- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- How to analyze signal intersection with crashes.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to analyze signal intersection with crashes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I been given an assignment to group accidents that are near a intersection. I was given three shape files one for signal intersections, all intersections and accidents along the road for one county.
The problem that I am running into is overlapping buffers at the intersections. I am doing 250 feet buffers at the intersection. The reason for this is some intersections are too close to each other.
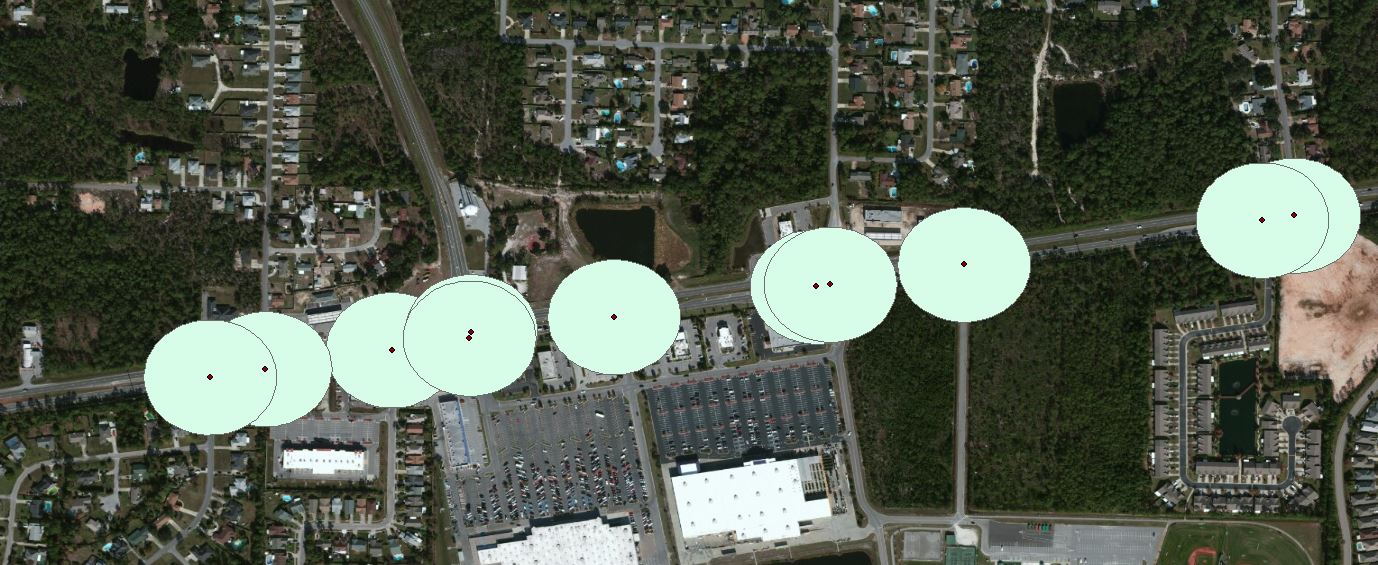
The data that was given to me for intersections are broken into two or more dots one for traffic going left and the other for traffic going right at the same intersection. How can I get these two dots to join through out the whole county instead of doing it one by one.
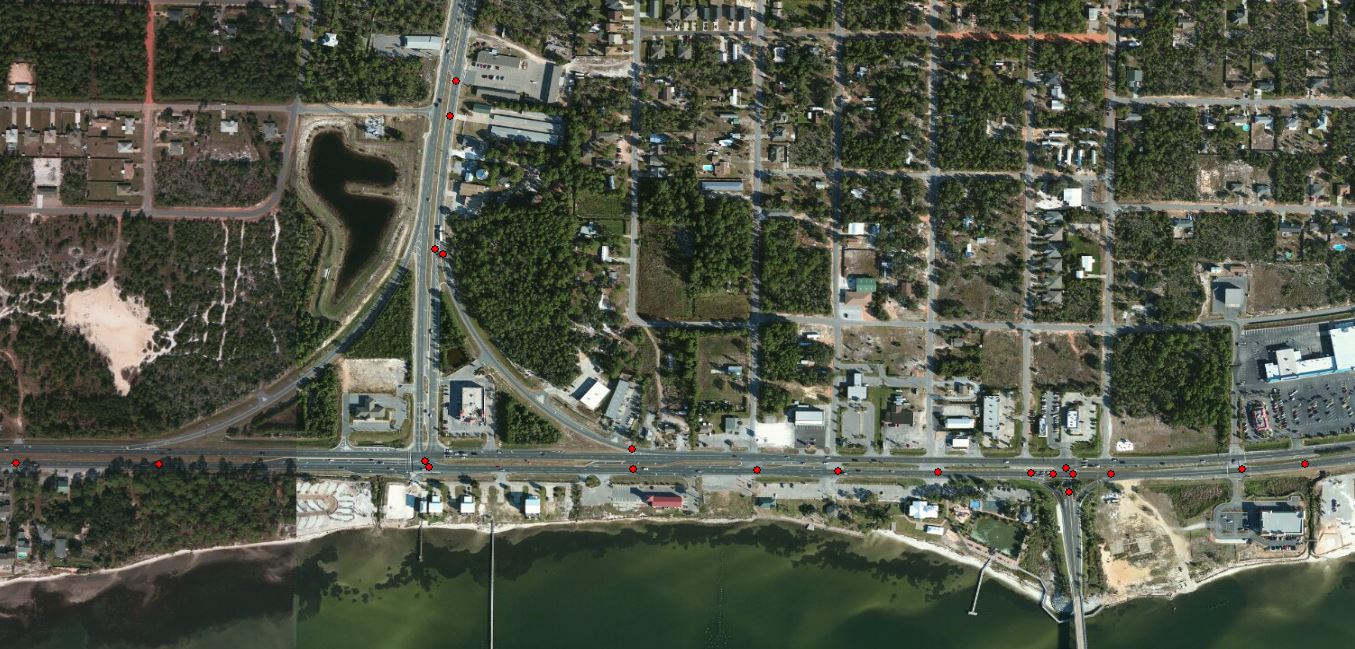
If any one has done something similar to this and would be able to guide me it would be very helpful.
Thanks.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I wonder if buffering your intersections isn't the way to go. I just created two point feature classes: wrecks and intersections. Then I performed a near between them. Here is a snapshot of the augmented wrecks attribute table:
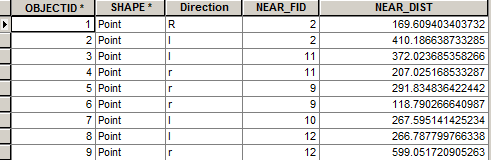
Look at wreck-points (OID) 1 & 2. They are closest to the intersection with OID 2. Clearly this is an extremely simplified analysis, but if I wanted to know which intersections have the most wrecks, I'd summarize this table on the NEAR_FID to get a count. In this case intersection OID 10 only has one wreck associated with it and all the rest have two. With a summary table you'll get a count of whatever you summarize on. Then you could join/relate this information back to the intersections. Make sense?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Would it be possible to merge or append the buffers into a single polygon layer, then use that polygon layer to spatially join to the accident point layer?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I did dissolve and then feature to point and did the buffer again and join my data. Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Elizabeth
if you turn the dissolve type to all in the buffer tool this will do the process in a single step.
regards
Anthony
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I looked into it and yes this saves a lot of steps. Thanks.
I'm having some data counts duplicated on my buffers that are overlapping. What could I do to avoid duplicate counts. I could make the buffer distance smaller but then the dots will not be included in either buffer.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Perhaps you can summarize your data and see if the id shows up more than once.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
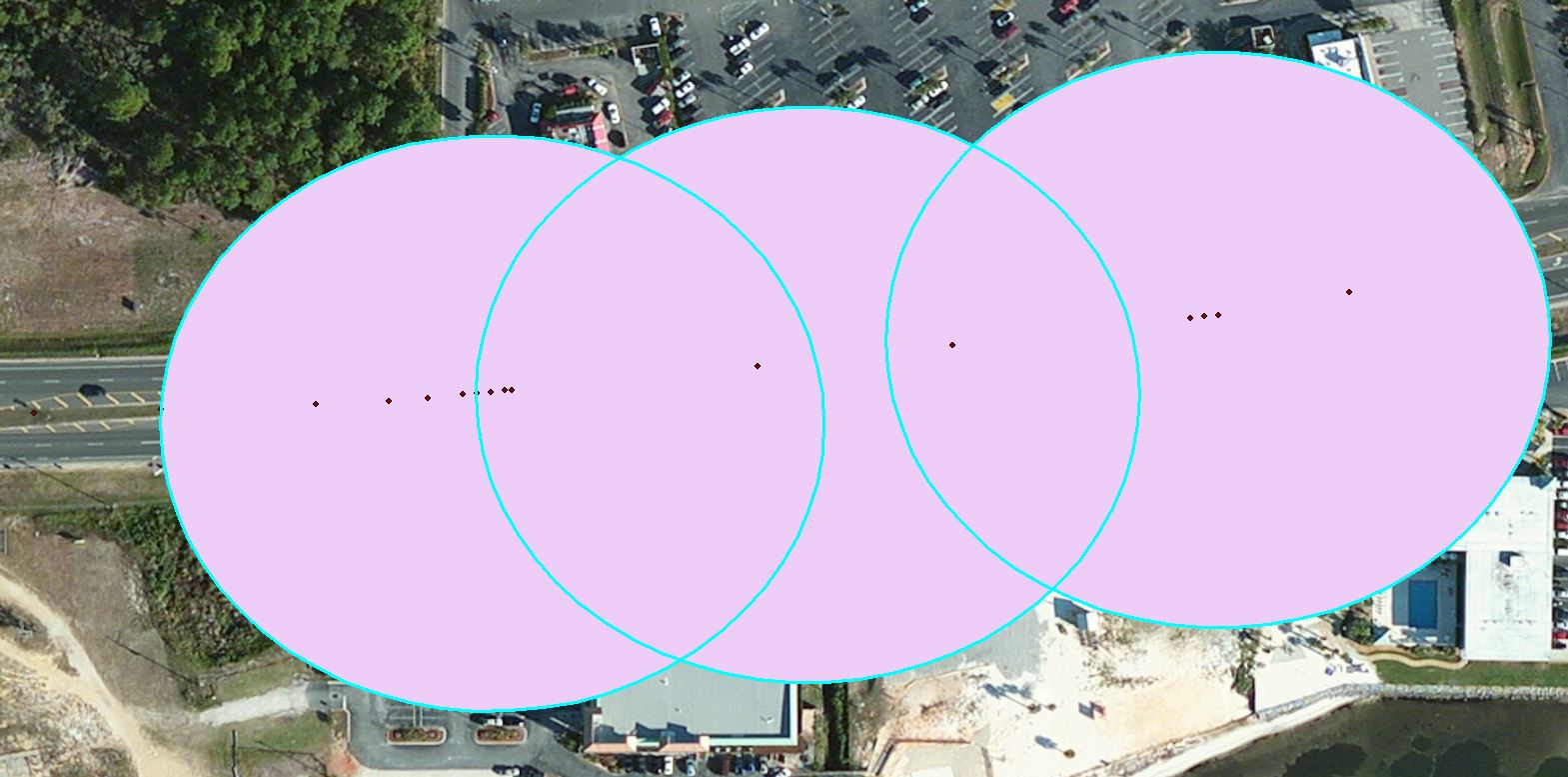
This is what I am getting. The dots are being counted in each buffer and if they overlap they are counted in both buffers. Thanks for your help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
That's what I mean: the buffers are goofing on you; if you do a straight up Near analysis, I'm thinking you should be good to go...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Is there a tool where you can get the nearest/closest crashes that were not picked up by the buffer to be included in the nearest/closest buffer.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
drum roll... Near Tool but it's only available that the highest license level. I don't know what ESRI calls it but I call it ArcInfo. Also, the Point Distance tool may do it too...
