- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Script for simultaneous looping and dissolve
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Script for simultaneous looping and dissolve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
In the table attached you can see the destination cities in 'Destination' field. Many of them are same - Werne Werne Werne.......
I want to create a script/model such that when run, it loops through all the rows with the same destination city (all the rows that have Werne for example) and then out of them selects the row that has the maximum value in the 'Commuters' field and then dissolves the destination city with the origin city ('Origin' field) for that row.
For example for Werne the row with the maximum value in the commuter field is the first row. So the tool should identify that and then dissolve Werne with Bergkamen in the map.
And then this should be done for every destination city. So basically the looping must happen only until the rows with same destination cities. Then after dissolving that city with its origin city a new loop should be created for the next destination city in the 'Destination' field.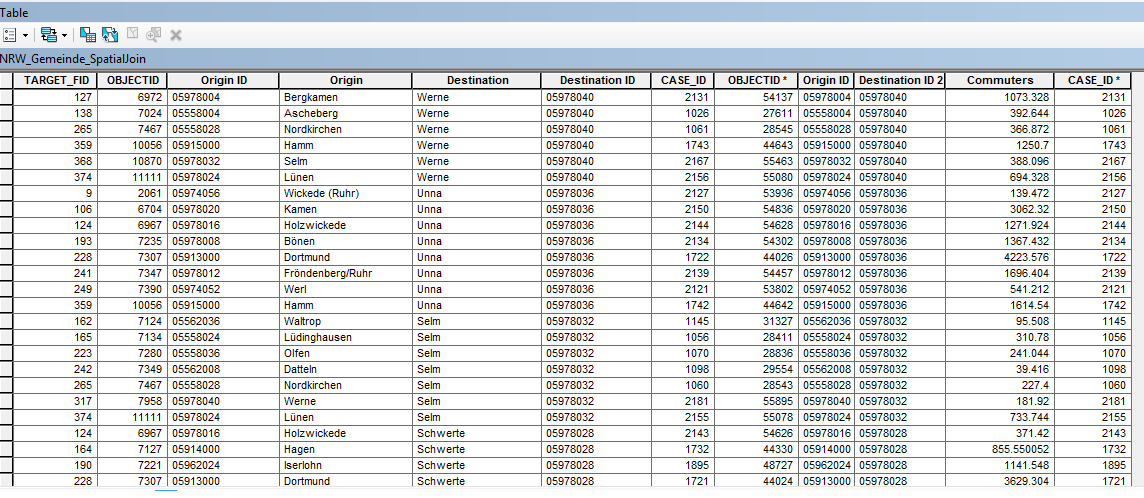
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I did notice two Gemeindes with some problems:

Alpen and Billerbeck link to themselves and have no connections I don't think this is correct...
For the rest connections can be made and will result in 40-45 merged polygons.
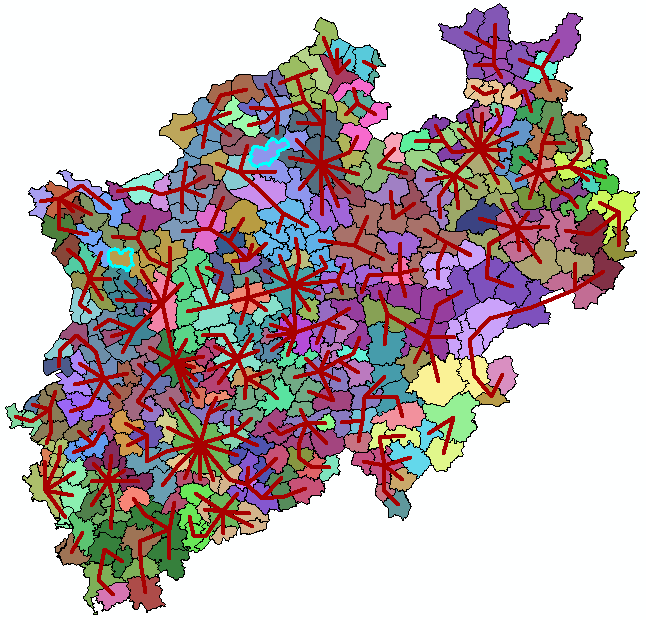
Should the process include anything with the attributes?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Ah I think I missed those two when I was deleting each polygon joining with itself after the spatial join. Now I have deleted them here and performed the selection again.
Hmmm if I could still see the names of the municipalities merged within each big polygons in the attribute table then it would be really helpful.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
OK, I created some code that seems to yield the correct result, but it is pretty ugly and unreadable... The result look like this (thick black lines):
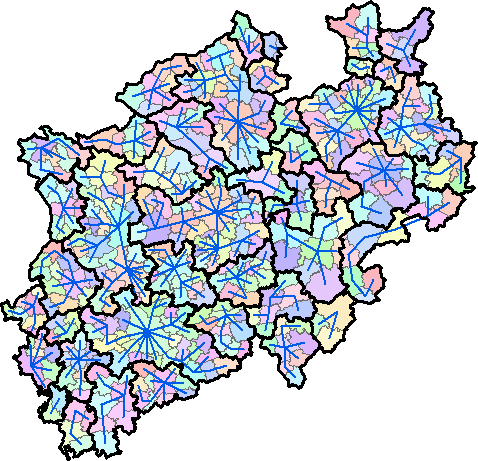
... and the attribute lists the Gemeindes that were used to create the merged polygons.
I have attached the resulting shapefile, so you can have a look and check the result.
The code used to create the output is listed below:
def main():
import arcpy
arcpy.env.overwriteOutput = True
# input fc
fc = r"C:\Forum\Gemeinde\NRW_Gemeinde_SpatiaJoin.shp"
fld_from = "GEN"
fld_to = "GEN_1"
fld_val = "Value"
# output field (will be added to input fc)
fld_out = "Gemeindes"
# output fc
fc_out = r"C:\Forum\Gemeinde\NRW_Gemeinde_diss01.shp"
# detemine the max commutors per from gemeinde
dct_max = {}
with arcpy.da.SearchCursor(fc, (fld_from, fld_to, fld_val)) as curs:
for row in curs:
from_g = row[0]
to_g = row[1]
val = row[2]
# check that from_Gemeinde is not equal to to_Gemeinde
if from_g != to_g:
if from_g in dct_max:
# check if value is higher
tpl = dct_max[from_g]
max_to_g = tpl[0]
max_val = tpl[1]
if val > max_val:
# update entry in dct
dct_max[from_g] = (to_g, val)
else:
# insert value
dct_max[from_g] = (to_g, val)
lst_init = []
for from_g, v in sorted(dct_max.items()):
to_g = v[0]
merged = False
for i in range(0, len(lst_init)):
lst = lst_init
if from_g in lst or to_g in lst:
# merge
lst.extend([from_g, to_g])
lst_init = lst
merged = True
if merged == False:
lst_init.append([from_g, to_g])
lst_init = [list(set(lst)) for lst in lst_init]
lst_all = []
for lst in lst_init:
for a in lst:
lst_all.append(a)
lst_all = list(set(lst_all))
dct = {}
for a in lst_all:
lst_ids = []
for i in range(0, len(lst_init)):
lst = lst_init
if a in lst:
lst_ids.append(i)
dct=lst_ids
lst_res = []
for gem, lst_ids in sorted(dct.items()):
# print gem, lst_ids
lst_ids2 = lst_ids
for ids in lst_ids:
lst = lst_init[ids]
for gem2 in lst:
ids = dct[gem2]
lst_ids2.extend(ids)
lst_ids2 = list(set(lst_ids2))
lst_res.append(lst_ids2)
lst_res = sorted(lst_res)
lst_res2 = []
res = []
for i in range(0, len(lst_res)):
prev_res = res
res = sorted(lst_res)
if res != prev_res:
lst_res2.append(res)
for i in range(len(lst_res2)-1, -1, -1):
res = lst_res2
for j in range(0, i+1):
res2 = lst_res2 = sorted(list(set(res)))
if i <> j:
lst_res2.pop(i)
lst_missing = []
for i in range(0, len(lst_init)):
bln_found = False
for lst in lst_res2:
if i in lst:
bln_found = True
break
if bln_found == False:
lst_missing.append(i)
lst_res2.append(lst_missing)
lst_fin = []
for res in sorted(lst_res2):
lst_elem = []
for ids in res:
lst_gem = lst_init[ids]
lst_elem.extend(lst_gem)
lst_fin.append(list(set(lst_elem)))
dct_fin = {}
for fin in lst_fin:
for g in fin:
dct_fin = ",".join(fin)
if len(arcpy.ListFields(fc, wild_card=fld_out)) == 0:
arcpy.AddField_management(in_table=fc, field_name=fld_out, field_type="TEXT", field_length=255)
flds = (fld_from, fld_out)
with arcpy.da.UpdateCursor(fc, flds) as curs:
for row in curs:
gem = row[0]
if gem in dct_fin:
row[1] = dct_fin[gem]
else:
row[1] = gem
curs.updateRow(row)
# dissolve gemeindes
arcpy.Dissolve_management(in_features=fc, out_feature_class=fc_out,
dissolve_field=fld_out, statistics_fields="",
multi_part="MULTI_PART")
if __name__ == '__main__':
main()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you so much for your work. Although a bit unreadable, this script is very very valuable for me and I will try to understand it.
A question though - how do I download your attachment here? I don't even see it anywhere.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
To download attachments, make sure you open the discussion up and are not viewing it in your Inbox or Activity Stream.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The resulting shapefile is perfect, thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
OK, since you wanted to know... a short explanation:
- lines 6 - 9: definition of input shapefile and fields
- line 12: output field to be added to input shapefile
- line 15: path to output shapefile
- lines 18 - 36: read input shapefile and create a dictionary with from gemeinde as key and a tuple of to Gemeinde and comutors as value
- line 25: skips those records where From-Gemeinde is equal to To-Gemeinde
- lines 38 - 50: creates a list of list with the connections between Gemeindes and starts to merge items
- lines 52 - 57: creates a simple list of all the Gemeindes
- lines 59 - 66: creates a dictionary that contains the name of he Gemeinde as key and list of indexes in the initial list that contain that Gemeinde
- lines 68 - 78: tries to merge records where a Gemeinde is shared
- lines 80 - 87: sorted the previous list and creates a new one for all unique entries
- lines 89 - 97: loops twice through the list backwards and forwards and merges records and eliminates duplicates
- lines 99 - 108: since the previous block was to entousiatic it eliminated a group of gemeindes that are not duplicates, this block corrects it (just so you know how dirty thing got)
- lines 110 - 116: creates a list of the Gemeindes that need to be merged
- lines 118 - 121: creates a dictionary containing the Gemeinde as key and a list of names the need to be merged as value
- lines 123 - 124: adds the output field in case it does not already exists
- lines 126 - 134: fills the output field with the list of names of Gemeindes that need to be dissolved
- lines 137 - 139: executes the dissolve on the output field.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Excellent summary
.... with arcpy.da.SearchCursor(fc, (fld_from, fld_to, fld_val)) as curs: for row in curs: from_g = row[0] to_g = row[1] val = row[2] .....
the conversion of variables from the standard row[0] to at least field names is a good idea to follow
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Many thanks!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi, I tried to use your script above to make the connecting lines on my dataset. I got the lines but there are no arrows. Do I need to do something else? Here is the dataset - http://www.dropbox.com/sh/rj2lhcgfnjmlxgf/AACHHHXDRR_1NdtlD-BlZaQ_a?dl=0