- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Export to CSV with Override and NO Header Row - Py...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Export to CSV with Override and NO Header Row - Python
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I've built a Pythons script the organizes a dataset that is used for an external database and exported it from a File Geodatabase to a .CSV file. The last part of the workflow is to manually delete the header row and copy the CSV to a network drive and override the existing .CSV file. Now, its been requested to make the workflow 100% automatic and have it built into my current Batch File collection to run each night. Just (2) pieces of the script I cannot figure out how to write:
1) Export File GDB Table to .CSV file WithOut the Header Row
2) When the .CSV file is exported, it Overrides the existing file in it's place with the same name.
Any assistance, would be appreciated.
Thank You
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You're using Python 2.x which doesn't support 'newline'.
Remove this
newline=''then add the following at the end of the previous code. It should work now.
file_object = open(outfile, 'r')
lines = csv.reader(file_object, delimiter=',', quotechar='"')
flag = 0
data=[]
for line in lines:
if line == []:
flag =1
continue
else:
data.append(line)
file_object.close()
if flag ==1: #if blank line is present in file
file_object = open(outfile, 'w')
for line in data:
str1 = ','.join(line)
file_object.write(str1+"\n")
file_object.close() - Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Modern Electric
Here's the code that exports a File GDB Table to a .CSV file WithOut the Header Row and it also overrides the existing file in it's place with the same name.
import arcpy
import csv, os
arcpy.env.overwriteOutput = True
workspace = r"working path"
gdb_fc = os.path.join(workspace, r"path to GDB Feature Class")
outfile = os.path.join(workspace, "output_data.csv")
fields = arcpy.ListFields(gdb_fc)
field_names = [field.name for field in fields]
with open(outfile,'w') as f:
w = csv.writer(f)
# w.writerow(field_names) **This is commented out to skip writing a header**
for row in arcpy.SearchCursor(gdb_fc):
field_vals = [row.getValue(field.name) for field in fields]
w.writerow(field_vals)
del row- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Mehdi:
Thank You for the assistance. Looks like we are almost there. Here are (2) issues that I am having. I hate to be picky but if the .CSV file is not 100% correct, the database that loads it will fail the upload process.
When I open the .CSV in Microsoft Excel, the export adds a separate field, I assume its the ESRI automatic OID number (might be mistaken on the field name).
The other problem is between each line, there is a space. I know for a fact having the space between each row will force the upload process to fail.
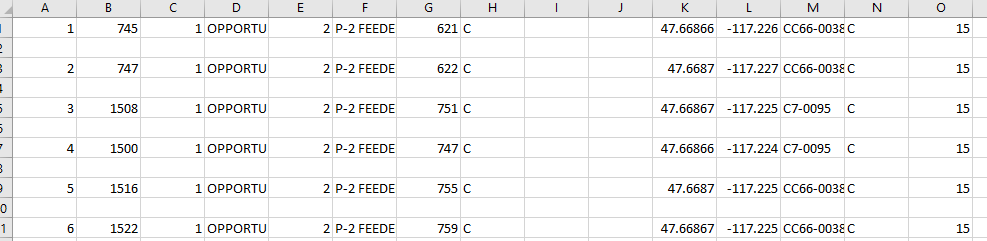
Here is a clip of what the .CSV file looks like after opening it in Excel.
Any other advice on these (2) items and I should be in good shape.
Thank You again.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This issue is much simpler to solve, and I would argue more robust, by addressing it on the import side rather than export side. It is so much easier to simply skip a line at the start of a file when reading it than removing the first line after it is created. Once the file is created, most or all techniques for removing the line involves reading and re-writing the file. One approach to not creating the header line in the first place would be to export the data set to a pandas dataframe and then export to csv from there.
Can the import process be modified to inspect the first line and then decide whether to skip it?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Try this one, it removes blank rows and you can specify which fields to output in the csv file:
import arcpy
import csv, os
arcpy.env.overwriteOutput = True
workspace = r"working path"
gdb_fc = os.path.join(workspace, r"path to GDB Feature Class")
outfile = os.path.join(workspace, "output_data.csv")
fields = arcpy.ListFields(gdb_fc)
# for instance, you want to output just the following fields
fieldsToKeep = ['Tree_Type', 'Latitude', 'Longitude', 'Tree_Height', 'Note']
# field_names = [field.name for field in fields if field.name in fieldsToKeep]
with open(outfile,'w', newline='') as f:
w = csv.writer(f)
# w.writerow(field_names) **This is commented out to skip writing a header**
for row in arcpy.SearchCursor(gdb_fc):
field_vals = [row.getValue(field.name) for field in fields if field.name in fieldsToKeep]
w.writerow(field_vals)
del row
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank You Mehdi:
Looks like we are almost there, however:
with open(outfile,'w', newline='') as f:is giving me this:
TypeError: 'newline' is an invalid keyword argument for this function
Not sure what that means.
If I replace this line with what you had in the original script:
with open(outfile,'w') as f:The script works, BUT still has spaces between the rows.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You're using Python 2.x which doesn't support 'newline'.
Remove this
newline=''then add the following at the end of the previous code. It should work now.
file_object = open(outfile, 'r')
lines = csv.reader(file_object, delimiter=',', quotechar='"')
flag = 0
data=[]
for line in lines:
if line == []:
flag =1
continue
else:
data.append(line)
file_object.close()
if flag ==1: #if blank line is present in file
file_object = open(outfile, 'w')
for line in data:
str1 = ','.join(line)
file_object.write(str1+"\n")
file_object.close() - Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
BINGO!!
Only one thing I changed in the code:
if flag ==0
This made the spaced go away. When there was a "1", it kept including the spaces.
Appreciate your help
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Not a problem Modern Electric.
Great to hear that
Could you please flag the question as Answered?
Thanks.