID'])}.shp")
# Use this if your FID is a string/text field
# the '' around the value is so SQL knows it's a string
sql = f"FID = '{row['FID']}'"
# Use this if your FID is a number field
# Not using '' around the value since it's a number
sql2 = f"FID = {row['FID']}"
#Make Feature Layer
arcpy.Select_analysis(Point_Buffer_Output, Single_Buffer_Layer, sql)
#Zonal Statistics
outZonalStats = ZonalStatistics(Single_Buffer_Layer, "DepressFID", AOI_Raster, "MEAN")
outZonalStats.save(Zonal_Stats_Output)
#Raster Calculator to prepare to change value to integer
outRasCal = RasterCalculator([Zonal_Stats_Output], ["x"], "x*1000000")
outRasCal.save(Raster_Calc_Output)
#Int (integer) Raster
outInt = Int(Raster_Calc_Output)
outInt.save(Int_Output)
#Raster to Polygon
arcpy.RasterToPolygon_conversion(Int_Output, Raster_to_Poly_Output, "NO_SIMPLIFY", "VALUE")
#Add Fields to Polygon Layer
arcpy.AddField_management(Raster_to_Poly_Output, "DepressFID", "LONG")
arcpy.AddField_management(Raster_to_Poly_Output, "gridfloat", "FLOAT")
arcpy.AddField_management(Raster_to_Poly_Output, "elevft", "FLOAT")
#Calculate New Fields
arcpy.CalculateField_management(Raster_to_Poly_Output, "DepressFID", row['DepressFID'])
arcpy.CalculateField_management(Raster_to_Poly_Output, "gridfloat", "!gridcode!/1000000", "PYTHON3")
arcpy.CalculateField_management(Raster_to_Poly_Output, "elevft", "!gridfloat!*3.2808", "PYTHON3")
#Append shapefile to FP_Intersections_Elev shapefile
arcpy.Append_management(Raster_to_Poly_Output, FP_Intersections_Elev, "TEST", "" , "" , "" , "" , "NOT_UPDATE_GEOMETRY")
#Delete Intermediate Files
arcpy.Delete_management(Zonal_Stats_Output)
arcpy.Delete_management(Raster_Calc_Output)
arcpy.Delete_management(Int_Output)
arcpy.Delete_management(Raster_to_Poly_Output)
print(f"Completed DepressFID: {str(row['DepressFID'])}")
print("All DepressFIDs Completed!")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I rewrote some of your operations to use cursors a bit more clearly. Hopefully looking at how I did it will help you understand how to use arcpy cursors better. They're really powerful and much faster than most other arcpy operations that involve processing data.
import sys
import arcpy
from arcpy.sa import *
import math
import os
# Useful function for working with cursor objects
def row_to_dict(cursor:arcpy.da.SearchCursor) -> dict():
"""Converts a row from an arcpy.da.SearchCursor into a
dictionary with field names as keys
@cursor: an arcpy.da.Cursor object
@returns: a dictionary with field names as keys and row values as values
"""
for row in cursor:
yield dict(zip(cursor.fields, row))
arcpy.env.overwriteOutput = False
# Check out any necessary licenses.
arcpy.CheckOutExtension("spatial")
arcpy.CheckOutExtension("ImageAnalyst")
arcpy.CheckOutExtension("3D")
# Model Environment settings
Depression_NHD_Intersect_Layer = r"D:\Projects\TESTING_Depression_NHD_Intersect.shp"
AOI_Raster = r"D:\Projects\0710000404_DeerCreekDesMoinesRiver.tif"
HUC10_RSTFile_Path = r"D:\Projects\RSTFiles"
HUC10_SHPFile_Path = r"D:\Projects\SHPFiles"
Point_Buffer_Output = os.path.join(HUC10_SHPFile_Path, "Buffer.shp")
fields = ['FID', 'DepressFID']
#Create Empty Feature Class
FP_Intersections_Elev = arcpy.CreateFeatureclass_management(
out_path = HUC10_SHPFile_Path,
out_name = "FP_Intersections_Elev_TEST.shp",
geometry_type = "POLYGON",
template = r"D:\Projects\FP_Intersections_Elev_TEMPLATE.shp", )
#Buffer
arcpy.Buffer_analysis(
in_features = Depression_NHD_Intersect_Layer,
out_feature_class = Point_Buffer_Output,
buffer_distance_or_field = "3 Meters",
method = "PLANAR")
with arcpy.da.SearchCursor(Point_Buffer_Output, fields) as cursor:
# Use this if you want to load the whole dataset into memory
# change the row_to_dict(cursor) token to rows and uncomment the
# line below
# rows = [row for row in row_to_dict(cursor)]
for row in row_to_dict(cursor):
Make_Feature_Layer = os.path.join(HUC10_SHPFile_Path,
f"{row['DepressFID']}.shp")
Single_Buffer_Layer = os.path.join(HUC10_SHPFile_Path,
f"DepressFID_{row['DepressFID']}.shp")
Zonal_Stats_Output = os.path.join(HUC10_RSTFile_Path,
f"ZoneStats_{row['DepressFID']}.tif")
Raster_Calc_Output = os.path.join(HUC10_RSTFile_Path,
f"RasterCalc_{row['DepressFID']}.tif")
Int_Output = os.path.join(HUC10_RSTFile_Path,
f"Int_{row['DepressFID']}.tif")
Raster_to_Poly_Output = os.path.join(HUC10_SHPFile_Path,
f"NHD_Poly_{row['DepressFID']}.shp")
# Use this if your FID is a string/text field
# the '' around the value is so SQL knows it's a string
sql = f"FID = '{row['FID']}'"
# Use this if your FID is a number field
# Not using '' around the value since it's a number
sql2 = f"FID = {row['FID']}"
#Make Feature Layer
arcpy.Select_analysis(Point_Buffer_Output, Single_Buffer_Layer, sql)
#Zonal Statistics
outZonalStats = ZonalStatistics(
Single_Buffer_Layer,
"DepressFID",
AOI_Raster,
"MEAN")
outZonalStats.save(Zonal_Stats_Output)
#Raster Calculator to prepare to change value to integer
outRasCal = RasterCalculator([Zonal_Stats_Output], ["x"], "x*1000000")
outRasCal.save(Raster_Calc_Output)
# Delete the intermediate file after use
arcpy.Delete_management(Zonal_Stats_Output)
#Int (integer) Raster
outInt = Int(Raster_Calc_Output)
outInt.save(Int_Output)
# Delete the intermediate file after use
arcpy.Delete_management(Raster_Calc_Output)
#Raster to Polygon
arcpy.RasterToPolygon_conversion(
Int_Output,
Raster_to_Poly_Output,
"NO_SIMPLIFY",
"VALUE")
# Delete the intermediate file after use
arcpy.Delete_management(Int_Output)
#Add Fields to Polygon Layer (Use a dictionary so you can add more
#fields later if needed without changing the code)
new_fields = {
"DepressFID": "LONG",
"gridfloat": "FLOAT",
"elevft": "FLOAT"
}
for fld_name, fld_type in new_fields.items():
arcpy.AddField_management(Raster_to_Poly_Output, fld_name, fld_type)
# Use a Search Cursor to get the values from the Raster to
# Polygon output and modify them before inserting
new_rows = []
r2p_fields = ["SHAPE@", "gridcode"].extend(new_fields.keys())
with arcpy.da.SearchCursor(Raster_to_Poly_Output, r2p_fields) as r2p_cursor:
for r2p_row in row_to_dict(r2p_cursor):
r2p_row['DepressFID'] = row['DepressFID']
row['gridfloat'] = row['gridcode']/1000000
row['elevft'] = row['gridfloat']*3.2808
new_rows.append(r2p_row)
# Delete intermediate output after getting the values
arcpy.Delete_management(Raster_to_Poly_Output)
# Use an insert cursor for this operation instead of Append
with arcpy.da.Editor(HUC10_SHPFile_Path) as edit:
with arcpy.da.InsertCursor(FP_Intersections_Elev, r2p_fields) as in_cur:
for fp_row in new_rows:
in_cur.insertRow(fp_row)
print(f"Completed DepressFID: {row['DepressFID']}")
print("All DepressFIDs Completed!")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Looping on a data source that you are also running selection operations is always going to cause grief. I'd suggest you make an array or a dictionary from the search cursor, then loop on the array/dictionary contents (as Hayden has done). While it is true that selections run against layers, not sources, playing fast with both at the same time is just trouble.
- V
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I was originally going to build a list of row dictionaries in memory and iterate through that, but I didn't know how many features that would be in the dataset, so I kept everything inside the cursor loop using a generator on the rows.
I'm guessing that the building a generator from the cursor object is still better than iterating directly on the cursor rows?
My current solution is meant to be memory efficient, but if running selection operations while iterating through rows in a search cursor is a bad idea, maybe it would be best to build out that list of row dicts before iterating through it.
edit: I've added a line to the above code that loads the whole table into memory before iteration with instructions on how to switch to that if using a generator on the search cursor isn't good enough to prevent grief.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I've been 64-bit Python for a while now, so I'll admit to getting complacent about caching 6-12GiB of data in an app to write 60 million complex features in a few minutes. And that was ~10 years back, when 27GiB was a large VM.
My rule of thumb is to avoid nesting cursors. Cache with SearchCursor and then Insert or Update. Ba-da-bing, ba-da-boom.
Generators are a wonderful trick for managing a non-cursor stream, but I worry about interaction with the underlying object via ArcObjects if selection sets and schema modifications are at play.
- V
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
That's usually how I play it, I never nest insert and update cursors. Nesting search cursors using list comps or generators has worked well for me so far, but I'll definitely start caching searches in the future. Even if I'm running searches inside an update, just caching the search at the beginning of each update loop should help prevent any issues because it limits database queries.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I can't thank you all enough for your insights!
@HaydenWelch , your edits all make sense. However, when I tried to implement the edits, there were a couple of issues. There was an "EOL: String literal" error after the HUC10_RSTFile_Path after I changed the path to include the "r" at the beginning and removed the duplicate "\" in the path. I reverted back to the original path, which worked. Any idea why this might have errored? Also, why is the "r" solution better?
I really like the "loading whole dataset into memory" idea, although the dataset size isn't as large as what you're working with, so it's not extremely necessary. However, I did try to implement it because, why not? There was an error saying that "row" wasn't defined. I thought I had it straight, but I guess I didn't. Here's what I inserted:
with arcpy.da.SearchCursor(Point_Buffer_Output, fields) as cursor:
rows = [row for row in rows_to_dict(cursor)]
for row in rows_to_dict(cursor): So, I just wrote it singularly (the whole dataset wasn't loaded into memory).
Lastly, the Append didn't work. The fields were added but no shapes/data were appended to the feature class.
So, to "fix" my script, I modified the sql expression as @AlfredBaldenweck mentioned. It's running now. However, based on all of the feedback, I know it's not clear/efficient/"good" Python, so I'm interested in your thoughts on my questions above. And last question: in the dialogue between @HaydenWelch and @VinceAngelo , you guys talk about not nesting insert and update cursors. But isn't that what was implemented in my script you modified (lines beginning 115 and 129)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So, what r"string" does is tells the computer to read the string exactly as is. Normally a backslash \ is an escape character; it tells the computer to treat the following character as its literal meaning, or (more accurately?) it tells it to ignore the following character. So, for example, if you wanted to have double quotes in a string defined by double quotes, you'd use a backslash.
"The farmer said \"Hello\"."
Or, you can use them to escape other backslashes
Documents\\Example
This is also why you use double backslash without the the r"string"; the computer will read "Documents\Example" as "Documentsxample".
However, if you switched to using r"string", you have to account for the fact that there are now two backslashes where there should be one. Documents\\Example\\test.doc doesn't exist, but Documents\Example\text.doc does.
@HaydenWelch 's use of os.path.join on your file paths is the way to go, particularly to avoid ending a string with the backslash. os.path.join() will supply the appropriate backslashes as needed.
HUC10_RSTFile_Path = r"D:\Projects\RSTFiles"
HUC10_RSTFile_Path = os.path.join(HUC10_RSTFile_Path, something, something, .tif)
#instead of
HUC10_RSTFile_Path = "D:\\Projects\\RSTFiles\\"
More to the point, though:
I'm a little confused as to what you're doing with that snippet you just shared. Why are you running the cursor twice? Wouldn't it be easier to just circle through rows?
with arcpy.da.SearchCursor(Point_Buffer_Output, fields) as cursor:
rows = [row for row in rows_to_dict(cursor)]
for row in rows:
Nesting a cursor means running a cursor inside another.
with arcpy.da.SearchCursor(fc, [fields]) as cursor:
for row in cursor:
with arcpy.da.UpdateCursor(fc2, [fields2]) as c2rsor:
#code
What they did is run the search cursor, let it end, then open the update cursor. (The update cursor is inside an edit session, which is why it's indented extra).
Not sure on the not-adding geometry thing.