- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Compare two tables field values using wildcard
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Compare two tables field values using wildcard
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello, I'm currently working with one feature class table containing 400 000 objects and one database table containing 700 objects. I'm currently working in ArcMap 10.4 and using a Geodatabase with Python 2.7. What I'm trying to do is match the database table containing 700 objects against the FC. What I want is to match them, treating all 700 objects as wildcars %700 ojects%, and match those towards the FC that contains text from the table. I have 2 tables with 1 column in each that im trying to match. I have not yet found a good way to treat all rows in a column as wildcard to search against another column.
This is my code so far. This only will print out what the database table values. Next i wanted to get the FC values and compare them. I've read about maybe using a dictionary to make it easier to extract values but I've yet to figure out how.
import arcpy, unicodedata, datetime, openpyxl
arcpy.env.workspace =r"C:\Users\kaaper\Documents\DataDrivenPages\DataDrivenPages.gdb"
def rows_as_dicts(cursor):
colnames = cursor.fields
for row in cursor:
yield dict(zip(colnames, row)
with arcpy.da.SearchCursor(r"C:\Users\kaaper\Documents\DataDrivenPages\DataDrivenPages.gdb\Ordbok", '*') as sc:
for row in rows_as_dicts(sc):
print row['field']Any input will be appreciated.
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The column named "field" from "Ordbok" is the one i want to compare to column "SNAVN" in "Navn" yes. Some will have same text some places in "field", but different diffraction. So both texts separated by comma must be compare with OR statement, so that they count both texts to a name. In "field" there are some accent marks, they can be ignored. Meaning the text is correct, but they have accent marks. I should've removed the accent marks when converting the file type, sorry about that. About those in parenthesis, they are as well something that can be ignored, since they only explain what the word means in a simplified text. The only text that should be taking into account from "field" is those that are separated by comma and don't have parenthesis around them.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
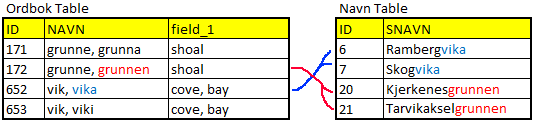
Is this the type of comparison you are attempting? Will you be matching the terms in parenthesis? Example: aita (gjerde) Just match "aita"? Or "gjerde" as well? Is a term like "grunnen" always at the end of the location's name?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I answered above about those in parenthesis, short answer, no they should not be compared. Mostly the text will be at the end of a name yes, but in some cases it will be in the middle or first, so the wildcard is needed to be sure. From what I can see in the example, it's the way I want to compare the columns. The only thing is that it's "field" that contains the text, since "Navn" is the alias in Arcmap, the real name is "field" in "Ordbok". Hope this helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Just to see if the clear up more doubts about the desired result I wrote some code (just a test, really badly written) and I have attached the result applied to the csv files.
Code:
# -*- coding: utf-8 -*-
def main():
import os
csv_file_out = r'C:\GeoNet\SearchWildcard\Navn_test.csv'
csv_file = r'C:\GeoNet\SearchWildcard\Ordbok.csv'
cnt = 0
lst_texts = []
with open(csv_file, 'r') as f:
for line in f.readlines():
cnt += 1
line = line.replace('\n', '')
lst = line.split(';')
lst_items = stripText2list(lst[3])
lst_texts.append(lst_items)
# the large one
csv_file = r'C:\GeoNet\SearchWildcard\Navn.csv'
cnt = 0
dct_hits = {}
with open(csv_file_out, 'w') as f_out:
with open(csv_file, 'r') as f:
for line in f.readlines():
cnt += 1
if cnt % 1000 == 0:
print "Processing row:", cnt
line = line.replace('\n', '')
if cnt == 1:
line_out = line + ";result\n"
f_out.write(line_out)
lst = line.split(';')
if len(lst) > 25:
lst_items = stripText2list(lst[25])
for lst_validate in lst_texts:
for validate in lst_validate:
for item in lst_items:
if validate.upper() in item.upper():
ids = cnt
if ids in dct_hits:
data = dct_hits[ids]
found = False
for l in data:
if l[0] == item and l[1] == validate:
found = True
if found == False:
data.append([item, validate])
dct_hits[ids] = data
else:
dct_hits[ids] = [[item, validate]]
# write output line
if cnt > 1:
line_out = line
line_out += ';'
if cnt in dct_hits:
data = dct_hits[cnt]
result = ''
for data_item in data:
if result == '':
result = data_item[1]
else:
result += ", " + data_item[1]
line_out += result
line_out += '\n'
f_out.write(line_out)
## for ids, data in dct_hits.items():
## # pass
## print ids, "\t", data
def stripText2list(text):
text_ori = text
s = text.find('(')
if s != -1:
e = text.find(')')
if e == -1:
e = len(text)-1
text = text[0:s] + text[e:len(text)-1]
text = text.replace('"','')
text = text.replace(';','')
text = text.replace('-','')
text = text.replace(',',' ')
text = text.replace(' ','')
lst = text.split(' ')
lst_ok = []
for a in lst:
a = a.strip()
if a != '':
if a[0] != '(':
if a[-1:] != ')':
lst_ok.append(a)
return lst_ok
if __name__ == '__main__':
main()
The last field "result" contains the search text that resulted in a hit
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
From what I can see from the result file, it looks really good. The matches are what i wanted, and takes all text that matches from "field" against "SNAVN". Can I replace the CSV files in the code, to compare 2 different file types? Since "Navn" is a Feature Class with annotations, and "Ordbok" is a Standalone Table. If so I can try and test the code towards more rows from "Navn" to see if the results are the same. But this is really good results, thank you very much.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Current code is not using any ArcGIS (arcpy) parts. To point to annotation and a table, you will have to change parts of the code and implement SearchCursors to obtain the data and an UpdateCursor to update the data. I would have been better to attach the data in the format it is in.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If possible, please attach the data in a zipped FGDB to this thread to make adjustments to the code.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
That's what i though, since I didn't see any arcpy import. I'll upload the FGDB in zip tomorrow, I've taken the liberty to remove a good amount of the fields in "Navn" to make it easier to read.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Per Olav Kaasa ,
You can try the code below. It will take some time to run. Be sure to run this on the uncompressed version of the data (it will not be able to run on compressed data).Change the following:
- lines 7 to 11, names and paths to the data to be used (line 9 contains the output field for the results which will be added to the annotation in case it does not exist). Don't have the annotation open with Desktop, since this will create a lock on the data and the process may fail.
# -*- coding: utf-8 -*-
def main():
import arcpy
# settings (first uncompress geodatabase data!)
fc_anno = r'C:\GeoNet\SearchWildcard\gdb\TestBase.gdb\Navn_org'
fld_anno = 'SNAVN' # field to match with dictionary
fld_out = 'OrdbokMatch' # output field name
tbl = r'C:\GeoNet\SearchWildcard\gdb\TestBase.gdb\Ordbok'
fld_tbl = 'field' # dictionary data
# create dictionary list
lst_dct = [stripText2list(r[0]) for r in arcpy.da.SearchCursor(tbl, (fld_tbl))]
# Add output field to annotation
AddField(fc_anno, fld_out, "TEXT", 100)
# loop through annotation and update output field
cnt = 0
# dct_hits = {}
with arcpy.da.UpdateCursor(fc_anno, (fld_anno, fld_out)) as curs:
for row in curs:
cnt += 1
if cnt % 5000 == 0:
print "Processing row:", cnt
snavn = row[0]
lst_items = stripText2list(snavn)
result = FindMatches(lst_items, lst_dct)
row[1] = result
curs.updateRow(row)
def FindMatches(lst_items, lst_dct):
result = None
data = []
for lst_validate in lst_dct:
for validate in lst_validate:
for item in lst_items:
if validate.upper() in item.upper():
data.append(validate)
if len(data) > 0:
data = list(set(data))
result = data[0]
for data_item in data[1:]:
result += ", " + data_item
return result
def AddField(fc, fld_name, fld_type, fld_length=None):
if len(arcpy.ListFields(fc, fld_name)) == 0:
arcpy.AddField_management(fc, fld_name, fld_type, None, None, fld_length)
def stripText2list(text):
text_ori = text
lst_ok = []
if text is None:
return lst_ok
else:
s = text.find('(')
if s != -1:
e = text.find(')')
if e == -1:
e = len(text)-1
text = text[0:s] + text[e:len(text)-1]
text = text.replace('"','')
text = text.replace(';','')
text = text.replace('-','')
text = text.replace(',',' ')
text = text.replace(' ','')
lst = text.split(' ')
for a in lst:
a = a.strip()
if a != '':
if a[0] != '(':
if a[-1:] != ')':
lst_ok.append(a)
return lst_ok
if __name__ == '__main__':
main()