- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Geodatabase Questions
- :
- Fundamental flaw when opening attribute tables in ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Fundamental flaw when opening attribute tables in ArcGIS Pro?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Can someone from ESRI please have a good look at this. @Kory Kramer, @George Thompson, @Vince Angelo
For some background:
- ArcGIS Pro 2.1.3 on Windows 10
- PostgreSQL 9.6 on Ubuntu 18.04 running on a Virtualbox VM executed on the Windows host
Situation:
A line layer with a valid Definition Query set present in the TOC. The layer is an ArcGIS Query Layer (so a spatial database but not an enterprise geodatabase) and references a huge Europe OpenStreetMap extract containing +/- 65M records in the line table. This line table has both valid spatial index (GIST) and attribute indexes. The display performance of the layers in Pro's Map window is adequate, and actually surprisingly fast given the huge data source.
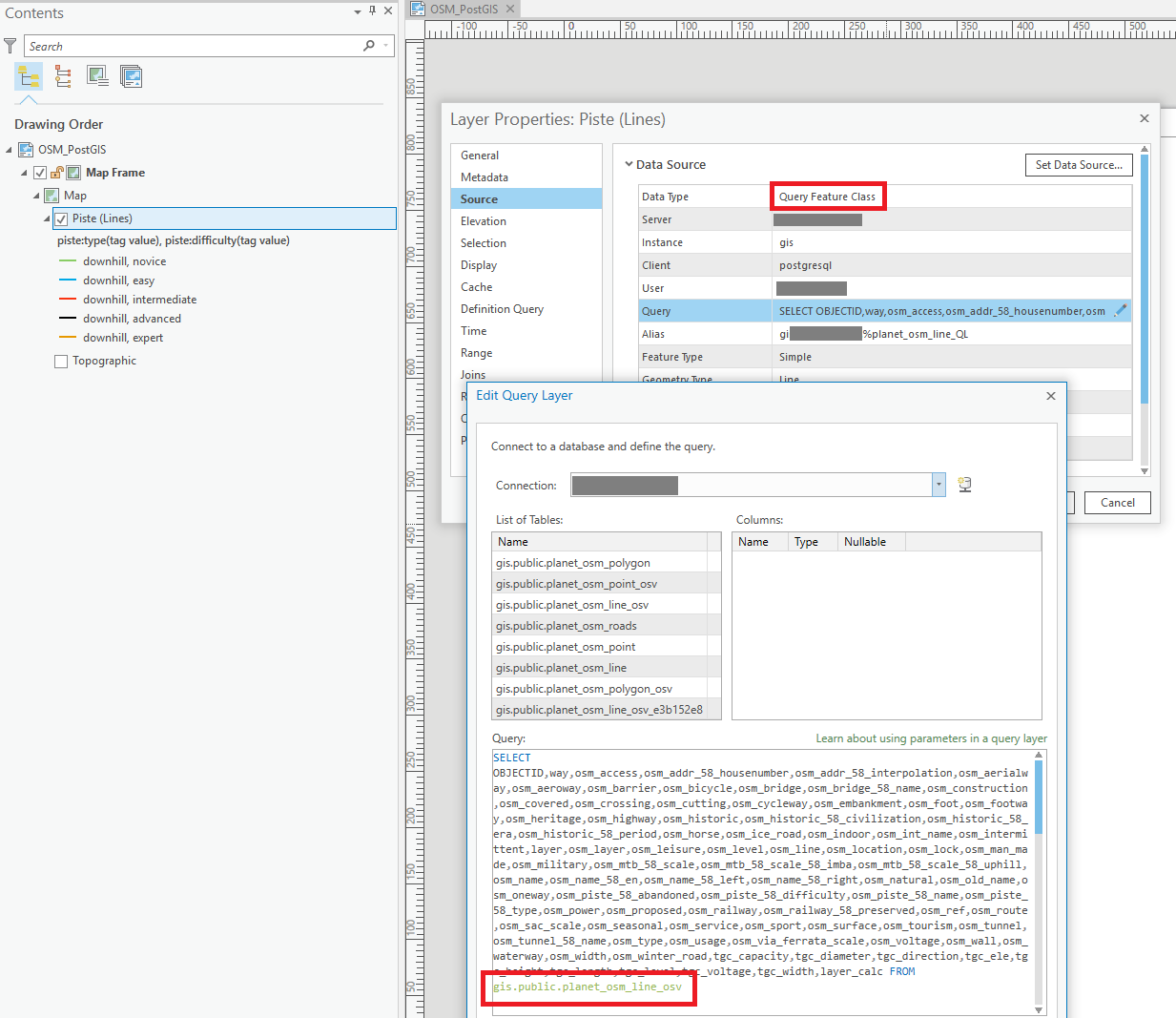
The Definition Query set on the layer, see image, references an indexed field, osm_piste_58_type:
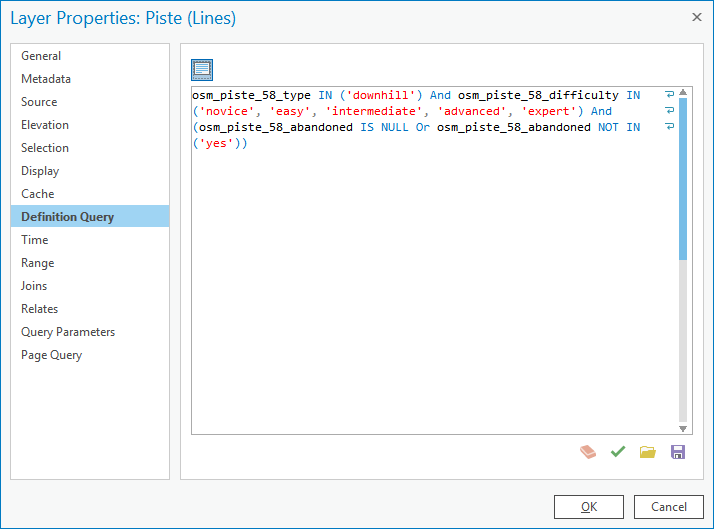
If I insert the Definition Query in DBeaver IDE, and prepend it with the necessary SELECT...FROM... that is missing in the Definition Query itself, and run an execution plan, the query runs in less than 3 seconds (2163ms) and returns 38697 rows, so just under 40k records. The execution plan shows the database correctly using the available index ("Index Scan"):

The problem:
When I attempt to open the Attribute Table in Pro by right clicking the layer and choosing "Attribute Table", Pro, instead of showing the records near instantly as it should based on the 3 seconds execution plan, instead takes > half an hour to open the Attribute Table. This is the time needed for a full table scan. When it is finished, it does show the proper 40k records, so the final selection was made.
When I enable logging in PostgreSQL and check the created log, I can see the SQL generated the moment I open the attribute table. Much to my surprise, even though the Query Layer had a Definition Query set, this Definition Query is not set on the SQL send to the database to restrict the binary cursor being created, as a consequence, the entire table seems subsequently to start being scanned in chunks of 1000 records, see the FETCH FORWARD 1000 statements in the log. This seems to go on the entire half hour, until a full table scan of all the millions of records is done, and the final table is created. As I wrote above, the final result in the Attribute Table, does correspond to the Definition Query, and is only the 38697 rows.
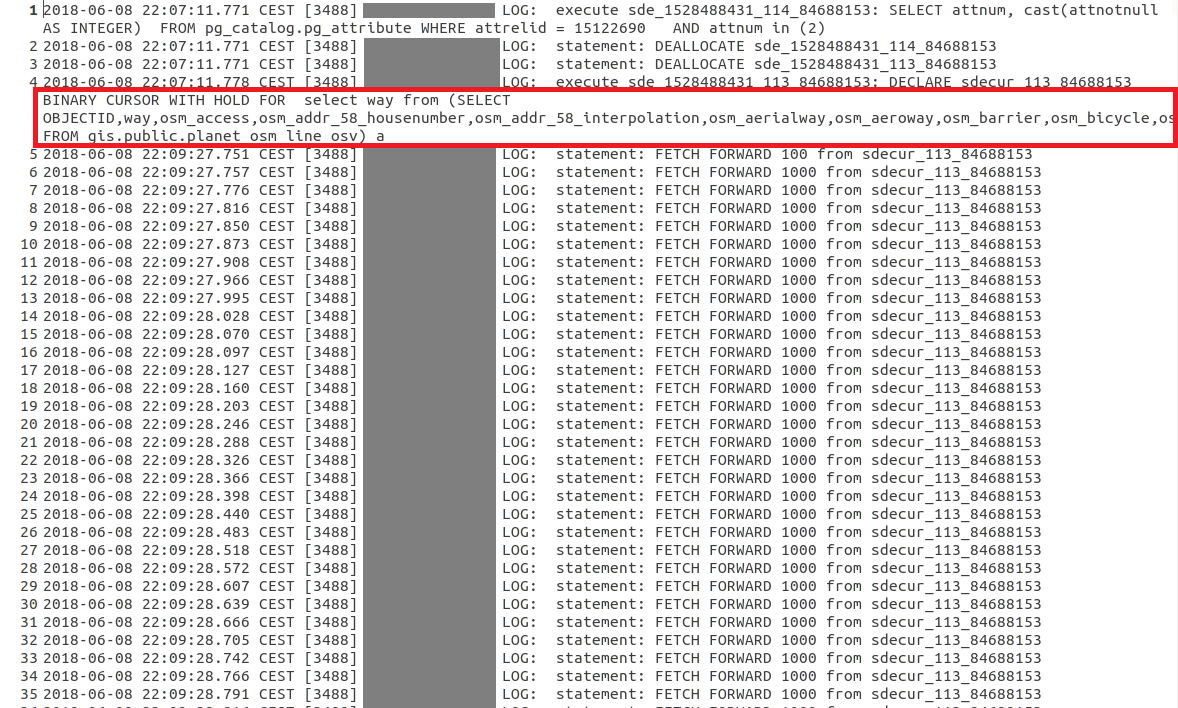
To inspect this better, I copied both the cursor statement that is initially used to create the layer (which is fast!), and compared it with the above statement representing the opening of the Attribute Table in an OpenOffice document, see the below screenshots. Notice how the first screenshot, which represent the moment the layer is created when the Pro Map document is opened and the TOC layer generated, does contain the Definition Query in the WHERE statement. This WHERE statement is omitted though, in the second screenshot that represents the opening of the Attribute Table:
- Creation of Query Layer: 
- Opening Attribute Table:

Am I missing something here, or fundamentally misunderstanding what is going on and misinterpreting this data? Why is there no WHERE statement submitted to the database when opening the Attribute Table of a (Query) Layer?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Marco:
Thank you for the very detailed and informative response about the view for the query layer.
In my environment I can add a spatially enabled table from an Oracle database and ArcMap automatically recognizes a long integer field as an OBJECT ID data type so I do not get a dialog box asking for this type of field. When I look at the properties of this field in ArcCatalog it is displayed as Object ID.
In my environment I also added a view composed of this spatially enabled table from an Oracle database and ArcMap does not automatically recognizes a long integer field as an OBJECT ID data type so I do get a dialog box asking for this type of field (I'm using the same field as the table but ArcMap is treating the view differently). When I look at the properties of this field in ArcCatalog it is displayed as Long Integer. This difference creates issues where ArcMap sends requests to the Oracle database as important components are being dropped such as where clause and sort by.
Would you be able to test this scenaro on your Postgres database to see if the same phenomenon is occrring?
In addition here is some information from an ESRI technical support specialist who is working on this case:
As a recap of our most recent call:
I created a table for simple point data, assigned the OBJECTID field as NUMBER(38) field type during initial creation in Oracle from a SQL query. This gets casted as NUMBER(38,0) at the oracle table level. When I create a view from that table directly in oracle (SELECT *), the OBJECTID field in the view is assigned NUMBER(38).
When I compare the view and the table in ArcCatalog - the table's NUMBER(38,0) field is interpreted as an "Object ID" field. The view's NUMBER(38) field is interpreted as a long integer.
Even if I cast the precision when creating the view OBJECTID still gets assigned as NUMBER(38):
CREATE VIEW city_points_VIEW_num38_0 AS
SELECT CAST("OBJECTID" AS NUMBER(38,0)) AS "OBJECTID","CITY_NAME","LATITUDE","LONGITUDE","SHAPE"
FROM city_points
If this were a geodatabase, we would be able to register the view with the geodatabase and the OBJECTID field would be considered as an "Object ID" field rather than interpreting and referencing a long integer field as an Object ID field. This seems to be a limitation of the software when interpreting unique ID fields from an oracle view from a spatially enabled table, and would be most likely a defect.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Marco:
Have you received any feedback from ESRI on this issue in Pro?
Also, have you upgraded to Pro 2.2 to see if this issue has been resolved?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Ah, yes, sorry, I have been to busy with other stuff to get back on this.
Yes, I did get an official response through tech support / ESRI Netherlands. It basically boils down to a confirmation of my suspicions, and especially that Pro starts to automatically calculate the spatial extent in the background, pulling all records from the database corresponding to the Query Layer's SQL statement, whenever it hasn't yet done this and it starts to be relevant to Pro. E.g. the moment a Query Layer is created or its attribute table opened. With the current implementation, this can be a hugely costly operation against (ultra) large databases and with specific queries selecting many records (or all like when dragging & dropping a database table in the TOC).
They basically confirmed this observation also:
"As a consequence, I am now getting convinced that the behavior I am seeing is actually NOT A BUG, but a change in how ESRI decided to handle Query Layers and specifically the calculation of the spatial extent of such Query Layer."
meaning especially that ArcMap has a clear visible point in time when the Query Layer's Spatial Extent is calculated with a dialog popping up, with an override option right there in the dialog, while Pro more hides this (although you can set extent in a Query Layer's properties when the layer is already in the TOC) and has this triggered automatically in the background.
Finally, they recommended to create an ArcGIS Idea for potential changes to the Query Layer handling. I have some ideas based on all of this, and indeed intend to create one when I have some time. When I do, I will post a link here for all of you to start voting it up...
Last remark: I also re-discovered another Help page with an option that I didn't yet explore, but think may be of help to some and could potentially speed up especially the opening of attribute tables of Query Layer's in case of very large tables:
Define parameters in a query layer—Query layers | ArcGIS Desktop
I already read before about query layer parameter's but hadn't yet properly read up about the view_extent option, which seems to be a way to limit your attribute table's records to only those records visible in the current view's extent. If this functions properly, this could considerably enhance the time needed to open attribute tables of query layers based on large database tables. Of course, this only really works when being zoomed in, and you won't see all records then, but that is not really relevant in the context of >100M record tables...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have now finally found the time to create an ArcGIS Idea with some of my ideas about what needs to change to the Query Layer framework to make it really usable against (ultra) large databases:
https://community.esri.com/ideas/15422
Vote it up!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you for all these details Marco. It seems like your idea was archived or deleted. Have you heard anything further on this issue?
- « Previous
- Next »
- « Previous
- Next »