- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Utility Network
- :
- ArcGIS Utility Network Questions
- :
- Best Practices for Attribute Data Modeling in UN
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Best Practices for Attribute Data Modeling in UN
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This is more of a discussion than a question...
With UN model, we have only 3 feature classes per domain; Junction, Device and Line to model the assets. Most of the "assets" will be either a Device or a Line. I understand that this is by-design for performance reasons. In traditional data modeling, we used separate feature classes for asset types e.g. Fuse, Switch, Circuit Break, Transformer, Service Connection, HV Conductor, LV Conductor, Busbar etc. for Electric Distribution model.
Working with only two meaningful feature classes for some disparate asset types creates an under-normalised data model. It either creates a huge table with only a fraction of fields populated for any row or overloads fields for each subtype e.g. "Rating" attribute will be used as "KVA Rating" for a Transformer, "Load Break amps" for Fuse, "Maximum current" for a Regulator and so on. Some of the clients I work with tend to store electrical characteristics for devices and lines in GIS e.g. impedance and reactance for transformer etc. With separate field for each classification and sub-classification will easily create a table with more than 250 fields, not a best option from DBA point of view or we have to use generic fields such as "AttributeA", "AttributeB" etc. and then give alias (configure pop-up) in each layer which is time consuming exercise in the least not mentioning the heartache it gives to a data modeler.
It seems that Asset Package 3.x has tried to address the issue by creating related tables for devices and line wires. But it is still only two related tables. Will it be better to create a related table for each subtype e.g. Fuse Unit, Transformer Unit, Switch Unit, HV Conductor Wire etc. This way Device and Line feature class only stores network attributes and symbology attributes and individual tables stores electrical and EAM attributes for that type. It seems doable but have following questions;
Can related tables participate in defining tracing? E.g. stop a trace if transformer KVA rating exceeds certain value or sum impedance of all lines traced.
Does UN editing support adding attributes to related tables?
Can data in related table be updated in client-server mode instead of Web Service mode?
Can "Export Subnetwork" export attributes from a related table?
All comments and suggestions welcome...
Thanks,
Vish
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Vish
The ElectricDeviceUnit table is meant primary for migration support. However, we have structured such that one could store unit data here. However, it would not support managing any network attributes, like subnetwork, pressure or phase. Also, I would strongly recommend not creating a related table for each subtype. Doing so could adversely impact performance, especially editing and reconcile performance.
Related tables cannot participate in tracing at this time. There are future plans for Non-spatial objects, but no firm release date for that capability. The non-spatial objects would allow for participation in tracing.
Branch versioned tables will have the same editing restrictions as any other class in Branch Versioning, which means it will only support access and editing via feature services.
As for fields, we have implemented field reuse, which means for a specific asset group field X has a specific meaning and a different meaning for field Y. All attributes use alias defined at the Asset Group level. One would view the system from the feature service perspective as opposed to a database perspective.
At this time Export Subnetwork will not export related tables. We are looking at releasing an example of how this could be accomplished.
[email protected]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Vish
The ElectricDeviceUnit table is meant primary for migration support. However, we have structured such that one could store unit data here. However, it would not support managing any network attributes, like subnetwork, pressure or phase. Also, I would strongly recommend not creating a related table for each subtype. Doing so could adversely impact performance, especially editing and reconcile performance.
Related tables cannot participate in tracing at this time. There are future plans for Non-spatial objects, but no firm release date for that capability. The non-spatial objects would allow for participation in tracing.
Branch versioned tables will have the same editing restrictions as any other class in Branch Versioning, which means it will only support access and editing via feature services.
As for fields, we have implemented field reuse, which means for a specific asset group field X has a specific meaning and a different meaning for field Y. All attributes use alias defined at the Asset Group level. One would view the system from the feature service perspective as opposed to a database perspective.
At this time Export Subnetwork will not export related tables. We are looking at releasing an example of how this could be accomplished.
[email protected]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Just to clarify...
John Alsup wrote:
Related tables cannot participate in tracing at this time. There are future plans for Non-spatial objects, but no firm release date for that capability. The non-spatial objects would allow for participation in tracing.
Non-spatial edges and junctions are intended to better model telecom facilities. There's no plan to provide access to related tables in tracing.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
John,
Can you please clarify the 'alias' part for me regarding the reuse of a field.
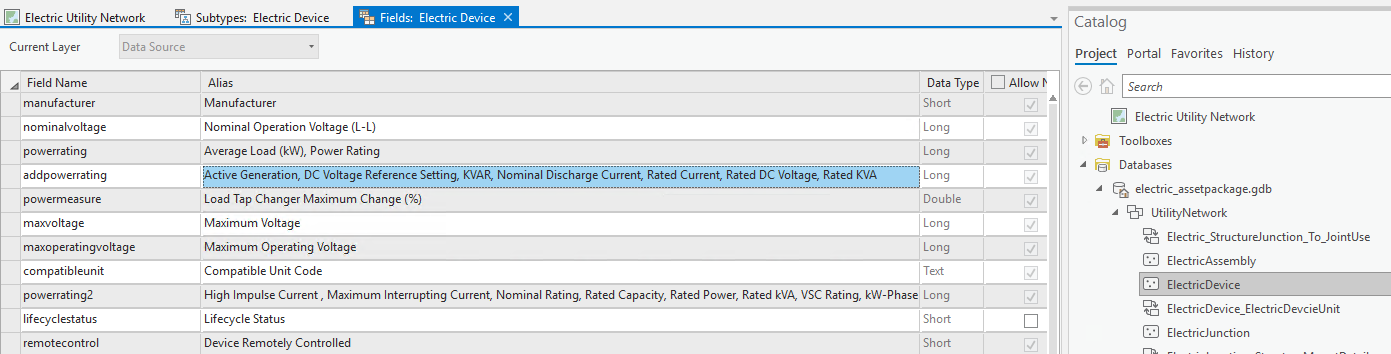
I've seen values in the field's alias column which are comma delimited. Does this represent the various alias for the different asset group based on their sequence in the Subtypes editor?
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So, let's take the field addpowerrating in the ElectricDevice feature class, as you have shown. In the field alias, we comma delimited the alias description with a list of Asset Groups (subtypes). Now, in the editing map we have provided with the asset package, we use subtype layers. For each sublayer in the subtype layer, we define the visible attributes and the alias for each attribute. In this example, the "addpowerrating" attribute would be called "Active Generation" for asset group sublayer "High Voltage Generation", KVAR for asset group sublayers "High Voltage Power Factor Correcting", "Medium Voltage Power Factor Correcting" and "Low Voltage Power Factor Correcting".
Why did we do this? First, we needed to limit the number of fields being returned from the service (not the database, you shouldn't even think in database terms anymore). Next, a field like KVAR would only apply to capacitors, transformers don't have a KVAR rating, but they do have a KVA rating, so why not use the same field, but use it differently based on asset group (subtype). This significantly reduces the number of attributes for the class, improving transmission times to the client.
[email protected]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
One additional thing to think about... If you want to make use of a particular field in a tracing operation, you need to create a Network Attribute, and only one Network Attribute can be assigned to a single field.
If one of these fields has different uses for different asset groups, you're going to have a hard time coming up with a Network Attribute name that makes sense. Let's continue with John's example above. If you wanted to run a trace that used KVAR for capacitors (I don't know if this is an actual use case, just go with me here) and also wanted to run a different tracing operation that looks at KVA for transformers, what would you name this Network Attribute? If you name it KVAR, you're going to confuse the Transformer trace people. If you name it KVA, you're going to confuse the capacitor people.
My recommendation is that if you want to create a Network Attribute on a field, you shouldn't reuse that field for other purposes in different Asset Groups.
This only really applies if your users are using the Trace geoprocessing tool user interface. If you've built geoprocessing models or SDK tools for tracing (and you really should), then users won't see the names of the Network Attributes and you don't need to worry about this.
--Rich
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
John,
Thanks for the clarification around the use in the Editor map. This is just using the standard method of renaming/alias a field.
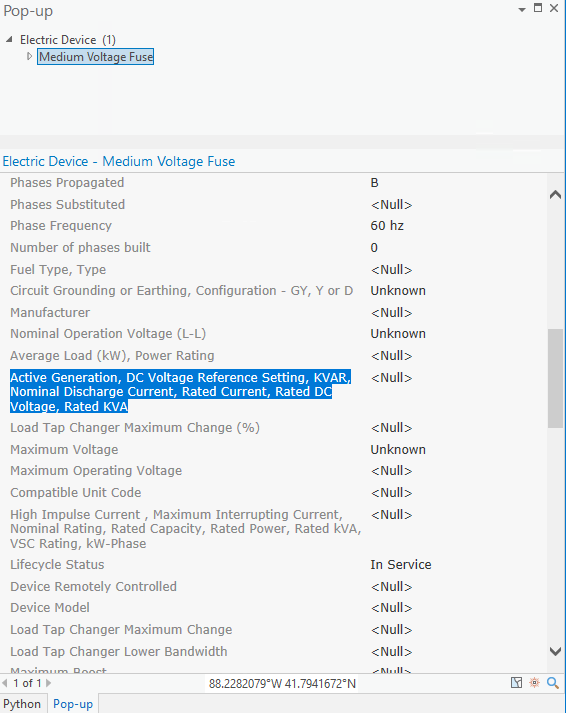
I was interpreting the comma delimited string in the alias field as a form of configuration that when the pop-up opens, it was parsing this to work out which value to use as the alias for the given subtype based on sequence.
If this isn't done, we will see a massive label for the field as defined above.
Thanks again
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
@JohnAlsup For fields that are re-used, and which therefore have multiple aliases, is the order in which the aliases are listed inconsequential?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The order was done to facilitate our tools for creating maps. Outside of that process, it has no impact.
[email protected]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The order of the alias was done to allow us to better automate the map creation process. Outside of our process, it makes no difference.
[email protected]