- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Creating Sequential Numbering Based off Zip Co...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Creating Sequential Numbering Based off Zip Codes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi,
I need to calculate a set of unique identifiers that goes sequentially based off the zip code in another field. For example, if the zip code is 77059 I need it to take that number and in the Unique Identifier column I created output 77059.001, then 77059.002 etc. until it gets to the next zip code, and start again. I.e., if 77064 is next, it needs to call that number and start back at 77064.001. This is what I have so far but obviously it doesn't call in the field !ZipCode!, and that's what I've been struggling with. If someone could help with this it would be greatly appreciated.
# Calculates a sequential number
# More calculator examples at esriurl.com/CalculatorExamples
import arcpy
rec=0
def SequentialNumber():
global rec
pStart = 77041
pInterval = .001
if (rec == 0):
rec = pStart
else:
rec = rec + pInterval
return f"{round(rec, 3):.3f}"
Also, its been struggling to output 3 decimals after it gets to .009 for example, it outputs 0.01 and I need it in 3 decimals. Someone else suggested the return f"{round(rec, 3):.3f}" code, but it seems to only work at times.
Noah
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
rec = 12335.0123
type(f"{round(rec, 3):.3f}")
strIf your input zipcode is not text to begin with, the script you are using isn't going to provide you with what you want. If it is text, then it needs to be converted to float, incremented, formatted then converted back to text. I am not seeing that.
Also, are the zipcode data sequential always? (eg, data has been sorted physically prior to being worked on).
If they are not sequential and continuous without breaks, then there are other steps that need to be done
... sort of retired...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan,
Thanks for responding. I only have a basic understanding (if you can call it that) of python so excuse me for the question, but how would I make this a float? I want to take the Zip Code column and create a new column with decimals. It will look like the second image I've attached, but that was done in excel then joined after. Ideally, I'd like to do it all in ArcGIS if possible.
To answer your question, they have been sorted prior to this and I'll attach a screenshot below.


Noah
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The zipcode field isn't the one that is sorted, so a field calculator expression won't work nicely.
TableToNumPyArray, and arcpy's ExtendTable can be used to process data outside
So to fake some of your data.
# --- emulating your data column
seq
Out[113]:
['77070',
'77070',
'77070',
'77064',
'77070',
'77064',
'77065',
'77070',
'77070',
'77075']
# -- notice not ordered nicely
# I created an IDs and Code column in the subsequent section, here is
# what TableToNumPyArray will produce
arr
array([(0, '77070'), (1, '77070'), (2, '77070'), (3, '77064'), (4, '77070'), (5, '77064'), (6, '77065'), (7, '77070'),
(8, '77070'), (9, '77075')], dtype=[('IDs', '<i8'), ('Code', '<U20')])The ids and the data values are created, It is now a matter of finding the unique code values, getting the number of times they exist in the column and producing a sequence to append to them.
ids = np.arange(10, dtype='int')
dt = [('IDs', '<i8'), ('Code', 'U20')]
arr = np.asarray(list(zip(ids, seq)), dtype=dt)
u, idx, cnts = np.unique(arr['Code'], return_index=True, return_counts=True) # get the unique, counts etc
tmp = [list(zip([u[i]] * cnts[i], np.arange(cnts[i]))) for i in range(len(cnts))]
app = np.concatenate(tmp)
out = []
for i in app:
out.append("{}.{:0>3}".format(i[0], i[1]))
final_arr = np.copy(arr)
final_arr['Code'] = final
final_arrAt this point you have
final_arr.tolist() # your IDs and reformatted Code values
[(0, '77064.000'),
(1, '77064.001'),
(2, '77065.000'),
(3, '77070.000'),
(4, '77070.001'),
(5, '77070.002'),
(6, '77070.003'),
(7, '77070.004'),
(8, '77070.005'),
(9, '77075.000')]
# -- as a numpy array to use with arcpy.ExtendTable....
final_arr
Out[115]:
array([(0, '77064.000'), (1, '77064.001'), (2, '77065.000'), (3, '77070.000'), (4, '77070.001'), (5, '77070.002'),
(6, '77070.003'), (7, '77070.004'), (8, '77070.005'), (9, '77075.000')],
dtype=[('IDs', '<i8'), ('Code', '<U20')])
Sorry I don't have ArcGIS Pro any longer so some other keener will have to fluff out the TableToNumPyArray and ExtendTable for you.
Orrrr you could continue to do the stuff in Excel and join back, which is essentially what this does but in a different way.
... sort of retired...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
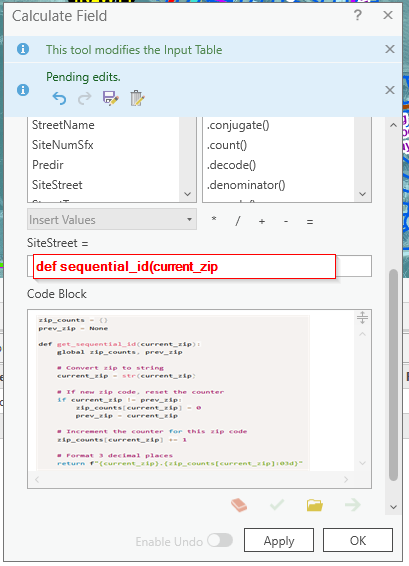
Try this, Paste the code above into the "Code Block"
Then def sequential_id(current_zip) int the "field" = def sequential_id(current_zip)
Code
zip_counts = {}
prev_zip = None
def get_sequential_id(current_zip):
global zip_counts, prev_zip
# Convert zip to string
current_zip = str(current_zip)
# If new zip code, reset the counter
if current_zip != prev_zip:
zip_counts[current_zip] = 0
prev_zip = current_zip
# Increment the counter for this zip code
zip_counts[current_zip] += 1
# Format 3 decimal places
return f"{current_zip}.{zip_counts[current_zip]:03d}"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi,
Sorry for the dumb question but I'm really not that well versed in Python (or any coding languages for that matter). What do you mean by "Then def sequential_id(current_zip) int the "field" = def sequential_id(current_zip)".
Noah
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'd just use a .zfill():
codes: dict[int, int] = {}
def SequentialNumber(code) -> str:
global codes
codes.setdefault(code, 0)
codes[code] += 1
return float(f"{code}.{str(codes[code]).zfill(3)}")You also can't use a float for this as the __repr__ of a float always removes the trailing zeroes. You need to string format it.
You also REALLY don't want to be adding a value to the zip code. If you happen to add 0.001 1000 times, suddenly 77829 is 77830. Use a mapping with a counter if you need to preserve the zipcode.
To use this in the window you need to pass the zipcode field value to the function:

{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here's a blog post that walks you through creating a tool in ArcGIS Pro: it would need a slight tweak to use a "." instead of a "-" for the separator.
https://learn.finaldraftmapping.com/sequentially-increment-numbered-values-in-arcgis-pro-with-arcpy/