- Home
- :
- All Communities
- :
- Industries
- :
- Electric
- :
- Electric Questions
- :
- Re: Check for Duplicate AssetID Values with Arcade
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Check for Duplicate AssetID Values with Arcade
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi,
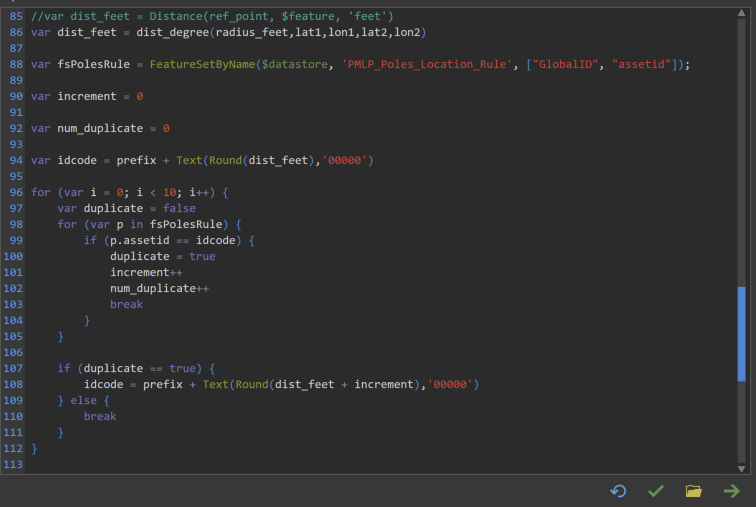
I have an Arcade rule that generates an assetid when a point is inserted. This code is generated by measuring and rounding the distance, in feet, of the inserted point feature from a fix reference point. The process could generate repeated assetids for point features that are located at the same distance from the reference point.
Therefore, I'm trying to compare the new assetid with the existing ones using 2 for loops, with the code shown below.
The code tries to compare the new assetid against all the existing (inner loop), if there is a duplicate then change the new assetid, compare again, and if there is no duplicate then exit the outer loop.
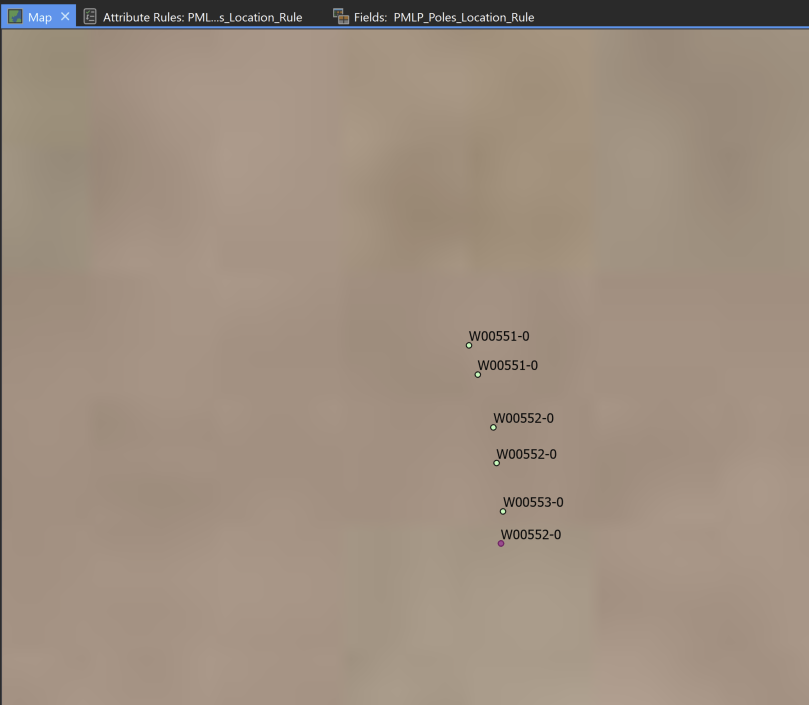
The rule is not work. It never enters the if statement inside the inner loop, see code below. I purposely created duplicate assetids, as you can see in the pic below. Tried adding a point and saving the edit, then adding another one and saving again, in case the Arcade rule was not seeing the repeated assetid until the edits have been saved; but that didn't work.
Is there something wrong on the code or there is a better and more efficient way to do this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Billy Guerrero ,
Just wondering, but why are you generating an assetid based on the distance in feet from a fixed point? Normally, when automatically creating an assetid, the recommendation is using the NextSequenceValue function in combination with a sequence defined in the database (Create Database Sequence—Data Management toolbox | Documentation ).
You also only showed part of the expression and I did not see any part where you return a value. Also, when the data volume starts growing, looping through the entire data will have an impact on performance. If you do need to use the distance for the assetid, use a filter first to only filter those that start with the same id and use the count to generate the new id and not a for loop. Also when there are 10 or more points at the same distance you will run into duplicate codes again with your code.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Xander,
When we were reviewing the different ways to create an assetid we tested the NextSequenceValue option, but we want to have an assetid code that would have some meaning, not just any random number. Our new assetid code has the information about the district where the asset it located and the distance from a reference point. Maybe you would wonder why someone would need that since you can get that information from the map, but when you are jumping from paper maps to digital maps with the utility network, this king of transition is not easy for everybody. Our current assetid system for poles is not database friendly (a lot of duplicate numbers) but it's very intuitive for the people in the field. With our implementation of the utility network we decided to change our current assetid system, but we want to replace it with something that will convey some information for the people in the field when they are not using the digital map.
I share your concern about performance with the nested for-loops and growing data volume, that's why I was wondering if there was another method. Right now we have less than 10K poles, but we don't expect that that number will increase beyond 10K. Yesterday, I came to the same conclusion that you are suggesting and this is the new rule:

The rule performance, in the test environment, with the ~10K poles on the map is almost the same that we experience when the rule was not checking for duplicate values, so it looks like performance won't be an issue. But we still have to test it in the production environment, where we are adding the poles with a group template that includes other features (lines, electric attachment and street lights)
Since the assetid generated by the rule includes a "prefix" (pole district), I'm thinking that maybe filtering the pole class by the "prefix", to reduce the dataset being tested for duplicates, could make the rule more efficient. What do you think? Also, I still wonder why the first rule didn't work, even if it's not very efficient.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Billy Guerrero ,
I can imagine that changing from paper maps to the Utility Network is a huge leap in digital transformation and will requiere proper change management for those that will interact with the UN. However, the benefits that you will have as organization are priceless. How far are you in the process of implementing the UN?
I just looked at the 2nd expression you shared and there are a couple of questions and comments I have:
- I see that you check at the end if the ID is not already set. You might want to do this at the start to avoid processing when it is not necessary
- This also makes me wonder. What trigger did you define fro this attribute rule? If it is also trigger on update, and a point is moved to another area, the code would change, no only the prefix but also the distance. If you update the code based on these new aspects, you might create a hole in the sequence. Update triggers will need a different way of processing and some considerations of what you want to happen. I have a blog (in Spanish, sorry) of how this could be handled here: CRU2020 - Track Servicios Públicos - Arcade y Reglas de Atributos (although it uses database sequences)
- I also notice that the format of the id has changed. You seem to increment the distance when a distance is "already in use". Is that correct? I thought that you were creating a postfix that will increment based on the number of id's that are already in use.
When I ignore an updates and changes in distance and the prefix, I would think that the logic could be something like this:
// check first if the id is already set
var prefix = "W"; // assumably is extracted from a polygon fs
var dist_feet = 551; // dist_degree(...);
var fsPolesRules = FeatureSetByName(...);
var idcode = prefix + Text(Round(dist_feet), '00000');
// create a sql to query all features withe the same start of the assetid
var sql = "assetid LIKE '" + idcode + "%'";
// filter the fs
var fs_filtered = Filter(fsPolesRules, sql);
// use the count to create a new code
var cnt = Count(fs_filtered);
idcode = prefix + Text(Round(dist_feet), '00000') + "-" + Text(cnt+1);
// this will gloriously fail when existing points get moved
// and the id is adjusted to those changes
// return the result- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Xander,
As you mentioned, we agree that the benefits of the UN worth the effort. At this point, we have created our data dictionary, selected the Tiers, AG/AT (AssetGroup/AssetType), and related tables that we need. Also, we deployed the Electric Utility Network asset package with the sample data (as a testing environment) and deployed the same asset package with the schema only and the special reference changed to our location (our project environment). Since we don't have GIS quality data to import directly to the UN, we have to basically draw the network one pole at a time, with the help of group and preset templates. But we have decided to start by creating all the substations, then the interconnecting lines between them, and finally the distribution circuits and the other assets (transformers, junction box, street lights, etc) Also we're are taking our time to clean and transform the data that will be added to the UN, which will be added to the features using Arcade rules.
Thanks again for your comments and suggestions. Here are my comments:
- Your first point is very valid. I'll adjust the script accordingly.
- For you second point, the rule is triggered by insertion. The type of assets (poles, junction box and hanholes) that will be using this rule to generate their assetid are not usually moved, so they will have that number until they are removed from the field. In reality, this id is acting more as a location id than an asset id, because the id will survive the asset. If a pole is replace at the same location, the new pole will get the same assetid. We know that this is not ideal from the point of view of asset management, but we will address this with an asset management system link to the GIS. Regarding your blog: Aqui se hable español. Lo leere con detenimiento, sole le di una hojeada.
- I'm incrementing the distance, because we want to keep the id length to 6 characters. I was using the postfix as a print to console alternative. If Arcade had a development environment with step-by-step debugging and variables inspection, it would be easier to debug. I thinking something like what MS Office has for VBA.
Regards.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
To help with debugging, use pop ups in ArcGIS Pro. That profile supports a lot of the same functions as attribute rules. This can help track down coding issues.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Good to know. Thanks for the suggestion.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Why not switch to generating it from ObjectID
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Robert,
What would be the benefit of doing what you propose?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
It would eliminated the need for this question. ObjectID will be unique for any new feature created in the feature class