- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Conversion from CSV to DBF altering data...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So, I successfully converted my .csv to a .dbf with this script:
env.workspace = r"c:\Output"
inTable = r"c:\Output\test.csv"
outLocation = r"c:\Output"
outTable = "test.dbf"
arcpy.TableToTable_conversion(inTable, outLocation, outTable)
The problem is, in the resulting .dbf file, its adding a decimal with trailing zeroes to the value:
750050
becomes
750050.00000000000
How can I avoid this?
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
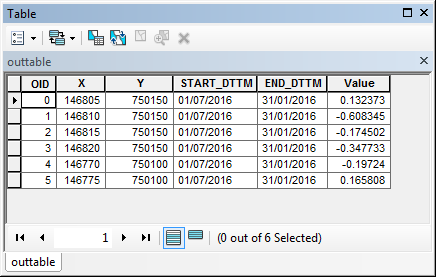
Here is a sample of my data:
| X | Y | START_DTTM | END_DTTM | Value |
| 1468050 | 750150 | 1/7/2016 | 1/31/2016 | 0.13237318 |
| 1468100 | 750150 | 1/7/2016 | 1/31/2016 | -0.60834539 |
| 1468150 | 750150 | 1/7/2016 | 1/31/2016 | -0.17450202 |
| 1468200 | 750150 | 1/7/2016 | 1/31/2016 | -0.34773338 |
| 1467700 | 750100 | 1/7/2016 | 1/31/2016 | -0.19723971 |
| 1467750 | 750100 | 1/7/2016 | 1/31/2016 | 0.16580771 |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hmmm. That works for me. Can you get it to work properly through the GUI dialog? Do both X and Y come in as Long?
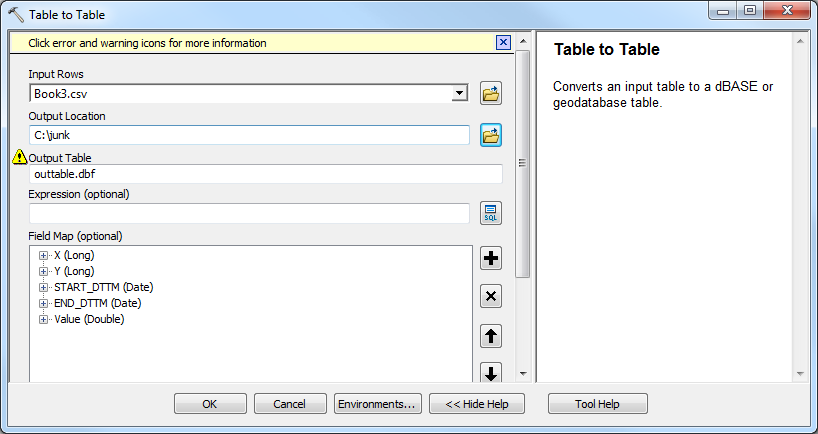
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You can get it to run programmatically as well?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
It works for me (using your code), BUT you will need to use: Format=TabDelimited in your schema.ini is the file is delimited by Tabs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Well, my actual csv file is comma delimited. The sample I posted here I opened in excel and copied and pasted a table-like structure. Should it read Format=CommaDelimited?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
To avoid errors in the interpretation of the file it is best to attach the actual file instead of pasting it in a different format. The attach option is available (lower right corner) when you activate the advanced editor (link upper right corner).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Yes, this results in exactly the same output table:
>>> inTable = r"c:\junk\Book3.csv" ... outLocation = r"c:\junk" ... outTable = "test.dbf" ... arcpy.TableToTable_conversion(inTable, outLocation, outTable)
If I change the csv to include a decimal (e.g. 750050.00001), then it gets read as Double, which will display decimal places.
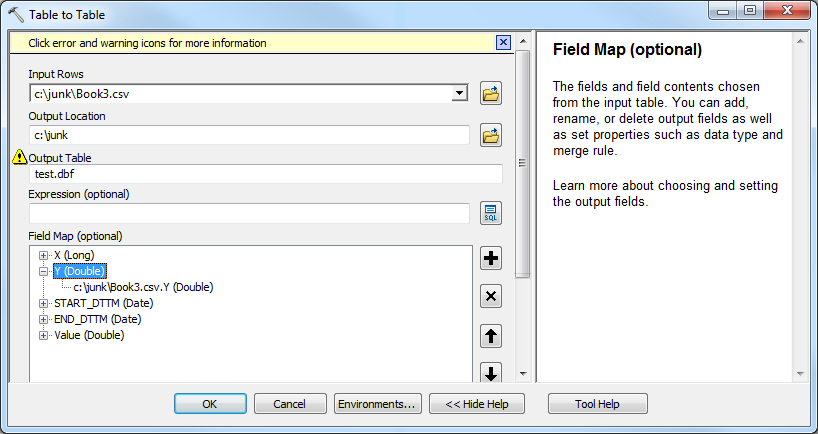
Using the field map, I can force it back to Long (no more decimal places).

The code via Copy As Python Snippet changes to:
arcpy.TableToTable_conversion(in_rows="c:/junk/Book3.csv",out_path="c:/junk",out_name="test.dbf",where_clause="#",field_mapping="""X "X" true true false 4 Long 0 0 ,First,#,c:/junk/Book3.csv,X,-1,-1;Y "Y" true true false 8 Long 0 0 ,First,#,c:/junk/Book3.csv,Y,-1,-1;START_DTTM "START_DTTM" true true false 8 Date 0 0 ,First,#,c:/junk/Book3.csv,START_DTTM,-1,-1;END_DTTM "END_DTTM" true true false 8 Date 0 0 ,First,#,c:/junk/Book3.csv,END_DTTM,-1,-1;Value "Value" true true false 8 Double 0 0 ,First,#,c:/junk/Book3.csv,Value,-1,-1""",config_keyword="#")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Did you run it with column names like: Col1=A Long or Col1=X Double ? Wondering what you may have done differently.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This is my schema.ini
[test2.csv]
ColNameHeader=True
Format=TabDelimited
Col1=X Long
Col2=Y Long
Col3=START_DTTM DateTime
Col4=END_DTTM DateTime
Col5=Value Double
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
SUCCESS! I used the schema.ini example you just posted changing ONLY TabDelimited to CSVDelimited. Thank you!