- Home
- :
- All Communities
- :
- Developers
- :
- Developers - General
- :
- Developers Questions
- :
- Re: How to select points within a boundary layer a...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to select points within a boundary layer and displaying the table of selected points in Data Driven Pages using Python?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dear sir,
hope you are fine. I require your little favor. Please don't mind, I'm fairly new to development. Can you please rectify my code. I just tell you the detail about.
I am working on MapBook via DDP. I have to select points which are within the boundary layer of current page and then want to display the table in maps. I am done with other work just facing problem with selection.
I have a layer named "IndexLayer" which contains the boundaries of cities under the attribute "Division". There is another layer which contains points, that is named "tlsf". I want to select the points which are within the opened page boundary but as per my script, all the points are selected and displayed in the table. I am posting python code here. Please don't mind. Is it possible if I can get your email address? The code is given by:
import arcpy, os, sys
relpath = os.path.dirname(sys.argv[0])
division = arcpy.GetParameterAsText(0)
#Reference MXD and layers
mxd = arcpy.mapping.MapDocument(relpath + r"\map.mxd")
transferStation = arcpy.mapping.ListLayers(mxd, "tlsf")[0]
#Reference page layout elements
for elm in arcpy.mapping.ListLayoutElements(mxd):
if elm.name == "bar1": bar1 = elm
if elm.name == "bar2": bar2 = elm
if elm.name == "bar3": bar3 = elm
if elm.name == "bar1txt": bar1txt = elm
if elm.name == "bar2txt": bar2txt = elm
if elm.name == "bar3txt": bar3txt = elm
if elm.name == "NoGrowth": noGrowth = elm
if elm.name == "horzLine": horzLine = elm
if elm.name == "vertLine": vertLine = elm
if elm.name == "cellTxt": cellTxt = elm
if elm.name == "headerTxt": headerTxt = elm
#Clean-up before next page
for elm in arcpy.mapping.ListLayoutElements(mxd, "GRAPHIC_ELEMENT", "*clone*"):
elm.delete()
for elm in arcpy.mapping.ListLayoutElements(mxd, "TEXT_ELEMENT", "*clone*"):
elm.delete()
noGrowth.elementPositionX = -3
cellTxt.elementPositionX = -3
headerTxt.elementPositionX = -3
horzLine.elementPositionX = -3
vertLine.elementPositionX = -3
#Reference DDP object and set appropriate page
ddp = mxd.dataDrivenPages
ddp.currentPageID = ddp.getPageIDFromName(division)
#Graphic table variable values
tableHeight = 3.0
tableWidth = 4.5
headerHeight = 0.2
rowHeight = 0.15
upperX = 11
upperY = 3.2
#Build selection set
divisionName = ddp.pageRow.Division
arcpy.AddMessage("Processing: " + division)
with arcpy.da.SearchCursor("IndexLayer", ("Division")) as cursor:
for row in cursor:
exp = 'Division = divisionName'.format(row[0])
arcpy.SelectLayerByAttribute_management("IndexLayer", "NEW_SELECTION", exp)
# selection
arcpy.SelectLayerByLocation_management("transferStation", "INTERSECT", "NEW_SELECTION", "IndexLayer4")
arcpy.Select_analysis(transferStation, "in_memory\IndexLayer4", '')
numRecords = int(arcpy.GetCount_management("in_memory\IndexLayer4").getOutput(0))
#Sort selection
#Show selected features
#Add note if there are no counties > 100%
if numRecords == 0:
noGrowth.elementPositionX = 3
noGrowth.elementPositionY = 2
else:
#if number of rows exceeds page space, resize row height
if ((tableHeight - headerHeight) / numRecords) < rowHeight:
headerHeight = headerHeight * ((tableHeight - headerHeight) / numRecords) / rowHeight
rowHeight = (tableHeight - headerHeight) / numRecords
#Set and clone vertical line work
vertLine.elementHeight = (headerHeight) + (rowHeight * numRecords)
vertLine.elementPositionX = upperX
vertLine.elementPositionY = upperY
temp_vert = vertLine.clone("_clone")
temp_vert.elementPositionX = upperX + 1.5
temp_vert = vertLine.clone("_clone")
temp_vert.elementPositionX = upperX + 2.5
temp_vert = vertLine.clone("_clone")
temp_vert.elementPositionX = upperX + 3.5
temp_vert = vertLine.clone("_clone")
temp_vert.elementPositionX = upperX + 4.5
#Set and clone horizontal line work
horzLine.elementWidth = tableWidth
horzLine.elementPositionX = upperX
horzLine.elementPositionY = upperY
horzLine.clone("_clone")
horzLine.elementPositionY = upperY - headerHeight
print numRecords
y=upperY - headerHeight
for horz in range(1, numRecords+1):
y = y - rowHeight
temp_horz = horzLine.clone("_clone")
temp_horz.elementPositionY = y
#Set header text elements
headerTxt.fontSize = headerHeight / 0.0155
headerTxt.text = "Name"
headerTxt.elementPositionX = upperX + 0.75
headerTxt.elementPositionY = upperY - (headerHeight / 2)
newFieldTxt = headerTxt.clone("_clone")
newFieldTxt.text = "Type"
newFieldTxt.elementPositionX = upperX + 2
newFieldTxt = headerTxt.clone("_clone")
newFieldTxt.text = "Longitude"
newFieldTxt.elementPositionX = upperX + 2.75
newFieldTxt = headerTxt.clone("_clone")
newFieldTxt.text = "Latitude"
newFieldTxt.elementPositionX = upperX + 3.25
#Set and clone cell text elements
cellTxt.fontSize = rowHeight / 0.0155
y = upperY - headerHeight
rows = arcpy.SearchCursor("in_memory\IndexLayer4")
for row in rows:
x = upperX + 0.05
col1CellTxt = cellTxt.clone("_clone")
col1CellTxt.text = row.getValue("Name")
col1CellTxt.elementPositionX = x
col1CellTxt.elementPositionY = y
col2CellTxt = cellTxt.clone("_clone")
col2CellTxt.text = row.getValue("Type")
col2CellTxt.elementPositionX = x + 1.75
col2CellTxt.elementPositionY = y
col3CellTxt = cellTxt.clone("_clone")
col3CellTxt.text = str(round(row.getValue("Longitude"), 2))
col3CellTxt.elementPositionX = x + 3
col3CellTxt.elementPositionY = y
col4CellTxt = cellTxt.clone("_clone")
col4CellTxt.text = str(round(row.getValue("Longitude"), 2))
col4CellTxt.elementPositionX = x +4.75
col4CellTxt.elementPositionY = y
y = y - rowHeight
arcpy.Delete_management("in_memory\IndexLayer4")
arcpy.Delete_management("in_memory\IndexLayer4")
arcpy.mapping.ExportToPDF(mxd, relpath + "\\" + division + ".pdf")
os.startfile(relpath + "\\" + division + ".pdf")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You can use the Search Cursor in the python module named arcpy to query the feature layer.
You can also use the result from the Search Cursor with Make Feature Layer tool to create a new Feature Layer.
For zooming up to certain extent here is the StackOverflow Article where you can set the extent of the data frame.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello Farhan,
I think Gurminder's advice is quite good. If you have access to the Esri Production Mapping extension, it looks like you can use the dynamic table layout element to configure and produce the table according to these guidelines.
Once you get the dynamic table set up in your layout, here is some code that may help you get started with producing your maps:
import arcpy
# create mxd and data frame objects
mxd = arcpy.mapping.MapDocument("CURRENT")
df = mxd.activeDataFrame
# create a counter that you can use to name your output PDFs
counter = 1
# loop through the cities layer with a search cursor
with arcpy.da.SearchCursor("cities_layer", ("OBJECTID")) as cursor:
for row in cursor:
# select the city
exp = 'OBJECTID = {}'.format(row[0])
arcpy.SelectLayerByAttribute_management("cities_layer", "NEW_SELECTION", exp)
# zoom to the city
df.zoomToSelectedFeatures()
arcpy.RefreshActiveView()
# select the population points within the current city
arcpy.SelectLayerByLocation_management("population_points", "INTERSECT", "NEW_SELECTION", "cities_layer")
# export the map to PDF and increment the counter
arcpy.mapping.ExportToPDF(mxd, "CityPDF_{}".format(str(counter)))
counter += 1Hope that helps! Good luck.
Micah
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you sir for your kindness, I found it really helpful.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
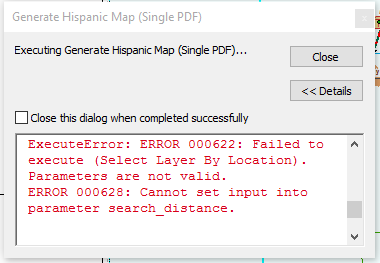
0-Dear sir,
I am hopeful that you will be fine. Please look at the problem I am pointing at:
I am working on mapbook and data driven is applied on a layer named "IndexLayer" against "Divsion" field. This layer contains the boundaries of Divisions (Division is an administrative distribution, which contains more than one city in my country). I have some point which are placed in a layer named, "tlsf". At the data driven pages, on the each division page, I want to select the point which lie into the corresponding boundary and then want them to display on the map. I have worked on the table. The problem I am getting is a the selection end. The received error is attached in the screen shot. I am also pasting the code here. I require your kindness. Thanks
import arcpy, os, sys
relpath = os.path.dirname(sys.argv[0])
division = arcpy.GetParameterAsText(0)
#Reference MXD and layers
mxd = arcpy.mapping.MapDocument(relpath + r"\map.mxd")
transferStation = arcpy.mapping.ListLayers(mxd, "tlsf")[0]
#Reference page layout elements
for elm in arcpy.mapping.ListLayoutElements(mxd):
if elm.name == "bar1": bar1 = elm
if elm.name == "bar2": bar2 = elm
if elm.name == "bar3": bar3 = elm
if elm.name == "bar1txt": bar1txt = elm
if elm.name == "bar2txt": bar2txt = elm
if elm.name == "bar3txt": bar3txt = elm
if elm.name == "NoGrowth": noGrowth = elm
if elm.name == "horzLine": horzLine = elm
if elm.name == "vertLine": vertLine = elm
if elm.name == "cellTxt": cellTxt = elm
if elm.name == "headerTxt": headerTxt = elm
#Clean-up before next page
for elm in arcpy.mapping.ListLayoutElements(mxd, "GRAPHIC_ELEMENT", "*clone*"):
elm.delete()
for elm in arcpy.mapping.ListLayoutElements(mxd, "TEXT_ELEMENT", "*clone*"):
elm.delete()
noGrowth.elementPositionX = -3
cellTxt.elementPositionX = -3
headerTxt.elementPositionX = -3
horzLine.elementPositionX = -3
vertLine.elementPositionX = -3
#Reference DDP object and set appropriate page
ddp = mxd.dataDrivenPages
ddp.currentPageID = ddp.getPageIDFromName(division)
#Graphic table variable values
tableHeight = 3.0
tableWidth = 2.5
headerHeight = 0.2
rowHeight = 0.15
upperX = 2.8
upperY = 3.2
#Build selection set
divisionName = ddp.pageRow.Division
arcpy.AddMessage("Processing: " + division)
with arcpy.da.SearchCursor("IndexLayer", ("Division")) as cursor:
for row in cursor:
exp = 'Division = division'.format(row[0])
arcpy.SelectLayerByAttribute_management("IndexLayer", "NEW_SELECTION", exp)
# selection
arcpy.SelectLayerByLocation_management("transferStation", "WITHIN", "NEW_SELECTION", "IndexLayer")
arcpy.Select_analysis(transferStation, "in_memory\select1", '')
numRecords = int(arcpy.GetCount_management("in_memory\select1").getOutput(0))
#Sort selection
#Show selected features
#Add note if there are no counties > 100%
if numRecords == 0:
noGrowth.elementPositionX = 3
noGrowth.elementPositionY = 2
else:
#if number of rows exceeds page space, resize row height
if ((tableHeight - headerHeight) / numRecords) < rowHeight:
headerHeight = headerHeight * ((tableHeight - headerHeight) / numRecords) / rowHeight
rowHeight = (tableHeight - headerHeight) / numRecords
#Set and clone vertical line work
vertLine.elementHeight = (headerHeight) + (rowHeight * numRecords)
vertLine.elementPositionX = upperX
vertLine.elementPositionY = upperY
temp_vert = vertLine.clone("_clone")
temp_vert.elementPositionX = upperX + 1.5
temp_vert = vertLine.clone("_clone")
temp_vert.elementPositionX = upperX + 2.5
#Set and clone horizontal line work
horzLine.elementWidth = tableWidth
horzLine.elementPositionX = upperX
horzLine.elementPositionY = upperY
horzLine.clone("_clone")
horzLine.elementPositionY = upperY - headerHeight
print numRecords
y=upperY - headerHeight
for horz in range(1, numRecords+1):
y = y - rowHeight
temp_horz = horzLine.clone("_clone")
temp_horz.elementPositionY = y
#Set header text elements
headerTxt.fontSize = headerHeight / 0.0155
headerTxt.text = "Name"
headerTxt.elementPositionX = upperX + 0.75
headerTxt.elementPositionY = upperY - (headerHeight / 2)
newFieldTxt = headerTxt.clone("_clone")
newFieldTxt.text = "Type"
newFieldTxt.elementPositionX = upperX + 2
newFieldTxt = headerTxt.clone("_clone")
newFieldTxt.text = "Longitude"
newFieldTxt.elementPositionX = upperX + 2
newFieldTxt = headerTxt.clone("_clone")
newFieldTxt.text = "Latitude"
newFieldTxt.elementPositionX = upperX + 2
#Set and clone cell text elements
cellTxt.fontSize = rowHeight / 0.0155
y = upperY - headerHeight
rows = arcpy.SearchCursor("in_memory\select1")
for row in rows:
x = upperX + 0.05
col1CellTxt = cellTxt.clone("_clone")
col1CellTxt.text = row.getValue("Name")
col1CellTxt.elementPositionX = x
col1CellTxt.elementPositionY = y
col2CellTxt = cellTxt.clone("_clone")
col2CellTxt.text = row.getValue("Type")
col2CellTxt.elementPositionX = x + 1.75
col2CellTxt.elementPositionY = y
col3CellTxt.text = str(round(row.getValue("Longitude"), 2))
col3CellTxt.elementPositionX = x + 3
col3CellTxt.elementPositionY = y
col4CellTxt.text = str(round(row.getValue("Longitude"), 2))
col4CellTxt.elementPositionX = x +4.75
col4CellTxt.elementPositionY = y
y = y - rowHeight
arcpy.mapping.ExportToPDF(mxd, relpath + "\\" + division + ".pdf")
os.startfile(relpath + "\\" + division + ".pdf")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You should really repost the code using these instrucciones: https://community.esri.com/docs/DOC-8691-posting-code-with-syntax-highlighting-on-geonet . The way you posted the code makes it very hard to read since all the important indentations are removed and the code is no longer valid.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dear sir, hope you are fine. I require your little favor. Please don't mind, I'm fairly new to development. Can you please rectify my code. I just tell you the detail about.
I am working on MapBook via DDP. I have to select points which are intersecting the boundary layer of current page and then want to display the table in maps. I am done with other work just facing problem with selection.
I have a layer named "IndexLayer" which contains the boundaries of cities under the attribute "Division". There is another layer which contains points, that is named "tlsf". I want to select the points which are intersecting the opened page boundary but as per my script, all the points are selected and displayed in the table. I am posting python code here. I tried to write the code under suggested format but with very sorry I coudn't write in that way. Please don't mind. Is it possible if I can get your email address? The code is given by
#
import arcpy, os, sys
relpath = os.path.dirname(sys.argv[0])
division = arcpy.GetParameterAsText(0)
#Reference MXD and layers
mxd = arcpy.mapping.MapDocument(relpath + r"\map.mxd")
transferStation = arcpy.mapping.ListLayers(mxd, "tlsf")[0]
#Reference page layout elements
for elm in arcpy.mapping.ListLayoutElements(mxd):
if elm.name == "bar1": bar1 = elm
if elm.name == "bar2": bar2 = elm
if elm.name == "bar3": bar3 = elm
if elm.name == "bar1txt": bar1txt = elm
if elm.name == "bar2txt": bar2txt = elm
if elm.name == "bar3txt": bar3txt = elm
if elm.name == "NoGrowth": noGrowth = elm
if elm.name == "horzLine": horzLine = elm
if elm.name == "vertLine": vertLine = elm
if elm.name == "cellTxt": cellTxt = elm
if elm.name == "headerTxt": headerTxt = elm
#Clean-up before next page
for elm in arcpy.mapping.ListLayoutElements(mxd, "GRAPHIC_ELEMENT", "*clone*"):
elm.delete()
for elm in arcpy.mapping.ListLayoutElements(mxd, "TEXT_ELEMENT", "*clone*"):
elm.delete()
noGrowth.elementPositionX = -3
cellTxt.elementPositionX = -3
headerTxt.elementPositionX = -3
horzLine.elementPositionX = -3
vertLine.elementPositionX = -3
#Reference DDP object and set appropriate page
ddp = mxd.dataDrivenPages
ddp.currentPageID = ddp.getPageIDFromName(division)
#Graphic table variable values
tableHeight = 3.0
tableWidth = 4.5
headerHeight = 0.2
rowHeight = 0.15
upperX = 11
upperY = 3.2
#Build selection set
divisionName = ddp.pageRow.Division
arcpy.AddMessage("Processing: " + division)
with arcpy.da.SearchCursor("IndexLayer", ("Division")) as cursor:
for row in cursor:
exp = 'Division = divisionName'.format(row[0])
arcpy.SelectLayerByAttribute_management("IndexLayer", "NEW_SELECTION", exp)
# selection
arcpy.SelectLayerByLocation_management("transferStation", "INTERSECT", "NEW_SELECTION", "IndexLayer4")
arcpy.Select_analysis(transferStation, "in_memory\IndexLayer4", '')
numRecords = int(arcpy.GetCount_management("in_memory\IndexLayer4").getOutput(0))
#Sort selection
#Show selected features
#Add note if there are no counties > 100%
if numRecords == 0:
noGrowth.elementPositionX = 3
noGrowth.elementPositionY = 2
else:
#if number of rows exceeds page space, resize row height
if ((tableHeight - headerHeight) / numRecords) < rowHeight:
headerHeight = headerHeight * ((tableHeight - headerHeight) / numRecords) / rowHeight
rowHeight = (tableHeight - headerHeight) / numRecords
#Set and clone vertical line work
vertLine.elementHeight = (headerHeight) + (rowHeight * numRecords)
vertLine.elementPositionX = upperX
vertLine.elementPositionY = upperY
temp_vert = vertLine.clone("_clone")
temp_vert.elementPositionX = upperX + 1.5
temp_vert = vertLine.clone("_clone")
temp_vert.elementPositionX = upperX + 2.5
temp_vert = vertLine.clone("_clone")
temp_vert.elementPositionX = upperX + 3.5
temp_vert = vertLine.clone("_clone")
temp_vert.elementPositionX = upperX + 4.5
#Set and clone horizontal line work
horzLine.elementWidth = tableWidth
horzLine.elementPositionX = upperX
horzLine.elementPositionY = upperY
horzLine.clone("_clone")
horzLine.elementPositionY = upperY - headerHeight
print numRecords
y=upperY - headerHeight
for horz in range(1, numRecords+1):
y = y - rowHeight
temp_horz = horzLine.clone("_clone")
temp_horz.elementPositionY = y
#Set header text elements
headerTxt.fontSize = headerHeight / 0.0155
headerTxt.text = "Name"
headerTxt.elementPositionX = upperX + 0.75
headerTxt.elementPositionY = upperY - (headerHeight / 2)
newFieldTxt = headerTxt.clone("_clone")
newFieldTxt.text = "Type"
newFieldTxt.elementPositionX = upperX + 2
newFieldTxt = headerTxt.clone("_clone")
newFieldTxt.text = "Longitude"
newFieldTxt.elementPositionX = upperX + 2.75
newFieldTxt = headerTxt.clone("_clone")
newFieldTxt.text = "Latitude"
newFieldTxt.elementPositionX = upperX + 3.25
#Set and clone cell text elements
cellTxt.fontSize = rowHeight / 0.0155
y = upperY - headerHeight
rows = arcpy.SearchCursor("in_memory\IndexLayer4")
for row in rows:
x = upperX + 0.05
col1CellTxt = cellTxt.clone("_clone")
col1CellTxt.text = row.getValue("Name")
col1CellTxt.elementPositionX = x
col1CellTxt.elementPositionY = y
col2CellTxt = cellTxt.clone("_clone")
col2CellTxt.text = row.getValue("Type")
col2CellTxt.elementPositionX = x + 1.75
col2CellTxt.elementPositionY = y
col3CellTxt = cellTxt.clone("_clone")
col3CellTxt.text = str(round(row.getValue("Longitude"), 2))
col3CellTxt.elementPositionX = x + 3
col3CellTxt.elementPositionY = y
col4CellTxt = cellTxt.clone("_clone")
col4CellTxt.text = str(round(row.getValue("Longitude"), 2))
col4CellTxt.elementPositionX = x +4.75
col4CellTxt.elementPositionY = y
y = y - rowHeight
arcpy.Delete_management("in_memory\IndexLayer4")
arcpy.Delete_management("in_memory\IndexLayer4")
arcpy.mapping.ExportToPDF(mxd, relpath + "\\" + division + ".pdf")
os.startfile(relpath + "\\" + division + ".pdf")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Farhan... reposting the code won't help, you need to edit your post, cut the code from the post... then hit the 3 dots
... on the toolbar above... select Python, then past your code from the original script is best or from the lines you cut and pasted.
see this for another example .... another code formatting link ...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Sir, I have updated the post, your kindness is required.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Line 48... this line .... does nothing... is divisionName supposed to be replaced by the value in row[0]?, then you are needing a {} at least
exp = 'Division = divisionName'.format(row[0])