- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Reording of OBJECTID
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am need to reorder the objectID, but I am having difficulties getting the code correct.
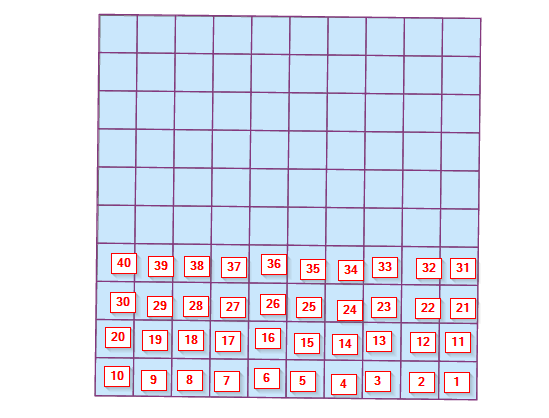
The OriginalOrder.png is what it currently is and the ReOrder.png is what I want. see pictures.
I need the reorder to match the ReOrder picture.
code,
import arcpy
# Define paths
input_fc = r"C:\Temp\Grid.gdb\Clipped_Grid_Polygons"
# Add fields for Max_Longitude and Min_Latitude if they don't already exist
fields = [f.name for f in arcpy.ListFields(input_fc)]
if "Max_Longitude" not in fields:
arcpy.AddField_management(input_fc, "Max_Longitude", "DOUBLE")
if "Min_Latitude" not in fields:
arcpy.AddField_management(input_fc, "Min_Latitude", "DOUBLE")
if "NewIDField" not in fields:
arcpy.AddField_management(input_fc, "NewIDField", "LONG")
# Calculate Max_Longitude and Min_Latitude for each feature
with arcpy.da.UpdateCursor(input_fc, ["OBJECTID", "SHAPE@", "Max_Longitude", "Min_Latitude"]) as cursor:
for row in cursor:
polygon = row[1]
max_longitude = max(point.X for part in polygon for point in part)
min_latitude = min(point.Y for part in polygon for point in part)
row[2] = max_longitude
row[3] = min_latitude
cursor.updateRow(row)
print("Max_Longitude and Min_Latitude fields calculated and updated.")
# Extract the features into a list
features = []
with arcpy.da.SearchCursor(input_fc, ["OBJECTID", "Max_Longitude", "Min_Latitude"]) as cursor:
for row in cursor:
features.append((row[0], row[1], row[2]))
# Sort the list based on Min_Latitude (ascending) and Max_Longitude (descending)
features.sort(key=lambda x: (x[2], -x[1]))
# Create a dictionary to map the new OID values
new_oid_mapping = {oid_tuple[0]: index + 1 for index, oid_tuple in enumerate(features)}
# Update the original feature class with the new NewIDField values based on the sorted order
with arcpy.da.UpdateCursor(input_fc, ["OBJECTID", "NewIDField"]) as cursor:
for row in cursor:
current_oid = row[0]
if current_oid in new_oid_mapping:
row[1] = new_oid_mapping[current_oid]
cursor.updateRow(row)
print("NewIDField values reordered based on Min_Latitude and Max_Longitude sorting.")
Solved! Go to Solution.
{kind=link}
{kind=link}
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
arcpy makes this operation really difficult. I need to do it pretty frequently and I usually use a method like this:
from arcpy.typing.describe import FeatureClass
from typing import Generator
# Use field names in cursor with this function
def as_dict(cursor: arcpy.da.SearchCursor) -> Generator[dict, None, None]:
with cursor as cur:
yield from ( dict(zip( cur.fields, row) for row in cursor ) )
input_fc = r"C:\Temp\Grid.gdb\Clipped_Grid_Polygons"
input_desc: FeatureClass = arcpy.Describe(input_fc)
fields = [f.name for f in input_desc.fields]
# Remove the generic shape and insert the full shape token
# This is neccesary for inserting a real shape back into the table
# after the re-ordering
fields.remove(input_desc.shapeFieldName)
fields.insert(0, "SHAPE@")
if "Max_Longitude" not in fields:
arcpy.AddField_management(input_fc, "Max_Longitude", "DOUBLE")
if "Min_Latitude" not in fields:
arcpy.AddField_management(input_fc, "Min_Latitude", "DOUBLE")
if "NewIDField" not in fields:
arcpy.AddField_management(input_fc, "NewIDField", "LONG")
# Update the fields after adding the new fields
# you can probably just apppend them to the fields list
# but this will make sure that nothing funky happens
input_desc: FeatureClass = arcpy.Describe(input_fc)
fields = [f.name for f in input_desc.fields]
# Calculate Max_Longitude and Min_Latitude for each feature
with arcpy.da.UpdateCursor(input_fc, ["OBJECTID", "SHAPE@", "Max_Longitude", "Min_Latitude"]) as cursor:
for row in as_dict(cursor):
polygon: arcpy.Polygon = row["SHAPE@"]
max_longitude = max(point.X for part in polygon for point in part)
min_latitude = min(point.Y for part in polygon for point in part)
row["Max_Longitude"] = max_longitude
row["Min_Latitude"] = min_latitude
# Because the row is now a dictionary, we need to pull the values out
# and convert them to a regular list or tuple.
# This only works because Python 3.7+ guarantees dictionary order
# Don't do this in Python 2 because the default dict object is not ordered
cursor.updateRow(list(row.values()))
print("Max_Longitude and Min_Latitude fields calculated and updated.")
# Make sure we use the same field order for all cursors (all_fields)
# We're also using the as_dict function again to disambiguate what we're doing
features: list[dict[str, any]] = [row for row in as_dict(arcpy.da.SearchCursor(input_fc, all_fields))]
features.sort(key=lambda x: (x["Min_Latitude"], -x["Max_Latitude"]))
# Use an editor context when editing the feauture class because we need to delete all rows
# If you do that in an edit context, you can rollback the changes if something goes wrong
with arcpy.da.Editor(input_desc.workspace):
# Delete all rows in the feature class
# Here be dragons, make sure you have a backup of the data
arcpy.management.DeleteRows(input_fc)
# If you need the OIDs to start at zero, you need to "Compress" the feature class
# Uncomment below reset the OID values to start at 1
# arcpy.management.Compress(input_fc)
# Re-Insert the rows in the sorted order
with arcpy.da.InsertCursor(input_fc, fields) as cursor:
for row in features:
# Use the same list conversion as before
cursor.insertRow(list(row.values()))
print("NewIDField values reordered based on Min_Latitude and Max_Longitude sorting.")
I've also been working on a more "logical" interface for operations with filedatabase features like this in my pytframe2 project. Here's an example of the same code written using my FeatureClass interface:
import arcpy
from arcpy.typing.describe import FeatureClass
from typing import Generator
from utils.datamodel.models import FeatureClass, as_dict
def main():
input_fc = r"C:\Temp\Grid.gdb\Clipped_Grid_Polygons"
clipped_grid = FeatureClass(input_fc)
for field in ["Max_Longitude", "Min_Latitude", "NewIDField"]:
if field not in clipped_grid.fields:
clipped_grid.add_field(field, "DOUBLE" if field != "NewIDField" else "LONG")
with clipped_grid.update_cursor() as cursor:
for row in as_dict(cursor):
polygon = row["SHAPE@"]
max_longitude = max(point.X for part in polygon for point in part)
min_latitude = min(point.Y for part in polygon for point in part)
row["Max_Longitude"] = max_longitude
row["Min_Latitude"] = min_latitude
cursor.updateRow(list(row.values()))
print("Max_Longitude and Min_Latitude fields calculated and updated.")
sort_by_coords = lambda x: (x["Min_Latitude"], -x["Max_Latitude"])
sorted_features = sorted(sort_by_coords, list(clipped_grid))
# Start an edit session
with clipped_grid.editor:
# Delete all rows
with clipped_grid.update_cursor(["OID@"]) as cursor:
for row in sorted_features:
cursor.deleteRow()
# Re-insert the rows in the sorted order
with clipped_grid.insert_cursor() as cursor:
for row in sorted_features:
cursor.insertRow(list(row.values()))
print("NewIDField values reordered based on Min_Latitude and Max_Longitude sorting.")
if __name__ == "__main__":
main()
As a warning, all the code above is untested. I would definitely use it on a copy of your data and let me know if there are any bugs.
Edit: immediately found one in my pytframe example, in shadowing the typing.describe.FeatureClass with the utils.datamodel.FeatureClass.
This won't break the script because the typing one is just being used so the editor can lint the code, but if you want to fix it you just need to change the import name with an `import as` statement on one of them.
Will probably end up renaming the data model class to FeatureClassModel to avoid this, or extend the typing class so you don't need it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Relying on feature order based on OID is kindof iffy.
The only way to change OID is to create a new feature class in the order you desire, so this isn't an UpdateCursor task, but an InsertCursor one.
Getting the "back-and-forth" numbering is a matter of assigning bands (by Y value), then using modulus-2 of band-number to assign left-to-right or right-to-left order.
- V
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Yes, I did know that, which is why I am trying to populate the new filed "NewIDField". I am still having issue with the sort.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
As a SQL query, it's pretty basic but doing this in Python is a bit trickier, since you have to do the inner query in memory. The key is to chunk the features into rows by Y, so you can order by X. Then you need to flip the listed X values on alternate rows. I'm on a deadline, so I can't offer even a rough untested code block.
- V
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
arcpy makes this operation really difficult. I need to do it pretty frequently and I usually use a method like this:
from arcpy.typing.describe import FeatureClass
from typing import Generator
# Use field names in cursor with this function
def as_dict(cursor: arcpy.da.SearchCursor) -> Generator[dict, None, None]:
with cursor as cur:
yield from ( dict(zip( cur.fields, row) for row in cursor ) )
input_fc = r"C:\Temp\Grid.gdb\Clipped_Grid_Polygons"
input_desc: FeatureClass = arcpy.Describe(input_fc)
fields = [f.name for f in input_desc.fields]
# Remove the generic shape and insert the full shape token
# This is neccesary for inserting a real shape back into the table
# after the re-ordering
fields.remove(input_desc.shapeFieldName)
fields.insert(0, "SHAPE@")
if "Max_Longitude" not in fields:
arcpy.AddField_management(input_fc, "Max_Longitude", "DOUBLE")
if "Min_Latitude" not in fields:
arcpy.AddField_management(input_fc, "Min_Latitude", "DOUBLE")
if "NewIDField" not in fields:
arcpy.AddField_management(input_fc, "NewIDField", "LONG")
# Update the fields after adding the new fields
# you can probably just apppend them to the fields list
# but this will make sure that nothing funky happens
input_desc: FeatureClass = arcpy.Describe(input_fc)
fields = [f.name for f in input_desc.fields]
# Calculate Max_Longitude and Min_Latitude for each feature
with arcpy.da.UpdateCursor(input_fc, ["OBJECTID", "SHAPE@", "Max_Longitude", "Min_Latitude"]) as cursor:
for row in as_dict(cursor):
polygon: arcpy.Polygon = row["SHAPE@"]
max_longitude = max(point.X for part in polygon for point in part)
min_latitude = min(point.Y for part in polygon for point in part)
row["Max_Longitude"] = max_longitude
row["Min_Latitude"] = min_latitude
# Because the row is now a dictionary, we need to pull the values out
# and convert them to a regular list or tuple.
# This only works because Python 3.7+ guarantees dictionary order
# Don't do this in Python 2 because the default dict object is not ordered
cursor.updateRow(list(row.values()))
print("Max_Longitude and Min_Latitude fields calculated and updated.")
# Make sure we use the same field order for all cursors (all_fields)
# We're also using the as_dict function again to disambiguate what we're doing
features: list[dict[str, any]] = [row for row in as_dict(arcpy.da.SearchCursor(input_fc, all_fields))]
features.sort(key=lambda x: (x["Min_Latitude"], -x["Max_Latitude"]))
# Use an editor context when editing the feauture class because we need to delete all rows
# If you do that in an edit context, you can rollback the changes if something goes wrong
with arcpy.da.Editor(input_desc.workspace):
# Delete all rows in the feature class
# Here be dragons, make sure you have a backup of the data
arcpy.management.DeleteRows(input_fc)
# If you need the OIDs to start at zero, you need to "Compress" the feature class
# Uncomment below reset the OID values to start at 1
# arcpy.management.Compress(input_fc)
# Re-Insert the rows in the sorted order
with arcpy.da.InsertCursor(input_fc, fields) as cursor:
for row in features:
# Use the same list conversion as before
cursor.insertRow(list(row.values()))
print("NewIDField values reordered based on Min_Latitude and Max_Longitude sorting.")
I've also been working on a more "logical" interface for operations with filedatabase features like this in my pytframe2 project. Here's an example of the same code written using my FeatureClass interface:
import arcpy
from arcpy.typing.describe import FeatureClass
from typing import Generator
from utils.datamodel.models import FeatureClass, as_dict
def main():
input_fc = r"C:\Temp\Grid.gdb\Clipped_Grid_Polygons"
clipped_grid = FeatureClass(input_fc)
for field in ["Max_Longitude", "Min_Latitude", "NewIDField"]:
if field not in clipped_grid.fields:
clipped_grid.add_field(field, "DOUBLE" if field != "NewIDField" else "LONG")
with clipped_grid.update_cursor() as cursor:
for row in as_dict(cursor):
polygon = row["SHAPE@"]
max_longitude = max(point.X for part in polygon for point in part)
min_latitude = min(point.Y for part in polygon for point in part)
row["Max_Longitude"] = max_longitude
row["Min_Latitude"] = min_latitude
cursor.updateRow(list(row.values()))
print("Max_Longitude and Min_Latitude fields calculated and updated.")
sort_by_coords = lambda x: (x["Min_Latitude"], -x["Max_Latitude"])
sorted_features = sorted(sort_by_coords, list(clipped_grid))
# Start an edit session
with clipped_grid.editor:
# Delete all rows
with clipped_grid.update_cursor(["OID@"]) as cursor:
for row in sorted_features:
cursor.deleteRow()
# Re-insert the rows in the sorted order
with clipped_grid.insert_cursor() as cursor:
for row in sorted_features:
cursor.insertRow(list(row.values()))
print("NewIDField values reordered based on Min_Latitude and Max_Longitude sorting.")
if __name__ == "__main__":
main()
As a warning, all the code above is untested. I would definitely use it on a copy of your data and let me know if there are any bugs.
Edit: immediately found one in my pytframe example, in shadowing the typing.describe.FeatureClass with the utils.datamodel.FeatureClass.
This won't break the script because the typing one is just being used so the editor can lint the code, but if you want to fix it you just need to change the import name with an `import as` statement on one of them.
Will probably end up renaming the data model class to FeatureClassModel to avoid this, or extend the typing class so you don't need it.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You can skip that, or just remove it from your code. I use it to get intellisense for describe objects while I'm programming