- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Geodatabase Questions
- :
- Bulk Insert Head Scratcher
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Bulk Insert Head Scratcher
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So I'm following https://community.esri.com/people/Christian_Wells-esristaff/blog/2014/10/01/iterating-insert-geometr... which I have used many many many many mnay many many times in the past to do bulk inserts from non-SDE sources into a SDE feature class. Now I'm on SDE 10.7.x and using the following:
DECLARE @RowCount INT
SET @RowCount = (SELECT COUNT(*) FROM [db1].[dbo].source_table WHERE FCSUBTYPE = 22 OR FCSUBTYPE = 23 OR FCSUBTYPE = 24 )
DECLARE @iterator INT
SELECT @iterator = MIN(OBJECTID) FROM [db1].[dbo].source_table WHERE FCSUBTYPE = 22 OR FCSUBTYPE = 23 OR FCSUBTYPE = 24
WHILE @iterator is NOT NULL
BEGIN
DECLARE @id as integer
EXEC dbo.next_rowid 'dbo', 'dest_table', @id OUTPUT;
INSERT INTO [db2].[dbo].[dest_table]([OBJECTID],[CREATEDATE],[EDITDATE],[MAPMETHOD],[MAPSOURCE],[SOURCEDATE],[XYACCURACY],[NOTES],[GlobalID],[COUNTY],[MANAGEMENTZONE],[QUADNAME],
[ROAD],[PARKDISTRICT],[STATE],[WATERSHED],[TRAIL],[X_COORD],[Y_COORD],[LAT],[LON],[ELEVATION],[LOC_NAME],[FC_SUBTYPE],[LOCATION_DESCRIPTION],[Shape],[STREAMNAME],[YEAR],[VALID_RESULT],
[PUBLICDISPLAY],[DATAACCESS],[UNITCODE],[UNITNAME],[REGIONCODE],[CREATEUSER],[EDITUSER])
SELECT @id, [CREATE_DATE],[EDITDATE],CASE WHEN [MAPMETHOD] ='HDIG' THEN 'Digitized' WHEN [MAPMETHOD] ='UNKN' THEN 'Unknown' WHEN [MAPMETHOD] ='AGPS' THEN 'Autonomous GPS' WHEN [MAPMETHOD] ='DERV' THEN 'Feature Extraction' WHEN [MAPMETHOD] ='' THEN 'Unknown' WHEN [MAPMETHOD] IS NULL THEN 'Unknown' END AS [MAPMETHOD],
[MAPSOURCE], [SOURCEDATE],CASE WHEN [HERROR] = '>10m <=100m' THEN '>=14m' WHEN [HERROR] = '>1m <=5m' THEN '>=1m and <5m' WHEN [HERROR] = '>5000m' THEN 'Scaled' WHEN [HERROR] = '>5m <=10m' THEN '>=5m and <14m' WHEN [HERROR] = 'Unknown' THEN 'Unknown' WHEN [HERROR] = '' THEN 'Unknown' WHEN [HERROR] IS NULL THEN 'Unknown'END AS [XYACCURACY],
[NOTES],[GIS_LOCATION_ID],[COUNTY],[MANAGEMENTZONE],[QUADNAME],[ROAD],[PARKDISTRICT],[STATE],[WATERSHED],[TRAIL],[X_COORD],[Y_COORD],[LAT],[LON],[ELEVATION],[LOC_NAME],[FCSUBTYPE],[LOCATIONDESCRIPTION],
[SHAPE],[STREAMNAME],[YEAR], CASE WHEN [VALID] = 'Certified' THEN 'Certified' WHEN [VALID] = '' THEN 'Raw' WHEN [VALID] IS NULL THEN 'Raw' END AS [VALID_RESULT],'No Public Map Display' AS [PUBLICDISPLAY],
'Secure Access Only' AS [DATAACCESS], 'GRSM' AS [UNITCODE], 'Great Smoky Mountains National Park' AS [UNITNAME], 'SER' AS [REGIONCODE], 'GRSM User' AS [CREATEUSER], 'GRSM User' AS [EDITUSER]
FROM [db1].[dbo].source_table WHERE FCSUBTYPE = 22 OR FCSUBTYPE = 23 OR FCSUBTYPE = 24 AND objectid = @iterator;
SELECT @iterator= MIN(OBJECTID) FROM [db1].[dbo].source_table WHERE @iterator < OBJECTID AND FCSUBTYPE = 22 OR FCSUBTYPE = 23 OR FCSUBTYPE = 24
ENDWhich results in the whole thing looping as many times as there are objects meeting the where clause. E.g it's selecting all 566 rows, 566 times.
Christian Wells This leads me to believe that how a new OID is generated has changed since that 2014 blog post?
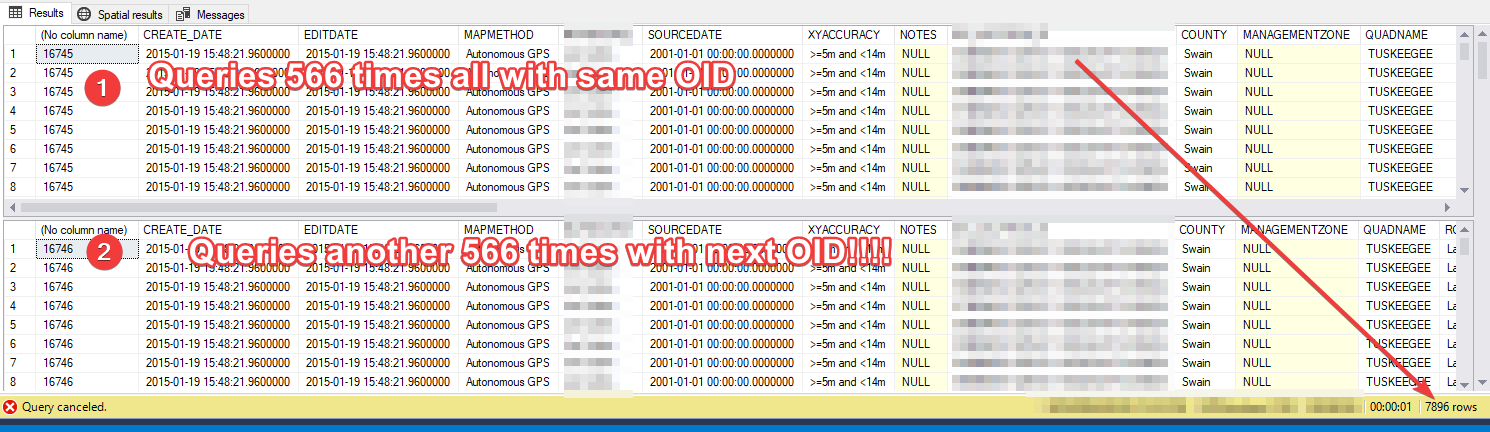
I save all my SQL code, so I opened up the last one I ran successfully on a 10.5.x SDE, and yup, no change other than the where clauses (which I removed to see if that was the cause, which they are not).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for sharing your findings. Let me take a look at 10.7 and get back to you. What version of SQL Server are you using?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
10.7.1.2.4, SQL 2014 ENT, Storage Type Geography. What's different from your post is, my source and destination tables are in different database........
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here is my testing:
- Create db1 as an Enterprise Geodatabase (same instance)
- Create db2 as a standalone database (same instance)
- Create a spatial table in db2 with 100 records using Create Random Points
- Fields (OID, Shape)
- Create an empty feature class in db1 with the same schema
- Fields (OID, Shape)
- Run the following code:
-- Get the number of rows in the looping table DECLARE @RowCount INT SET @RowCount = (SELECT COUNT(*) FROM [db1].[dbo].[ORIGINFC]) -- Declare an iterator DECLARE @iterator INT -- Initialize the iterator SELECT @iterator = MIN(OID) FROM db1.dbo.ORIGINFC -- Loop through the rows of a table WHILE @iterator is NOT NULL BEGIN DECLARE @id as integer -- Get OBJECTID value EXEC sde.next_rowid 'sde', 'destinationfc', @id OUTPUT; -- Insert the data while casting the points geometry INSERT INTO SDE.destinationfc (oid, shape) SELECT @id,Shape FROM db1.dbo.ORIGINFC where OID = @iterator; -- Update the iterator value SELECT @iterator= MIN(OID) FROM db1.dbo.ORIGINFC WHERE @iterator < OID END - Query the destination table count which should equal 100
I ran this with a 10.7.1 EGDB and SQL Server 2014 (12.0.6108.1) but I don't see duplicate records in the destination feature class.
Could you repeat my steps with a generic feature class and share the results you receive? I know this is a really simplified example but maybe it will point us towards the cause.