- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Script for simultaneous looping and dissolve
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Script for simultaneous looping and dissolve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
In the table attached you can see the destination cities in 'Destination' field. Many of them are same - Werne Werne Werne.......
I want to create a script/model such that when run, it loops through all the rows with the same destination city (all the rows that have Werne for example) and then out of them selects the row that has the maximum value in the 'Commuters' field and then dissolves the destination city with the origin city ('Origin' field) for that row.
For example for Werne the row with the maximum value in the commuter field is the first row. So the tool should identify that and then dissolve Werne with Bergkamen in the map.
And then this should be done for every destination city. So basically the looping must happen only until the rows with same destination cities. Then after dissolving that city with its origin city a new loop should be created for the next destination city in the 'Destination' field.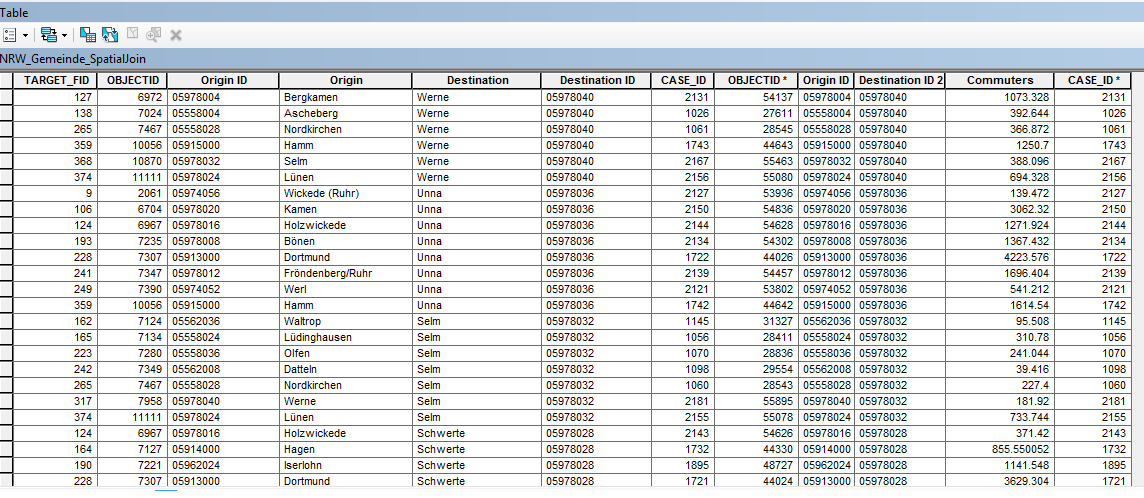
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
OK, I created some code that seems to yield the correct result, but it is pretty ugly and unreadable... The result look like this (thick black lines):
... and the attribute lists the Gemeindes that were used to create the merged polygons.
I have attached the resulting shapefile, so you can have a look and check the result.
The code used to create the output is listed below:
def main():
import arcpy
arcpy.env.overwriteOutput = True
# input fc
fc = r"C:\Forum\Gemeinde\NRW_Gemeinde_SpatiaJoin.shp"
fld_from = "GEN"
fld_to = "GEN_1"
fld_val = "Value"
# output field (will be added to input fc)
fld_out = "Gemeindes"
# output fc
fc_out = r"C:\Forum\Gemeinde\NRW_Gemeinde_diss01.shp"
# detemine the max commutors per from gemeinde
dct_max = {}
with arcpy.da.SearchCursor(fc, (fld_from, fld_to, fld_val)) as curs:
for row in curs:
from_g = row[0]
to_g = row[1]
val = row[2]
# check that from_Gemeinde is not equal to to_Gemeinde
if from_g != to_g:
if from_g in dct_max:
# check if value is higher
tpl = dct_max[from_g]
max_to_g = tpl[0]
max_val = tpl[1]
if val > max_val:
# update entry in dct
dct_max[from_g] = (to_g, val)
else:
# insert value
dct_max[from_g] = (to_g, val)
lst_init = []
for from_g, v in sorted(dct_max.items()):
to_g = v[0]
merged = False
for i in range(0, len(lst_init)):
lst = lst_init
if from_g in lst or to_g in lst:
# merge
lst.extend([from_g, to_g])
lst_init = lst
merged = True
if merged == False:
lst_init.append([from_g, to_g])
lst_init = [list(set(lst)) for lst in lst_init]
lst_all = []
for lst in lst_init:
for a in lst:
lst_all.append(a)
lst_all = list(set(lst_all))
dct = {}
for a in lst_all:
lst_ids = []
for i in range(0, len(lst_init)):
lst = lst_init
if a in lst:
lst_ids.append(i)
dct=lst_ids
lst_res = []
for gem, lst_ids in sorted(dct.items()):
# print gem, lst_ids
lst_ids2 = lst_ids
for ids in lst_ids:
lst = lst_init[ids]
for gem2 in lst:
ids = dct[gem2]
lst_ids2.extend(ids)
lst_ids2 = list(set(lst_ids2))
lst_res.append(lst_ids2)
lst_res = sorted(lst_res)
lst_res2 = []
res = []
for i in range(0, len(lst_res)):
prev_res = res
res = sorted(lst_res)
if res != prev_res:
lst_res2.append(res)
for i in range(len(lst_res2)-1, -1, -1):
res = lst_res2
for j in range(0, i+1):
res2 = lst_res2 = sorted(list(set(res)))
if i <> j:
lst_res2.pop(i)
lst_missing = []
for i in range(0, len(lst_init)):
bln_found = False
for lst in lst_res2:
if i in lst:
bln_found = True
break
if bln_found == False:
lst_missing.append(i)
lst_res2.append(lst_missing)
lst_fin = []
for res in sorted(lst_res2):
lst_elem = []
for ids in res:
lst_gem = lst_init[ids]
lst_elem.extend(lst_gem)
lst_fin.append(list(set(lst_elem)))
dct_fin = {}
for fin in lst_fin:
for g in fin:
dct_fin = ",".join(fin)
if len(arcpy.ListFields(fc, wild_card=fld_out)) == 0:
arcpy.AddField_management(in_table=fc, field_name=fld_out, field_type="TEXT", field_length=255)
flds = (fld_from, fld_out)
with arcpy.da.UpdateCursor(fc, flds) as curs:
for row in curs:
gem = row[0]
if gem in dct_fin:
row[1] = dct_fin[gem]
else:
row[1] = gem
curs.updateRow(row)
# dissolve gemeindes
arcpy.Dissolve_management(in_features=fc, out_feature_class=fc_out,
dissolve_field=fld_out, statistics_fields="",
multi_part="MULTI_PART")
if __name__ == '__main__':
main()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
What happens when for example Unna has been joined with Dortmund, but when evaluating Schwerte it turns out the Dortmund (big city) also has the highest value. Should this city be joined twice or should it only be joined to the highest value in Commuters? Or should the Destination be joined to the highest value of the Origin and then exclude that origin for the next destination?
Are the geometries of the cities polygons?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I think in that case an ideal output will be Unna, Dortmund and Schwerte all 3 combined into one shape. Similarly if Schwerte later has the highest value for some other municipality then that municipality will also be combined with these 3. So its a kind of chain formation. This is a rationalization project so I want to form single bigger regions combining the little municipalities.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Okay so dissolve still only gives the maximum value for each city. For example it only returns the row with Unna and Bergkamen and removes all other Unna rows. That is the first step but the second and more important thing I want to do is to then make Unna merge with Bergkamen into one polygon somehow. Any ideas about that?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The Dissolve should make one Destination polygon out of all Werne rows, with a single Commuter value of 1073.328 (which is the max value, belonging to Bergkamen). If you want to include the Origin (or better yet, the OriginID) for that Commuter value, try adding a second statistic field with the FIRST option (LAST would also give the same result).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
First thing - I think statistic field with first or last option for OriginID would not work because if the first name in the origin field for a destination is not the one with maximum commuters then it would select that first name but give the max commuter value from some other name. Same goes for the last option. So it will be mismatch between origin and commuter value.
Second thing - yes this can be done but any idea how I would then combine origin and destination polygons for each row after this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Would it be possible to attach (a part of) the dataset? I am not convinced that Dissolve is the option, but to be sure, I need to take a closer look at the data.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here you go. I'm sorry I don't know how I can attach a rar file here directly.
So the spatial join shapefile is the one in which the dissolve is to be done. And the selection shapefile has the attribute table that shows which polygon(destination) needs to be dissolved with which other(origin).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Salman Ahmed ,
I have attached a PDF to aid me in trying to explain the questions I have. The PDF looks something like this:

You have a lot of polygons (Gemeindes) that are includes multiple times in you shapefile. Each polygon contains the from Gemeinde geometry and indicate the number of commuters to other Gemeindes.
If I look at Gemeinde Bergheim in the upper left corner, I see that the highest number of commuters go to Kerpen (lower left) as indicated with the blue arrow pointing south. For Kerpen the highest number go to Frechen (which does no occur in the selection shapefile hence the missing hatching). For Frechen the highest number go to Köln and from Köln the highest number go to Leverkusen.
What should exactly be dissolved into what and what to do with those polygons that will not be merged, but still exist in the shapefile?
Why are there polygons excluded in the selection shape?
As a side note, the arrows were generate with some Python code listed below:
def main():
import arcpy
fc = r"D:\Xander\GeoNet\Gemeinde\NRW_Gemeinde_SpatiaJoin.shp"
fld_from = "GEN"
fld_to = "GEN_1"
fld_val = "Value"
fc_out = r"D:\Xander\GeoNet\Gemeinde\max_con_v01.shp"
# create a dictionary of all the polygons, with key from gemeinde
dct_pol = {r[0]: r[1] for r in arcpy.da.SearchCursor(fc, (fld_from, "SHAPE@"))}
# detemine the max commutors per from gemeinde
dct_max = {}
with arcpy.da.SearchCursor(fc, (fld_from, fld_to, fld_val)) as curs:
for row in curs:
from_g = row[0]
to_g = row[1]
val = row[2]
if from_g in dct_max:
# see is value is higher
tpl = dct_max[from_g]
max_to_g = tpl[0]
max_val = tpl[1]
if val > max_val:
# update entry in dct
dct_max[from_g] = (to_g, val)
else:
# don't update, leave as is
pass
else:
# insert value
dct_max[from_g] = (to_g, val)
# create the connection lines
lst_lines = []
sr = arcpy.Describe(fc).spatialReference
for from_g, tpl in dct_max.items():
to_g = tpl[0]
pnt_f = dct_pol[from_g].trueCentroid
pnt_t = dct_pol[to_g].trueCentroid
polyline = arcpy.Polyline(arcpy.Array([pnt_f, pnt_t]), sr)
lst_lines.append(polyline)
# write lines to output
arcpy.CopyFeatures_management(lst_lines, fc_out)
if __name__ == '__main__':
main()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello,
In your example I would then want Bergheim, Kerpen, Frechen and Koln all dissolved into one polygon. It is a kind of chain that is formed. From Bergheim highest no. of commuters go to Kerpen so dissolve Bergheim with Kerpen. From Kerpen highest no. goes to Frechen. So dissolve Kerpen with Frechen. But Kerpen was already dissolved with Bergheim in the first step so now that polygon which was dissolved before (Bergheim + Kerpen) will further dissolve with Frechen. And this chain will continue for Koln and further. I do believe that at some point this chain will break when for example the highest no. of commuters will go from Koln back to Frechen, then this chain will stop. And similarly other chain have to be created. Hope you get the idea.
And the polygons contain the origin geometry but its better to look at the destinations in the attribute table because in the destination field each name comes only once. But in the origin field it may come multiple times.