Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Cancel
- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- Re: Performance for Append vs Insert Cursor
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
08-09-2013
11:09 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Ok I have a feature class (260k records) and 3 tables. I need to get specific information (about 20 fields) from each into a new feature class. I have several different ways to do this and I???m curious if anyone has done any performance testing and knows which of my options would be ???best???.
Option 1
I could create several joins and append the data into the new feature class, with some additional field calculations for cleanup.
Option 2
Create a python script that would loop through each record, search cursor the other tables for data, then insert cursor into the new feature class.
Thank you
Alan
Option 1
I could create several joins and append the data into the new feature class, with some additional field calculations for cleanup.
Option 2
Create a python script that would loop through each record, search cursor the other tables for data, then insert cursor into the new feature class.
Thank you
Alan
Solved! Go to Solution.
21 Replies
08-16-2013
10:10 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'll go with the append.
Don't!
Going the Python route (reading the join tables(s) into a dictionary using a search cursor and then updating the main table via an update cursor is by far the fastest method. This is true in v10.0 and below, but is especially true in v10.1+ using ethe data access cursors. In addition to faster processing, this method is far more flexible in that allows for all sorts of error handeling and whatnot through conditional expressions.
For example, say you want to get the fields "ADDRESS" and "CITY" into the main table (key field being "NAME"):lutTbl = r"C:\temp\test.gdb\lookuptable" mainTbl = "r"C:\temp\test.gdb\maintable" lutDict= dict([(r[0], (r[1], r[2])) for r in arcpy.da.SearchCursor(lutTbl, ["NAME","ADDRESS","CITY"])]) arcpy.AddField_managment(mainTbl, "ADDRESS", "TEXT", "", "", "75") arcpy.AddField_managment(mainTbl, "CITY", "TEXT", "", "", "30") updateRows = arcpy.da.UpdateCursor(mainTbl, ["NAME","ADDRESS","CITY"]) for updateRow in updateRows: nameValue = updateRow[0] if nameValue in lutDict: updateRow[1] = lutDict[nameValue][0] #Address updateRow[2] = lutDict[nameValue][1] #City else: print "Could not locate address/city info for " + str(nameValue) updateRows.updateRow(updateRow) del updateRow, updateRows
There was a correction I had to make involving an unmatched bracket, which is reflected in the code in this post.
I tried your code and have to admit I was wrong. The performance of the cursors and dictionary are definitely faster than a Join and the field calculator. The speed difference dramatically increases with each additional field that is updated.
I was wanting to understand the dictionary key field behavior better. Does the key value have to be unique? I assume it does, or else it wouldn't be called a key. For example, what happens if there are two people named John Smith that have different addresses in the look up table? Does the Address and City value of the second John Smith record replace the values of the first John Smith record in the code you have written or do two Addresses with the John Smith key get created in the look up dictionary? I assume the second record replaces the first.
The answer is important to me, because if the second record replaces the first, that would be a gotcha anytime the look up table key field was not guaranteed to be unique. It would have the same problem ArcMap has dealing with one to many and many to many joins by randomly keeping one matching record in the join table and ignoring all of the others. The only way to resolve the full multi-record relationship with just the John Smith key would then have to involve concatenating or summarizing the secondary field values, just like ArcMap must do to resolve multi-record relationships through a Summary Statistics Join.
I also want code that supports multi-field matching between tables that resolves many to many relationships into one to one or many to one relationships through multi-field comparisons without having to concatenate field values in the original tables. In other words, would the dictionary key still have to be the unique concatenation of the Name and Address to preserve both unsummarized records in the look up dictionary and to match the key with the maintbl cursor to resolve the table relationship to get the correct John Smith matching unique multi-field record?
Finally, assuming a multi-field concatenation was needed to preserve the full unsummarized look up table in the dictionary, how would I deal with a true one to many or many to many relationship? In other words, say the look up key had to concatenate John Smith with each address to be unique, but the main table only had John Smith in it. The output I would want would find all of the instances of John Smith in the look up table regardless of what address it is concatenated with and join all of the look up records to the main table records by creating as many duplicates of the main table record needed to produce the full set of matches in the output. How would I write code to do the match between John Smith in the main table and the concatenated keys in the look up dictionary that contained John Smith (assume John Smith is the left most portion of the look up key concatenation)?
08-19-2013
09:02 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
To answer some of your questions:
Yes. But you can use tuples as keys as well (aka a composite key) - which of course also have to be unique.
You have to get creative - I routinely deal with one to many or many to manys by using either composite keys and/or composite look up values. A basic example:
I would put a wager in that anything (well pretty much anything) you can do in a RDBMS you can also do much faster and cheaper using dictionaries. All it takes is imagination and a lot of conditional expressions!
If it helps, here's a practical example of making use of a composite value dictionary where the sorted order of the many values are important to the overal analysis: http://forums.arcgis.com/threads/89835-brainteaser-viewshed-wind-turbines-the-more-you-see-the-worse...
Does the key value have to be unique?
Yes. But you can use tuples as keys as well (aka a composite key) - which of course also have to be unique.
...what happens if there are two people named John Smith that have different addresses in the look up table?
You have to get creative - I routinely deal with one to many or many to manys by using either composite keys and/or composite look up values. A basic example:
compKeyDict = {('smith, john', 1): "cat street", ('smith, john', 2): "dog street"}
compValDict = {'smith, john': ["cat street", "dog street"]}I would put a wager in that anything (well pretty much anything) you can do in a RDBMS you can also do much faster and cheaper using dictionaries. All it takes is imagination and a lot of conditional expressions!
If it helps, here's a practical example of making use of a composite value dictionary where the sorted order of the many values are important to the overal analysis: http://forums.arcgis.com/threads/89835-brainteaser-viewshed-wind-turbines-the-more-you-see-the-worse...
08-19-2013
09:22 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
To answer some of your questions:
Yes. But you can use tuples as keys as well (aka a composite key) - which of course also have to be unique.
You have to get creative - I routinely deal with one to many or many to manys by using either composite keys and/or composite look up values. A basic example:compKeyDict = {('smith, john', 1): "cat street", ('smith, john', 2): "dog street"} compValDict = {'smith, john': ["cat street", "dog street"]}
I would put a wager in that anything (well pretty much anything) you can do in a RDBMS you can also do much faster and cheaper using dictionaries. All it takes is imagination and a lot of conditional expressions!
If it helps, here's a practical example of making use of a composite value dictionary where the sorted order of the many values are important to the overal analysis: http://forums.arcgis.com/threads/89835-brainteaser-viewshed-wind-turbines-the-more-you-see-the-worse...
I still don't follow Python syntax. It makes no sense to me. I am a VBA guy and resist Python until it proves its worth, but even then I don't read Python intelligently and the syntax and descriptors are totally unfamiliar. Translate what you are doing into English, since I do not know what you are setting up. Break it down. For example, how do compKeyDict and compValDict relate to each other? Is this the look up or the set up? Are these two different ways of doing the same thing (looks like it to me). It may as well be Martian. What does the colon mean? What are the brackets doing? It is too cryptic.
I can't get imaginative or creative if I have no idea what I am creating. I also refuse to go to the Python.org site, since the help it provides is useless and even more confusing than the language.
08-19-2013
09:23 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
For this Append vs Insert Cursor discusssion, where is the data in question being stored (SDE database or other container (e.g. file geodatabase(s))?
Does it even matter where the data is stored, as it appears insert cursor is faster than append either way?
Does it even matter where the data is stored, as it appears insert cursor is faster than append either way?
08-19-2013
09:44 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Richard - start here: https://developers.google.com/edu/python/. This is the best intro material I have seen. Watch the videos.
If you want to cut to the dictionary part: http://www.youtube.com/watch?v=haycL41dAhg
After you get familar with Python data structures, I think my examples will make sense.
If you want to cut to the dictionary part: http://www.youtube.com/watch?v=haycL41dAhg
After you get familar with Python data structures, I think my examples will make sense.
08-19-2013
03:20 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You have to get creative - I routinely deal with one to many or many to manys by using either composite keys and/or composite look up values. A basic example:compKeyDict = {('smith, john', 1): "cat street", ('smith, john', 2): "dog street"} compValDict = {'smith, john': ["cat street", "dog street"]}
So the first is a composite key involving two separate tuple keys with each tuple key associated to one value. The second is a single key with a list composite values. I understand how to access the second structure, having adapted the code you originally provided.
However, how would I match the keys of the first example? Would I always have provide a whole tuple for each key or could I get at it by using just the value 'smith, john'? By extension, can the composite key approach involve a list of items, or is it limited to single values and tuples?
08-19-2013
03:47 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The 1st example was meant to show that if you had multiple John Smiths you could introduce a "counter" in the tuple key to keep seperate occurances of the same key "unique". This 1st example structure, I admit, is not very practical or efficient, but is a possible way of dealing with one-to-manys. I would recomend the second example... However, per the 1st example, to retreive a list of all the John Smith keys, you could use something like this:
Per my understanding, the key can only be a single value or a tuple. List are not allowed, since they are mutable, and can be, for example, sorted in place - whcih would screw everything up. Lists of course can be converted to a tuple like this:
compKeyDict = {('smith, john', 1): "cat street", ('smith, john', 2): "dog street", ('smith, jack', 1): "clown street"}
johnSmithKeysList = [key for key in compKeyDict if "smith, john" == key[0]]can the composite key approach involve a list of items, or is it limited to single values and tuples?
Per my understanding, the key can only be a single value or a tuple. List are not allowed, since they are mutable, and can be, for example, sorted in place - whcih would screw everything up. Lists of course can be converted to a tuple like this:
testList = [1,2,3,4] testTuple = tuple(list)
by
Anonymous User
Not applicable
08-20-2013
06:47 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
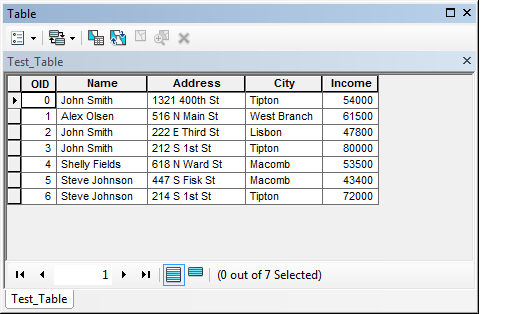
Interesting stuff here...I had never thought to use tuples as a key when worrying about duplicate keys. In the past, I have just gathered a list of unique names, then create a dictionary where the key is one of the unique names and the value is the attributes that match each name. so for example, if I have a table with duplicate names that looks like this:
[ATTACH=CONFIG]26817[/ATTACH]
You can do something like this:
This will print out:
Basically all I have done is create sort of an in memory pivot table, where I can supply a name to get all matching attributes. So if I just want to find all the matching addresses,city for each name I can do this:
This will print out:
Alex Olsen [(u'516 N Main St', u'West Branch')]
Shelly Fields [(u'618 N Ward St', u'Macomb')]
John Smith [(u'1321 400th St', u'Tipton'), (u'222 E Third St', u'Lisbon'), (u'212 S 1st St', u'Tipton')]
Steve Johnson [(u'447 S Fisk St', u'Macomb'), (u'214 S 1st St', u'Tipton')]
Or you can specifically search out "John Smith" like this:
This will print:
(u'1321 400th St', u'Tipton')
(u'222 E Third St', u'Lisbon')
(u'212 S 1st St', u'Tipton')
Finally, you mentioned you wanted to do some summary statistics for the records...In this case, I can easily summarize the amount of income for the 4 names like this:
This will print:
Alex Olsen 61500.0
Shelly Fields 53500.0
John Smith 181800.0
Steve Johnson 115400.0
Of course, the above is a useless statistic, but was just done to show an example of how this can be done. I hope these examples can give you some more ideas at least. Also, you can choose to remove the 'unicoding' as well.
[ATTACH=CONFIG]26817[/ATTACH]
You can do something like this:
import arcpy
dbf = r'C:\TEMP\Test_Table.dbf'
# Get Unique names
fields = [f.name for f in arcpy.ListFields(dbf) if f.type != 'OID']
with arcpy.da.SearchCursor(dbf, fields) as rows:
table = list(r for r in rows) # table as tuple
names = list(set(r[0] for r in table))
# New dictionary
people_dict = {}
# Make each unique name the key
# return all matches as list for values
for name in names:
people_dict[name] = [r for r in table if r[0] == name]
# print matching records for each name
for name,matches in people_dict.iteritems():
print name,matches
print '\n\n'
This will print out:
Alex Olsen [(u'Alex Olsen', u'516 N Main St', u'West Branch', 61500.0)] Shelly Fields [(u'Shelly Fields', u'618 N Ward St', u'Macomb', 53500.0)] John Smith [(u'John Smith', u'1321 400th St', u'Tipton', 54000.0), (u'John Smith', u'222 E Third St', u'Lisbon', 47800.0), (u'John Smith', u'212 S 1st St', u'Tipton', 80000.0)] Steve Johnson [(u'Steve Johnson', u'447 S Fisk St', u'Macomb', 43400.0), (u'Steve Johnson', u'214 S 1st St', u'Tipton', 72000.0)]
Basically all I have done is create sort of an in memory pivot table, where I can supply a name to get all matching attributes. So if I just want to find all the matching addresses,city for each name I can do this:
# print all address, city for each match to name for name,matches in people_dict.iteritems(): print name, [(mat[1],mat[2]) for mat in matches] print '\n\n'
This will print out:
Alex Olsen [(u'516 N Main St', u'West Branch')]
Shelly Fields [(u'618 N Ward St', u'Macomb')]
John Smith [(u'1321 400th St', u'Tipton'), (u'222 E Third St', u'Lisbon'), (u'212 S 1st St', u'Tipton')]
Steve Johnson [(u'447 S Fisk St', u'Macomb'), (u'214 S 1st St', u'Tipton')]
Or you can specifically search out "John Smith" like this:
# print address,city for John Smith for name,attributes in people_dict.iteritems(): if name == 'John Smith': for att in attributes: print att[1:3]
This will print:
(u'1321 400th St', u'Tipton')
(u'222 E Third St', u'Lisbon')
(u'212 S 1st St', u'Tipton')
Finally, you mentioned you wanted to do some summary statistics for the records...In this case, I can easily summarize the amount of income for the 4 names like this:
# Get sum of income for each name for name,matches in people_dict.iteritems(): print name, sum(mat[-1] for mat in matches)
This will print:
Alex Olsen 61500.0
Shelly Fields 53500.0
John Smith 181800.0
Steve Johnson 115400.0
Of course, the above is a useless statistic, but was just done to show an example of how this can be done. I hope these examples can give you some more ideas at least. Also, you can choose to remove the 'unicoding' as well.
{kind=link}
08-20-2013
07:24 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Chris and Caleb:
Thanks for exploring the dictionary syntax more fully and clarifying some of the options I have for working with them. The dict pivot table emulation is interesting and would probably deal with my full many to.many relationship preservation question the best. The summary example also could prove useful.
Just one more example would be appreciated. Summary Statistics cannot get the Min or Max date of a table, since date fields are unavailable for summary. Sometimes I would want the Max date associated with the unique case of each name or other identifier. Typically when I do get this information I then only want the related information of just the record with that max date for the unique ID. How would I do something like that?
So if I had something like (also treat the Last Name and First Name as separate fields):
Smith, John, Jan 10, 2013, Applied
Smith, John, Feb 3, 2013, Assigned
Smith, John, Mar 25, 2013, Tested
Smith, John, Jun 11, 2013, Hired
Smith, Jack, Jan 10, 2013, Applied
Smith, Jack, Feb 7, 2013, Assigned
Smith, Jack, Mar 25, 2013, Tested
Smith, Jack, Jun 5, 2013, Rejected
Smith, Kim, Jan 10, 2013, Applied
Smith, Kim, Feb 12, 2013, Rejected
I would want:
Smith, John, Jun 11, 2013, Hired
Smith, Jack, Jun 5, 2013, Rejected
Smith, Kim, Feb 12, 2013, Rejected
Of course the real data would be many more unique cases with many more data records.
A one shot way to do this kind of summary would have implications for many of my other similar workflows where I first have to summarize a value (say the Min From measure and Max To measure of a set of routes) and then get the associated data for just the record(s) that match that min or max value for that case (for example the house number associated with the min From measure and the max To measure of each route). Using geoprocesssing this is a 3 step process at least.
Thanks for exploring the dictionary syntax more fully and clarifying some of the options I have for working with them. The dict pivot table emulation is interesting and would probably deal with my full many to.many relationship preservation question the best. The summary example also could prove useful.
Just one more example would be appreciated. Summary Statistics cannot get the Min or Max date of a table, since date fields are unavailable for summary. Sometimes I would want the Max date associated with the unique case of each name or other identifier. Typically when I do get this information I then only want the related information of just the record with that max date for the unique ID. How would I do something like that?
So if I had something like (also treat the Last Name and First Name as separate fields):
Smith, John, Jan 10, 2013, Applied
Smith, John, Feb 3, 2013, Assigned
Smith, John, Mar 25, 2013, Tested
Smith, John, Jun 11, 2013, Hired
Smith, Jack, Jan 10, 2013, Applied
Smith, Jack, Feb 7, 2013, Assigned
Smith, Jack, Mar 25, 2013, Tested
Smith, Jack, Jun 5, 2013, Rejected
Smith, Kim, Jan 10, 2013, Applied
Smith, Kim, Feb 12, 2013, Rejected
I would want:
Smith, John, Jun 11, 2013, Hired
Smith, Jack, Jun 5, 2013, Rejected
Smith, Kim, Feb 12, 2013, Rejected
Of course the real data would be many more unique cases with many more data records.
A one shot way to do this kind of summary would have implications for many of my other similar workflows where I first have to summarize a value (say the Min From measure and Max To measure of a set of routes) and then get the associated data for just the record(s) that match that min or max value for that case (for example the house number associated with the min From measure and the max To measure of each route). Using geoprocesssing this is a 3 step process at least.
08-20-2013
08:14 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here's an example of sorting a one-to-many by the date value. While the ESRI summary tools seem to struggle, Python does sort datetime objects correctly I think.
http://forums.arcgis.com/threads/90090-List-Broken-Data-Source-s-Path?p=319811&viewfull=1#post319811
http://forums.arcgis.com/threads/90090-List-Broken-Data-Source-s-Path?p=319811&viewfull=1#post319811