- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Polyline NumPy Array to Pandas DataFrame: StElevat...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Polyline NumPy Array to Pandas DataFrame: StElevation and EndElevation?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have converted a feature class (polylines) to a numpy array and have expoded the polylines to vertices using the "explode_to_points" method. I would like to convert the output numpy array to a pandas dataframe that will replicate the line segments that make up the polyline so that I land up with the following columns:
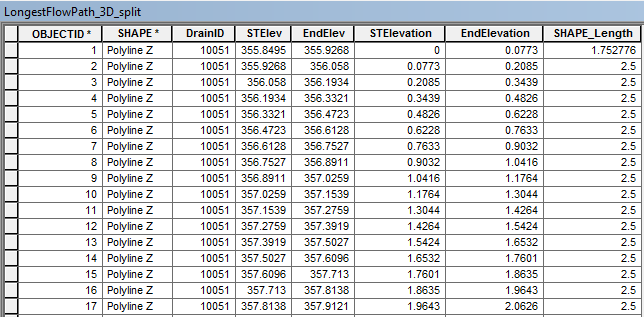
The table above was achieved by using "Split Line At Vertices". The fields "STElev" and "EndElev" are the Start Elevation and End Elevation of the line segments determined using "Calculate Geometry". The field "STElevation" and "EndElevation" is the change in elevation determined by subtracting the elevation from the first "STElev" which in this case is 355.8495.
The output numpy array from converting my feature class (polylines) and exploding the features to vertices is:

The values are:
[(DrainID, X, Y, Z)....] for each vertice
'''
Created on 01 Jul 2017
@author: PeterW
'''
# import modules and site-packages
import numpy as np
import pandas as pd
from pathlib import Path
import arcpy
# set environment settings
arcpy.env.overwriteOutput = True
# check out extensions
arcpy.CheckOutExtension("3D")
def longestflowpath_3d(dtm, lfp_2d):
"""Generate LongestFlowPath 3D
from LongestFlowPath 2D and DTM"""
output_gdb = str(Path(lfp_2d).parents[0])
lfp_3d = "{0}\\{1}".format(output_gdb, "lfp_3d")
lfp_3d = arcpy.InterpolateShape_3d(dtm, lfp_2d, lfp_3d, vertices_only=True)
arcpy.FlipLine_edit(lfp_3d)
return lfp_3d
def area_under_profile(lfp_3d):
"""Determine the Equal Area Slope
for each Drainage Area's Longest
Flowpath"""
arr = arcpy.da.FeatureClassToNumPyArray(lfp_3d, ["DrainID", "SHAPE@X", "SHAPE@Y", "SHAPE@Z"], explode_to_points=True) # @UndefinedVariable
print(arr)
def equal_area_slope(dtm, lfp_2d):
"""Determine the Equal Area Slope
for each Drainage Area's Longest
Flowpath"""
lfp_3d = longestflowpath_3d(dtm, lfp_2d)
area_under_profile(lfp_3d)
if __name__ == "__main__":
dtm = r"E:\Projects\2016\G113665\geoHydro\DTM2\raw1"
lfp_2d = r"E:\Projects\2016\G113665\geoHydro\Model02\Results.gdb\LongestFlowPath_2D_Orig"
equal_area_slope(dtm, lfp_2d)My current Python Module
How can I convert the current numpy array to a pandas dataframe that will restructure the vertices (DrainID, X, Y, Z) to (DrainID, STElevation (change in elevation), EndElevation (change in elevation), DistM (Length of segment)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Can you post a few sample lines? It would be much easier to demonstrate a solution if there were a couple of examples for us to test against.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Joshua
I've attached a copy of the polylines unsplit as well as a copy of the polylines split with the output fields and values that I'm trying to achieve.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Peter
Haven't got time for a full example, but this will get you thinking.
Consider two lines with 4 points each consisting of an ID, X, Y, and Z field as a structured array (numpy )
The final result shown (dz) is the individual lines.
Note... this is the long way, but the logic is less clear in the short way.
a # a structured array
array([(1, 0.0, 0.0, 0.0), (1, 1.0, 1.0, 1.0), (1, 2.0, 2.0, 2.0),
(1, 3.0, 3.0, 3.0), (2, 3.0, 3.0, 4.0), (2, 2.0, 2.0, 5.0),
(2, 1.0, 1.0, 6.0), (2, 0.0, 0.0, 7.0)],
dtype=[('ID', '<i8'), ('X', '<f8'), ('Y', '<f8'), ('Z', '<f8')])
ids = np.unique(a['ID']) # get the unique IDs for the array
ids
array([1, 2], dtype=int64) # no surprise...
# conceptually you want to extract/slice all the points that share a common id
# A list comprehension will be used as an example of this slicing But...
lines = [a[a['ID'] == i] for i in ids] # .... this is the long way
# now that you have the points for each line, simply take the last and the
# first point (-1 and 0 respectively) and get the 'Z' values
dz = [ln[-1]['Z'] - ln[0]['Z'] for ln in lines]
dz # no surprise, 4 points per line Z difference each line is 3
[3.0, 3.0]
# similar process for planar distance
# the whole process can be simplified... but that is for later
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan, Thanks this will get me started. I'll post shortly what I come up with and if I get stuck.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I think this will get you what you want, or something close:
from itertools import groupby
import pandas
fields = ["STElev", "EndElev", "STElevation", "EndElevation"]
id_field = "DrainID"
split_lines = arcpy.SplitLine_management("LongestFlowPath_unsplit","in_memory/split")
for field in fields:
arcpy.AddField_management(split_lines, field, "DOUBLE")
with arcpy.da.UpdateCursor(split_lines, [id_field, "SHAPE@"] + fields) as cur:
for k, grp in groupby(cur, key=lambda x: x[0]):
shape = next(grp)[1]
fpz, lpz = shape.firstPoint.Z, shape.lastPoint.Z
kpz = fpz
cur.updateRow([k, shape, fpz, lpz, fpz - kpz, lpz - kpz])
for row in grp:
shape = row[1]
fpz, lpz = shape.firstPoint.Z, shape.lastPoint.Z
cur.updateRow([k, shape, fpz, lpz, fpz - kpz, lpz - kpz])
with cur:
df = pandas.DataFrame.from_records(
cur, exclude=["SHAPE@"], columns=[id_field, "SHAPE@"] + fields
)
del curSince I don't work with NumPy much, this approach uses an update cursor to populate the table and then just dumps the populated table directly to a pandas data frame.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Joshua
Thanks for the following, sorry I should have been more clear in my post. I'm trying to re-write an existing Python module based on a previous post Extract Polyline Geometry Z and M - Equal Area Slope where I'd like to replace the use of ArcPy "SplitLine_Management" with NumPy arrays and Pandas DataFrames. I wan't to remove the need for and Advanced Licence for the end user.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here you go, I did the splitting myself instead of using the geoprocessing tool. NumPy may be faster, I just took this approach since I am more familiar with it.
from itertools import tee
import pandas
unsplit_lines = "LongestFlowPath_unsplit" # Assumes data loaded in ArcMap
fields = ["STElev", "EndElev", "STElevation", "EndElevation"]
id_field = "DrainID"
SR = arcpy.Describe(unsplit_lines).spatialReference
split_lines = arcpy.CreateFeatureclass_management(
"in_memory","split","POLYLINE", has_m="ENABLED", has_z="ENABLED", spatial_reference=SR
)
arcpy.AddField_management(split_lines, id_field, "LONG")
for field in fields:
arcpy.AddField_management(split_lines, field, "DOUBLE")
with arcpy.da.SearchCursor(unsplit_lines,["SHAPE@","DrainID"]) as scur:
with arcpy.da.InsertCursor(split_lines,["SHAPE@",id_field] + fields) as icur:
for shape, drainid in scur:
for part in shape.getPart():
n, n1 = tee(part)
ptz = next(n1).Z
for pt1 in n1:
pt = next(n)
segment = arcpy.Polyline(arcpy.Array([pt, pt1]), SR)
icur.insertRow([segment, drainid, pt.Z, pt1.Z, pt.Z - ptz, pt1.Z - ptz])
del scur, icur
df_fields = [id_field] + fields
with arcpy.da.SearchCursor(split_lines, df_fields) as cur:
df = pandas.DataFrame.from_records(cur, columns=df_fields)
del cur- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
back for a bit. Now I don't know if you just wanted the 2D planar distance between the first and last point or a 3D distance along the whole length of each polyline. Let me know.
Check these results against a quick scan of measure tool distances. The results are in sequential order...I didn't want to get too fancy for the output yet. I have kept it verbose, since there is a simpler way of calculating the 3D polyline distance if you need it.
pnt_fc = r'F:\_anaconda\polyline_demo\polyline_unsplit\unsplit\split_pnts.shp'
fc = r'F:\_anaconda\polyline_demo\polyline_unsplit\unsplit\LongestFlowPath_unsplit.shp'
flds = ['OID@', 'SHAPE@X', 'SHAPE@Y', 'SHAPE@Z']
SR = arcpy.Describe(fc).spatialreference
a = arcpy.da.FeatureClassToNumPyArray(fc,
field_names=flds,
spatial_reference=SR,
explode_to_points=True)
dt = [('ID', '<i4'), ('X', '<f8'), ('Y', '<f8'), ('Z', '<f8')]
a.dtype = dt
ids = a['ID']
x_s = a['X']
y_s = a['Y']
z_s = a['Z']
ids = np.unique(ids)
lines = [a[a['ID'] == i] for i in ids]
dz = np.array([ln[-1]['Z'] - ln[0]['Z'] for ln in lines])
dx = np.array([ln[-1]['X'] - ln[0]['X'] for ln in lines])
dy = np.array([ln[-1]['Y'] - ln[0]['Y'] for ln in lines])
dist = np.sqrt(dx**2 + dy**2)
print("2D distances first point to last point \n{}".format(dist))
# ---- result
2D distances first point to last point
[ 4645.90189847 1249.26103157 1244.66988595 1458.63110731 1757.96791359
1676.49347515]- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan
I actually need the distance between each vertices. I'm trying to re-write the Python module to calculate the "Equal Area Slope" using NumPy and Pandas and not ArcPy "SplitLine_Management" based on my previous post: Extract Polyline Geometry Z and M - Equal Area Slope.