Lidar provides a fascinating glimpse into the landscape of the Jack and Laura Dangermond Preserve. Using a ground elevation service and a point cloud created from lidar, and natural color imagery, we created an interactive routing application that allows users to virtually drive through the Preserve.
This article will tell you how we created this application and a few things we learned along the way.
The Jack and Laura Dangermond Preserve
In 2018, the Jack and Laura Dangermond Preserve was established after a philanthropic gift by Jack and Laura enabled The Nature Conservancy to purchase the over 24,000 acre tract of land around Point Conception, California. The Preserve protects over eight miles of near-pristine coastline and rare connected coastal habitat in Santa Barbara County, and includes the Cojo and Jalama private working cattle ranches. The land is noted to be in tremendous ecological condition and features a confluence of ecological, historical, and cultural values across Native American, Spanish and American histories that have co-evolved for millennia. The area is also home to at least 39 species of threatened or special status. The Preserve will serve as a natural laboratory, not only for studying its biodiversity and unique habitats, but also as a place where GIS can be used to study, manage, and protect its unique qualities.
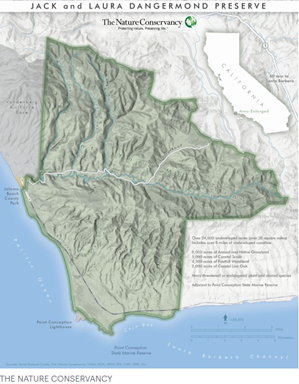
Map is courtesy of The Nature Conservancy and Esri
Lidar and Imagery
Soon after the Preserve was established, Aeroptic, LLC, an aerial imagery company, captured aerial lidar and natural color orthomosaic imagery over the Preserve.
Lidar (light detection and ranging) is an optical remote-sensing technique that uses lasers to send out pulses of light and then measures how long it takes each pulse to return. Lidar is most often captured using airborne laser devices, and it produces mass point cloud datasets that can be managed, visualized, analyzed, and shared using ArcGIS. Lidar point clouds are used in many GIS applications, such as forestry management, flood modelling, coastline management, change detection, and creating realistic 3D models.
When imagery is captured at the same time as lidar, as Aeroptic did, complementary information is obtained. The spectral image information can be added to the 3D lidar information, allowing for more accurate analysis results. More about the imagery later; we received the lidar first, while Aeroptic was still processing the imagery.
Original lidar
Esri obtained the lidar and we began to work with it. The original lidar was flown in three passes: one North-South, one East-West, and another Northwest-Southeast. The average point density was 11.1 points per square meter. Estimated vertical accuracy was about +/- 6 cm. Average flight height was 5253 feet (1640 meters) GPS height. Data was in UTM Zone 11 coordinate system. The original files were checked for quality, then tiled and classified for Ground by Aeroptic. We received 121 LAS files with a total of over 7 billion las points – 7,020,645,657.
We did more quality control to search for inconsistent points (called outliers). One way we checked for outliers was to create a DSM from a LAS dataset, and look for suspect locations in 2D, then use the 3D Profile View in ArcMap to find the problem points. Another method we used was to create a surface elevation from the ground-classified points, then did spot checking in ArcGIS Pro, especially around bridges. We unassigned many ground-classified points that caused the road surface to look too sloped (see the screenshots in the Surface Elevation section.) Then we created a new surface elevation service and a point cloud scene layer service.
Surface Elevation from the lidar
Creating the surface elevation was a big task. The ArcGIS Pro Help system describes the process to do this, and we followed that process. Here are the tools in the order in which we used them. Note that parameters listed for the tools do not include all tool parameters, just the most specifically important ones.
ArcGIS Pro tools
Create Mosaic Dataset
Add Rasters to Mosaic Dataset – very important to specifically set the following parameters:
- Raster Type – LAS Dataset
- Raster Type Properties, LAS Dataset tab:
- Pixel size – 2
- Data Type – Elevation
- Predefined Filters – DEM
- Output Properties, Binning, Void filling – Plane Fitting/IDW. (Lesson learned: without this void fill method, there were holes in the elevation.)
Manage Tile Cache
- Input Data Source – the mosaic dataset
- Input Tiling Scheme – set to Elevation tiling scheme (Lesson learned: do not forget this!)
- Minimum and Maximum Cache Scale and Scales checked on – the defaults that the tool provided were fine for our purpose. Attempts to change them always resulted in tool errors. (Lesson learned: use the defaults!)
Export Tile Cache
- Input Tile Cache – the cache just created with Manage Tile Cache
- Export Cache As – set to Tile package (very important!)
Share Package – to upload the tile package to ArcGIS Online
ArcGIS Online tools
Publish – the uploaded package to create the elevation service.
The surface elevation created from the lidar created a more realistic scene than the ArcGIS Pro default surface elevation, particularly noteworthy over places like this small bridge, shown here with the Imagery basemap:


Elevation source: WorldElevation3D/Terrain 3D Elevation source: lidar-derived surface
Point Cloud Scene Layer Package from the lidar
The first point cloud service that we made included all the lidar points. But when viewed in the tour app, we noticed that the ground points visually conflicted with the elevation surface, which becomes coarser at far-away distances. To remove this visual disturbance, we filtered the LAS dataset to exclude the ground classified points and any points that were within 1.5 meters of the ground surface. (Lesson learned: not all lidar points need to be kept in the point cloud scene service.) The 1.5-meter height was enough to remove ground points but keep small shrubs, fences and other features. The number of points that remained for the point cloud scene layer package was a little over 3 billion, less than half of the original 7 billion points. We used the Create Point Cloud Scene Layer Package tool and set it to Scene Layer Version 2.x. The package was uploaded with Share Package, and then published in ArcGIS Online.
Orthomosaic imagery
The tour application was already working by the time we received the new imagery, but we were very excited when we saw it! We made an image service to use as the “basemap” in the tour app, and we used it to colorize the lidar point cloud.
The Aeroptic imagery was 10 cm natural color orthomosaic, collected at the same time as the lidar, given to us in 50 TIFF files. The first step towards building an image service from this data was to add the files to a mosaic dataset to aggregate them into a single image. The imagery appeared a little too dark, so we applied a stretch function to the mosaic dataset to increase its brightness. To ensure that applications could access the pixels at high performance, we generated a tile cache from the mosaic dataset using the Manage Tile Cache tool. To preserve the full detail of the original 10 cm imagery, we built the cache to a Level of Detail (LOD) of 23, which has a pixel size of 3.7 cm. Finally, we generated a tile package from the cache using the Export Tile Cache tool, uploaded the package to ArcGIS Online, and then published the uploaded package as an imagery layer.
We used the Colorize LAS geoprocessing tool to apply the red, green and blue (RGB) colors from the imagery to the lidar files. The RGB colors are saved in the LAS files, and can be used to display the points, along with other methods like by Elevation, Class and Intensity. Displaying the LAS points with RGB creates a very realistic scene, except for a few places such as where a tree branch hangs over the road yellow centerline and then becomes the bright yellow color.


Lidar before colorizing Lidar after colorizing
The imagery also helped with manual classification of the lidar points around bridges. We edited many points and recreated the surface elevation so that it matched better with the imagery. Here is the same bridge as in the screenshots above in the Surface Elevation section:


New RGB imagery and original lidar as surface elevation New RGB imagery and further-processed lidar as elevation
Road Network
The Nature Conservancy provided a dataset of the vast road network in the Preserve, which includes over 245 miles of roads, with over 10 miles of paved road and over 230 miles of dirt roads and paths.
When we displayed the roads data over the newly acquired imagery, some of the road lines didn’t match up with the imagery, so we edited the road vertices to better match. We then created a custom route task service that included elevation values from the new elevation service, which enabled the elevation values to then be part of the resulting routes when a route is created.
Preserve boundary
The boundary line that outlines the Preserve is on ArcGIS Online as a feature service. We did not create the boundary from the lidar, but did add the service to the web scene as described below.
The Virtual Tour Application
A 3D web scene containing the roads, point cloud, imagery, and the Preserve line was created in ArcGIS Online, and the new elevation service was added as the ground elevation layer. The web scene was incorporated into the Jack and Laura Dangermond Preserve Tour Application, which was built using the latest version of the ArcGIS API for JavaScript.
The application is a virtual tour over roads and trails in the Preserve. The person who is using the app can choose two or more locations to create a route. A Play button starts a virtual ride from the first location and drives along the trails to the next points. The main view of the application shows the trails and the locations, and a marker moves along the trails. An inset map shows the view of the ground imagery and the lidar points from the perspective of the virtual vehicle as it moves along the trail.
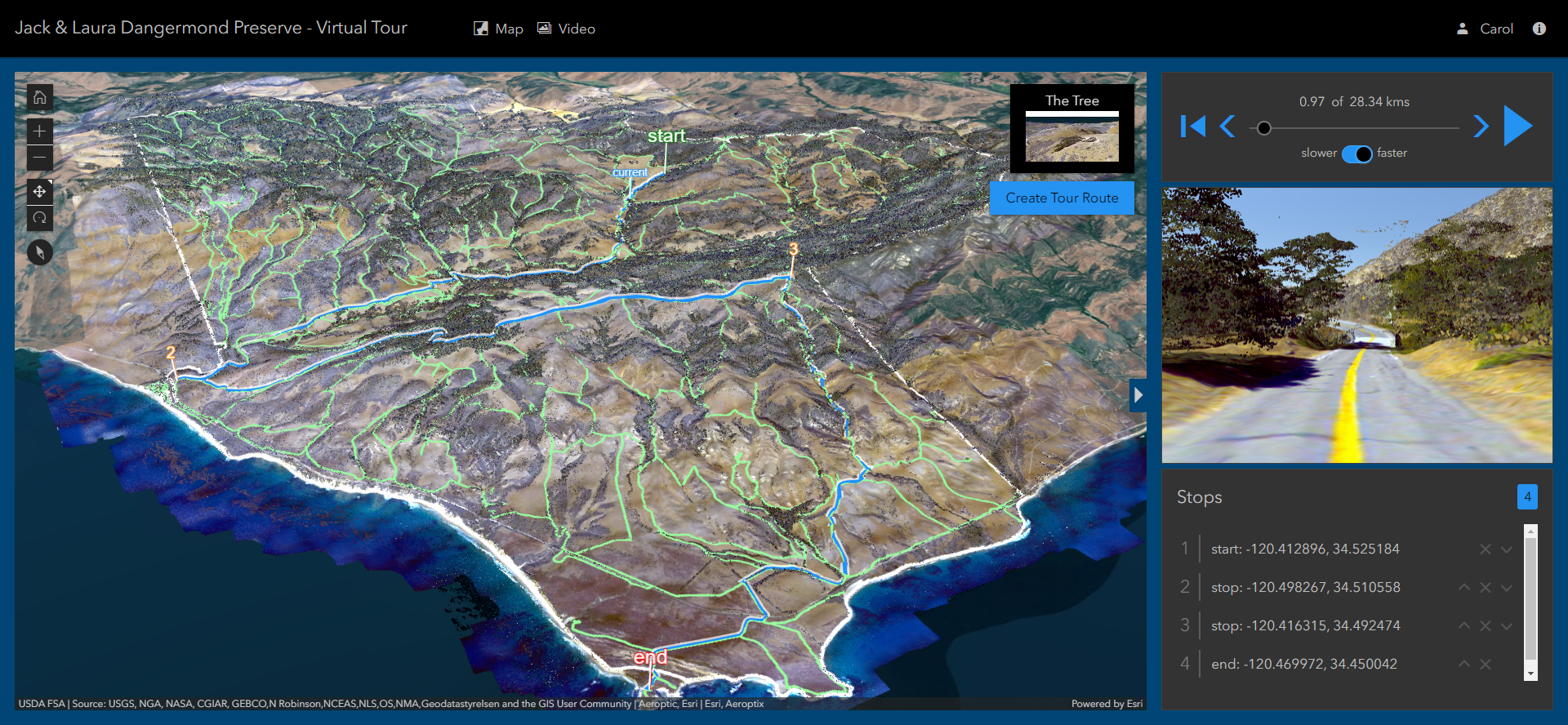
This application was created with secure access for The Nature Conservancy as it provides a new tool for the TNC staff to explore and visualize the Preserve. As such, it is not publicly available.
More information