- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Web AppBuilder
- :
- ArcGIS Web AppBuilder Questions
- :
- Screening widget returning incorrect results
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Screening widget returning incorrect results
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Has anybody else had issues with the screening widget report returning bizarrely high area sums?
I'm currently in the configuration stage of a web app and am doing some testing with various zipped shapefile areas of interest (AOI). One ~300 hectare AOI polygon is returning an overlap of 17 million hectares for one of my feature layer categories (4 classes, the other 3 classes return expected results). It's not isolated to a single feature layer either - other feature layers from different source data are also returning oddball results (58K ha overlap on a 120ha polygon, 6K ha overlap on a 250 ha polygon, all different input feature layers). These weird results also happen when I draw an AOI instead of uploading a shapefile. In most cases (but not all), the high area sum is much higher than the total area of all features in the feature layer (i.e. one feature layer totals ~3.5 million ha, but I'm getting 17 million ha returned for a single class within the data). I have been over the source data with a fine-tooth comb and it's as clean as it can be, so I suspect that I'm either configuring something incorrectly or there is either something up with the screening widget itself.
I've tried the following with no luck:
- Reprojected the source data to web Mercator prior to publishing the feature layer
- Reprojected the AOI shapefiles to web mercator prior to using in the screening widget
- Run topology on all my source data to ensure no overlaps
- Re-indexed the spatial index of the source data & republished the feature layer
- Dissolved the data on the class field to have less features in the feature layer
- Deleted published feature layer and published a fresh feature layer
- Split out data with a definition query on the source and published a single-class feature layer – feature layer still gives incorrect area sum
- Exported the features for a single class into a new feature class and published this as a feature layer
- Simplified the data (collapsed vertices within 10m)
- Removed all other feature layers from the screening widget
- Diced the data with a max 1000 vertices
- Diced the data with a max 500 vertices
- Uploaded the fgdb to AGO and made feature layer
- Uploaded a subset of the data to AGO and made a feature layer
The screening widget looks like it has fantastic potential, but if I can't rely on the results I'll have to look at other ways to get a similar output. If anyone has any thoughts on other things I could try to make the screening widget results more reliable for my data, I'm all ears. I've attached a sample PDF output showing the anomalies.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am also having this issue. I am in Arc Portal Environment making a web app. I have a screening widget set up to draw a polygon and analyze the land ownership/ report the amount of acres. Some areas of the map it works, others you draw a 450 acre rectangle and it returns 23 million acres for private lands, 160 for State, and 115 for BLM. It only seems to wildly exaggerate the Private Lands' acres.
Working
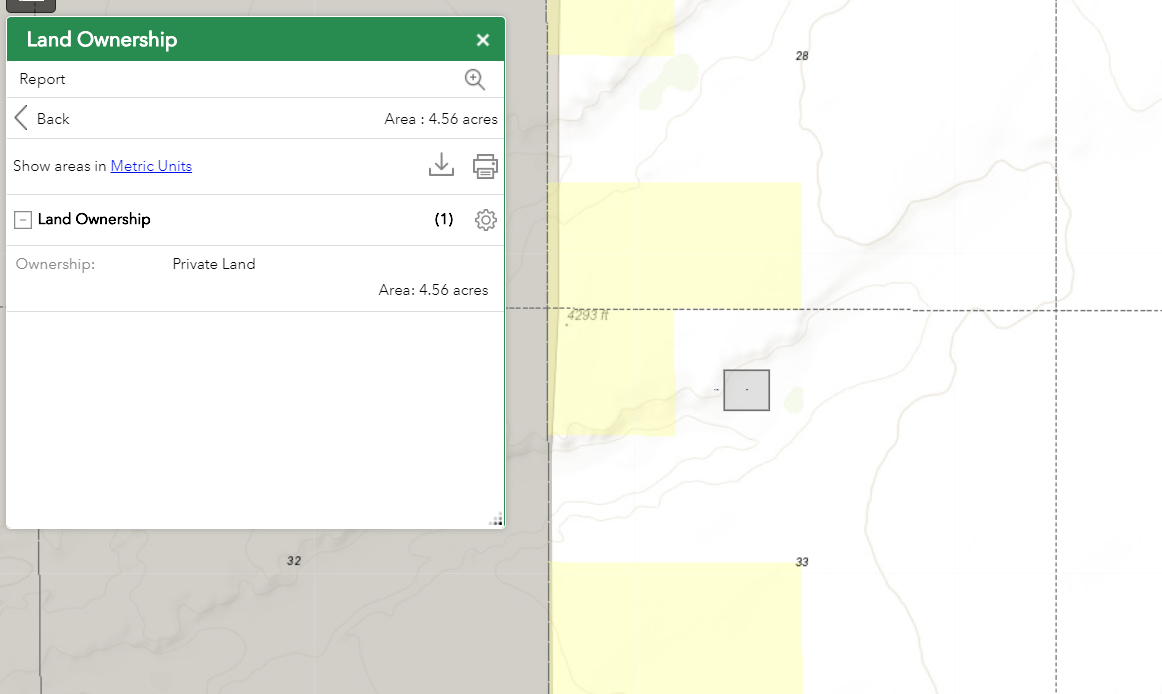
Not Working:
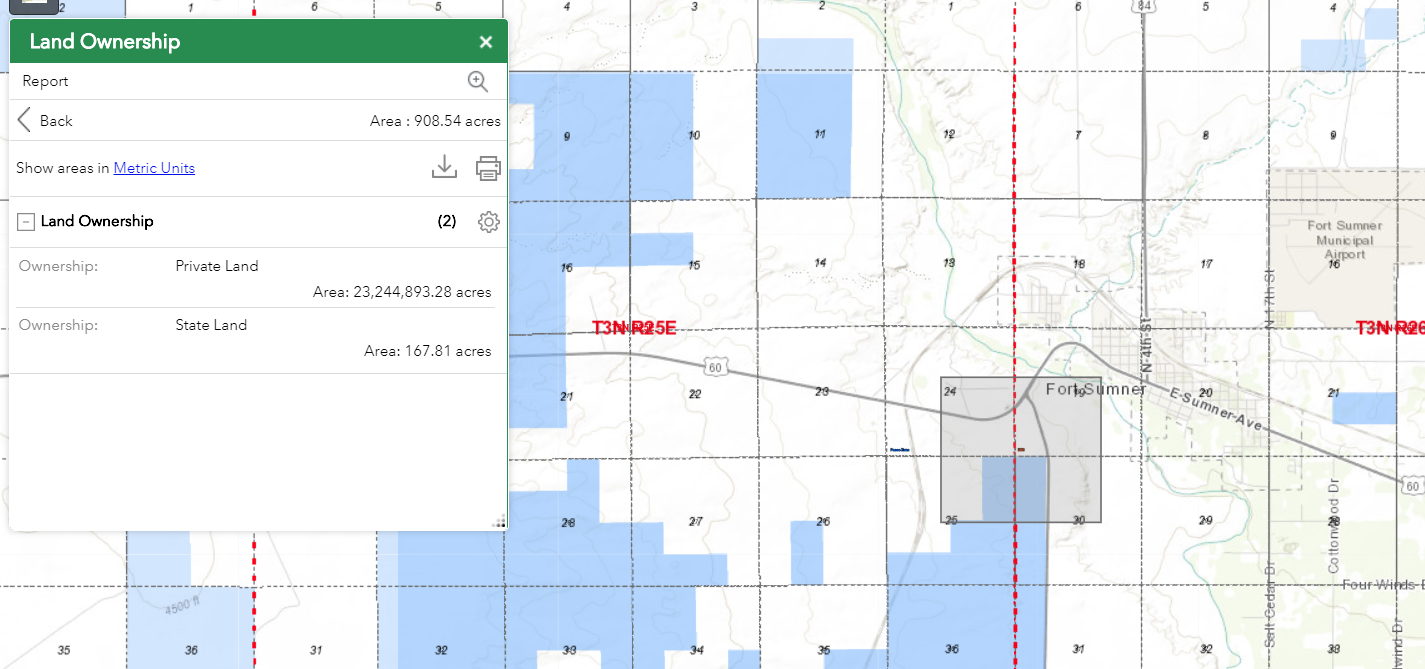
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
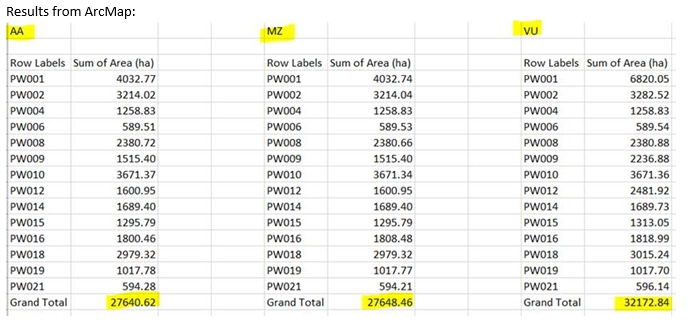
We are also having a similar issue, although we are observing under-reporting of areas as well as over-reporting, and cannot figure out where the errors are coming from. We have also thoroughly reviewed the source data to ensure it is clean and valid.
We are also having an issue where attribute values are getting mixed up in the screening report (see my other post https://community.esri.com/t5/arcgis-online-questions/screening-widget-mixing-up-attribute-values-in...).
Also agree that this widget has huge potential and we would love to be able to rely on its output, however with discrepancies like this, it's basically unusable.
Attached are screenshots of analysis results from ArcMap and from the Screening Widget, highlighting the differences.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Looks like this was probably fixed for Portal 10.6.1