- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Returning the first unique result with searchcurso...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Returning the first unique result with searchcursor?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Looking for a way to return the next unique result with a searchcursor in arcpy.
The table is from a spatial join of areas and has been sorted through python already.
However, I would like a way to have the name of the result recorded to a text file (or other dictionary) and to only take the next result each time the script runs and to check the dictionary to determine the next row to take.
Therefore allowing me to work row by row, one at a time, where they will be exported to a GeoJSON file through quick export.
I am struggling to find a way to make this executable.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hard to really interpret what you are asking for, but if you really want to find the "next" unique value in a field, here is one method:
import arcpy
fc = r'C:\Users\xxxxx\Desktop\tmp.gdb\cc4'
fields = ['_type']
# load all values from the listed field into List with SearchCursor
# then, makes a set from the list (this gives only unique values)
Uni = set([row[0] for row in arcpy.da.SearchCursor(fc, fields)])
# since we now have a set with the unique values only, you can
# iterate through that set now and do as you plese with each one
for val in Uni:
#Do something with this value
# or, write to text file
# or, add to dictionary
# etc.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Python sets are unordered, so the posted code snippet will provide a list of unique values for a field(s) but it won't provide the "next unique value."
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
thus the comment about not being clear about what is being asked for.
Guess I'm not sure what the 'next unique result' is. Is that the next, non-equal consecutive value in the sorted table?
the first time a value is encountered in the sorted table, etc?
OP mentions wanting to use the next result 'each time' and work row by row (assuming across the entire table).
Based on the vagueness of the question, it sounded like OP wanted to be able to perform export operations for rows with a specified value in a particular field. A set would give all the unique values loaded from that field.
Iterating through the set will give you the next value, then the next, etc. of the set itself (not necessarily the order they were in the original table), but would give a list of unique values to query on......
of course, this could all be mute depending on the actual question.
R_
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Benjamin Brewer, as the discussion between Rhett Zufelt and I shows, there are multiple ways to interpret what you are trying to accomplish. What would be most helpful is to provide either an actual or made-up example that you and commenters can respond to directly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Joshua and Rhett Zufelt, sorry I have had a really busy day in school. Thank you for looking over at my question.
To clarify some more of what it is I am trying to do.
I have a feature class, named TWP_Messages which is a spatial join of GPS points and the ATS grid system in Alberta.
I have sorted this feature class by a count field for the amount of GPS messages in each township. I then want to take the top result of that join and export it into a GeoJSON file which I will then use, incorporated with a script I have written to download satellite imagery from Planet Labs. I however only want to do this one township (1 cell of the ATS grid) at a time so not to be overloaded.
To achieve this I was hoping to find a way that a search cursor, or similar will take the first area from the spatial join, but as it exports this area it writes the area name in to a text file. I then ideally would like that text file to be used as a check list so when I next run the script it will then look at the text file, know that it has taken the top ranked area from the sorted join feature class and then move on to the next area in the list.
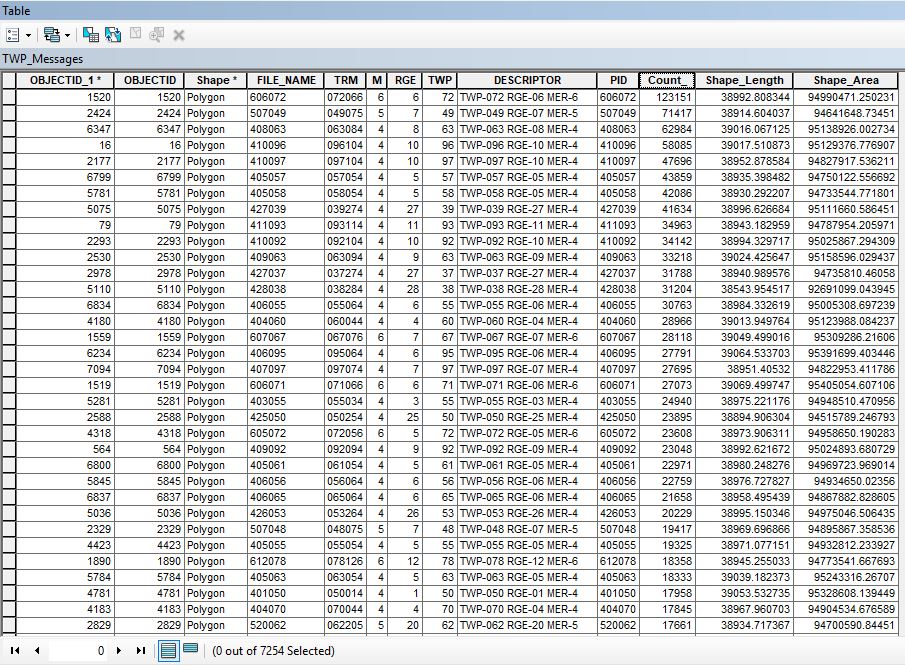
So in this feature class the first time it runs it will select the row for object ID 1520, the second time the script runs I would like for it to be able to check which areas have already been selected, so the first row in the table, ignore that and then move on to the second row so it can be exported.
I hope that is easier to understand. I am sure it can be done but I cant seem to find a similar instance where something similar has been done before.
Again, thank you for all your help. I hope I have described the situation better.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You could use the code of Rhett Zufelt and go one with writing every unique value to a list and use the max of the list to find the highest count.
for val in Uni:
MyList.append(val)
MaxValue = max(MyList)
print "Max value element : ", MaxValueAfter that you can use MaxValue to do a select by attribute on your featureclass which I would copy before.
Let you give out the name of the selected row with another search cursor
for row in arcpy.SearchCursor(fc_Layer):
print row.FILE_NAME
Write this to a text file
Delete the selected feature and go to the next MaxValue
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I had not thought about deleting data as I wanted to keep the original dataset complete but this could be the option I need. So with the print row.FILE_NAME I can take the selected area and then export it as I wish, then as it deletes that row from the table the next time it runs it will just start from the next available row. Thank you, I will give this a try.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The feature class is static, right? That is, the results of the spatial join aren't changing between times you extract the result for a new township. If the spatial join is static, you really want to process the whole feature class once, create a single output file with the results, and then go through that file one at a time. Trying to implement the specific steps you describe complicates the scripting and would perform poorly since you are constantly going back to the feature class.
This type of question gets asked every 6 months or so on GeoNet. GroupBy 2 columns and keep all fields has a good discussion of different approaches using ArcPy cursors and NumPy.
Adapted from one of the code snippets in the thread mentioned above, the following creates a layer and selects records. After the records are selected, you can export them however you like.
from itertools import groupby
from operator import itemgetter
fc = # path to feature class
case_fields = ["DESCRIPTOR"]
max_field = "Count_"
sql_orderby = "ORDER BY {}, {} DESC".format(", ".join(case_fields), max_field)
fl = arcpy.MakeFeatureLayer_management(fc, "fc_lyr").getOutput(0)
oidField = arcpy.Describe(fl).OIDFieldName
oids = []
with arcpy.da.SearchCursor(fl, "*", sql_clause=(None, sql_orderby)) as cur:
oidField = cur.fields.index(oidField)
case_func = itemgetter(
*(cur.fields.index(fld) for fld in case_fields)
)
for key, group in groupby(cur, case_func):
oids.append(next(group)[oidField])
continue
fl.setSelectionSet("NEW_SELECTION", oids)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Joshua, yes the join is static once it has been completed. In the real world scenario this may not be the case but from what I want to achieve here then it is more than appropriate. I had thought I was going a bit over complicated and that is why I was struggling to find examples. I will be trying to implement this further, thank you for the link you provided too, gives me more to read up on and work out from there.
Thank you for your help. I will update with what is working best once I have adapted the changes.