- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- How to create a new field with a combination based...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to create a new field with a combination based on another field with arcpy?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I like to create a new txt which has two columns: Id and GRIDCODE.
This is the original Table:
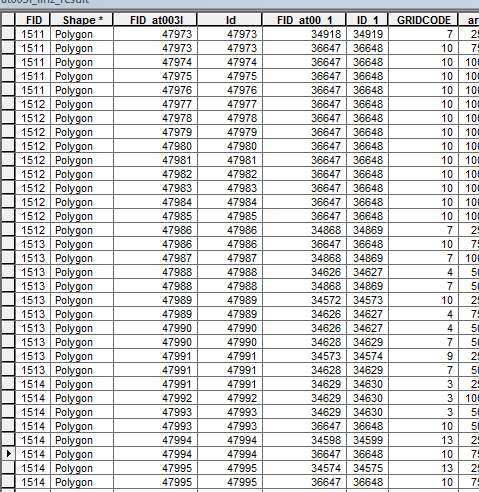
The Id column of the new txt should have just unique values. I’m able to do this with the following code. But the GRIDCODE -column of the new txt should have the possible combinations of one equal Id, for example:
The new Id field 47973 should have the new GRIDCODE field 7, 10
or the new Id field 47990 should have the new GRIDCODE field 4, 7.
To clarify the question I build an example-table with excel, this should be the result I like to write in the new txt. Do I have to work with an update cursor and if, else? What about the comma, how is it possible to use them without getting a new column but the combination in a column?
I would be very thankful to get a tip how I can go on with my code.

import arcpy
import os
from arcpy import env
env.overwriteOutput = True
env.workspace = r"D:\Users\ju\ers\cities_UA\resultfolder"
DataDict = {}
inputshp = r"D:\Users\ju\ers\cities_UA\resultfolder\innsbruckauswahl.shp"
outputfile = r"D:\Users\ju\ers\cities_UA\resultfolder\inns_test.txt"
f = open (outputfile, 'w')
f.write ("ID,Gridcode,\n")
f.close ()
#f = open (outputfile, 'a')
ID=[row[0] for row in arcpy.da.SearchCursor(inputshp, ["Id", "GRIDCODE"])]
#GRIDCODE = [row[0] for row in arcpy.da.SearchCursor(inputshp, ["GRIDCODE"])]
uniqueID = set(ID)
for ID in uniqueID:
print ID
# f.write((str(ID)) + "," + (str(GRIDCODE))+ "\n")
#f.close()
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The code to get the unique list of ID values and a concatenated list of GRIDCODE values is done with the search cursor outputting to a dictionary. The dictionary key makes sure that you will get a unique list of ID values, If you need the values sorted, then the dictionary does not do that unless you put it through a secondary process.
# get a dictionary of unique ID value keys and each key's unique gridcodes valueDict = {} with arcpy.da.SearchCursor(inputshp, ["Id", "GRIDCODE"]) as searchRows: for searchRow in searchRows: keyValue = searchRow[0] gridcode = searchRow[1] if not keyValue in valueDict: valueDict[keyValue] = [gridcode] elif not gridcode in valueDict[keyValue]: valueDict[keyValue].append(gridcode) # sort both the ID value keys and the gridcodes which are converted to a string list for keyValue in sorted(valueDict.keys()): items = "" for item in sorted(valueDict[keyValue]): if items == "": items = str(item) else: items = items + ", " + str(item) # write to text file with the gridcode list enclosed in double quotes f.write(str(keyValue) + ',"' + items + '"\n' )
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The code to get the unique list of ID values and a concatenated list of GRIDCODE values is done with the search cursor outputting to a dictionary. The dictionary key makes sure that you will get a unique list of ID values, If you need the values sorted, then the dictionary does not do that unless you put it through a secondary process.
# get a dictionary of unique ID value keys and each key's unique gridcodes valueDict = {} with arcpy.da.SearchCursor(inputshp, ["Id", "GRIDCODE"]) as searchRows: for searchRow in searchRows: keyValue = searchRow[0] gridcode = searchRow[1] if not keyValue in valueDict: valueDict[keyValue] = [gridcode] elif not gridcode in valueDict[keyValue]: valueDict[keyValue].append(gridcode) # sort both the ID value keys and the gridcodes which are converted to a string list for keyValue in sorted(valueDict.keys()): items = "" for item in sorted(valueDict[keyValue]): if items == "": items = str(item) else: items = items + ", " + str(item) # write to text file with the gridcode list enclosed in double quotes f.write(str(keyValue) + ',"' + items + '"\n' )
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you for this code!!!
I will try it with other datasets tomorrow. THANKS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The code is untested, so if it throws an error it is probably because I missed some minor syntax requirement. The overall logic structure should be correct. I drew upon this stackoverflow post and this Geonet post to come up with this code. It assumed that both the IDs and the listed gridcodes for each ID should be unique and sorted. If you wanted only the IDs unique and sorted and the listed items to allow repeated values or to be in their original order, the code would have to be modified slightly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The code is working without any syntax errors (first there was a little thing at line 17, where you already add a double ==). The gridcode should not be unique and sorted, just the combination of an equal ID.
Thanks a lot!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
To eliminate the steps that make the gridcode list unique and sorted the following code, which changes line 9 to eliminate the unique gridcode process and line 15 to eliminate the sorted gridcode process, would work. The string list of gridcodes could technically be built in lines 8-10 allowing lines 14-19 to be eliminated with a minor tweak to line 21 if you don't need them sorted, but this structure makes it easy to add back the processes that make the list either unique or sorted. The previous code would make the gridcode list for ID 47991 be "3, 7, 9", while this code will make ID 47991 have the list "9, 7, 3".
# get a dictionary of unique ID value keys and each key's gridcodes
valueDict = {}
with arcpy.da.SearchCursor(inputshp, ["Id", "GRIDCODE"]) as searchRows:
for searchRow in searchRows:
keyValue = searchRow[0]
gridcode = searchRow[1]
if not keyValue in valueDict:
valueDict[keyValue] = [gridcode]
else:
valueDict[keyValue].append(gridcode)
# sort the ID value keys and convert the gridcodes to a string list
for keyValue in sorted(valueDict.keys()):
items = ""
for item in valueDict[keyValue]:
if items == "":
items = str(item)
else:
items = items + ", " + str(item)
# write to text file with the gridcode list enclosed in double quotes
f.write(str(keyValue) + ',"' + items + '"\n' )
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
That is so perfect, exactly what I need. Thank you so, so much!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Richard,
I like to ask you kindly how I can write more than one combination to the new txt. To make a better analysis I created new classifications and now I like to add there combinations to the txt. Therefore I copied your code two times and filled the new fieldname to the searchcursor and gave new names, the keyValue is always the same. But I have problems with the lines:
for keyValue in sortedDict:
f.write(str(keyValue) + ',"' + sortedDict[keyValue] + '"\n' )
f.close()
I tried this, but it isn’t working.
for keyValue in [sortedDict, valueDictA, valueDictB]:
f.write(str(keyValue) + ',"' + sortedDict[keyValue] + ',"' + sortedDictA[keyValue]+ ',"' + sortedDictB[keyValue]+'"\n' )
f.close()

At the momant I'm doing it 3 times, so not a nice solution... And than joins
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Jutta:
The code you wrote makes no sense to me. I would have to restructure the code from the beginning and not at the stage you have rewritten it to deal with 3 fields. If this is all coming from one record the code probably can be written using one dictionary.
I need to see an example of the data and the result you really want. Is this data all in one table? Are they from separate tables? Are there Nulls that have to be excluded?
The error is also dependent on the code your wrote that populates the dictionaries. I also don't think you can write a for loop the way you have written it. You cannot extract keys from 3 dictionaries at once. You have to get the keys from just one dictionary at a time and verify they are in the other dictionaries. Also, the dictionaries in the for statement do not match the dictionaries in the string concatenation statement.
So give me a real example of what the input data would look like and what you want the output to look like for value 47991.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Sorry, for disturbing you, I will just do it three times. And in the end I will write it to one table. I’m not working for a long time with arcpy, but this is fine so. Thanks again for your code.