- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Why is arcpy.append_management so slow?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Why is arcpy.append_management so slow?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So I was working on a little project merging a large number of datasets into one. Irritatingly, each partial dataset was residing in a feature class of the same name, scattered across several hundred file geodatabases, also of the same name but with an added publication date in the filename, and each stuffed into a ZIP archive.
My process:
- Iterate over a list of archives
- Unzip each GDB's, while logging the occasional bad ZIP file
- With all GDB in the same directory, iterate over GDB's
- Access the feature class
- Copy all features into a in-memory "temp" feature class
- Add a date field and populate it with the the publication date of GDB.
So much for background. --- But which arcpy method to use for writing all these partial datasets to an SDE feature class? All that was needed was to append all features from source to the target feature class with matching list of fields (identical schema). So I tried:
arcpy.append_management(['in_memory\\temp'], target_fc, "TEST")
This seemed to work fine for a smaller test dataset. With approx. 1200 features per feature class, the process took about 6 sec fer feature class. That's slower than 1200 inserts in SQL but I could live with that. So I added a logger from the Python standard library logging module to get some info on processing time info and pointed my script at the directory with 800+ GDB's, an 80 GB directory with all the database overhead.
And it ran... and ran... and ran...
The 1st run:
Start 01/22/2019 04:14:14 PM
Finish 01/22/2019 11:41:36 PM
Total: 7h:27m:22s
I was not prepared for that kinda of lengthy ordeal and started researching. I stumbled across this thread here (Loop processing gradually slow down with arcpy script) and the mention arcpy.SetLogHistory caught my attention. I had no idea that arcpy logs to an ESRI history file even when you're running a code outside of any application.
So I set the flag to False, and ran my script again.
arcpy.SetLogHistory(False)The 2nd run: 01/23/2019 05:03:23 PM 01/24/2019 12:49:21 AM Total: 7h:45m:58s
Even worse!
Here is my code:
arcpy.CopyFeatures_management(fc_source,'in_memory\\temp')
arcpy.AddField_management('in_memory\\temp',"date_reported",'DATE')
#this is the date portion of the GDB name
datestring = gdb[-12:-4]
updatedate = datetime.strptime(datestring, '%Y%m%d').strftime('%m/%d/%Y')
fields = "date_reported"
with arcpy.da.UpdateCursor('in_memory\\temp', fields) as cursor:
for row in cursor:
row[0] = updatedate
cursor.updateRow(row)
try:
arcpy.Append_management(['in_memory\\temp'], SDE_target_fc, "TEST")
logger.info("Successfully wrote data for {0} to SDE".format(datestring))
except:
logger.info("Unable to write data to SDE...")
arcpy.Delete_management("in_memory\\temp")This was driving me crazy, so I pulled the timestamps from my log and plotted the diff's for each feature class using matplotlib/pandas for both runs. X is a count of all the iterations over feature classes, Y is the time in seconds each INSERT (or the portion of the code doing the append) took
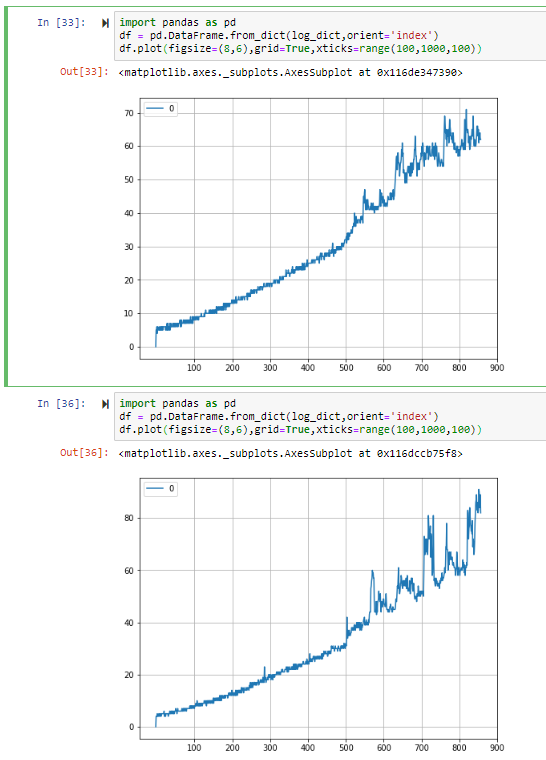
Two questions that come to mind:
1) Why does each INSERT take longer than the one before?
2) What the heck happens when I get to feature class #500 or so where that steady slowing trend goes berserk?
Just for sake of completeness, I also ran the script using the following ("NO_TEST") - with the same result.
arcpy.Append_management(['in_memory\\temp'], SDE_target_fc, "NO_TEST")
Since arcpy.append clearly wasn't performing, I followed the advice from this thread (Using arcpy.da.InsertCursor to insert entire row that is fetched from search cursor?) and replaced arcpy.append with:
dsc = arcpy.Describe(target_fc)
fields = dsc.fields
fieldnames = [field.name for field in fields]
...
with arcpy.da.SearchCursor('in_memory\\temp',fieldnames) as sCur:
with arcpy.da.InsertCursor(target_fc,fieldnames) as iCur:
for row in sCur:
iCur.insertRow(row)Th 3rd run:
01/24/2019 01:40:31 PM
01/24/2019 02:19:09 PM
Total: 38m:38s
Now we're talking. So much faster! In fact, 2318 seconds for 850 INSERTS, comes out to about 3 sec per transaction, and when you plot it:
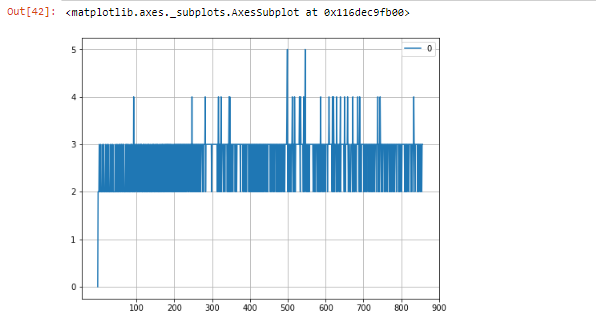
Now, that's the kind of behavior I'd expect. That no matter how many INSERTS you do, they always take about 2-4 seconds. So my question: What in the world is append_management doing? Clearly, it's the wrong tool for what I was doing despite its name, or is it not?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
a good guess would be validating the geometry, since you used no test for attributes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
But I tried both "TEST" and "NO_TEST". Both took about the same time, 7+ hours.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I usually assume that 'field' testing would just refer to attributes and not the geometry, but in any even, it is even more confusing since it appears that the geometry just gets dumped in and not 'fixed' because you have to use Union to fix geometries that may overlap, intersect or whatever...
This tool will not planarize features when they are added to the target dataset. All features from both the input feature class and the target feature class will remain intact after the append, even if the features overlap. To combine, or planarize, feature geometries, use the Union tool.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'll definitely read up on that some more. When I first noticed that flag, I wondered how that really applied to me since my source fc's are all the same schema for sure. No checking needed. But the documentation suggested otherwise. Either way, lesson learned likely is to use the InsertCursor.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks a lot for sharing. Append is extremely slow. It was taking me more than 24 hours to run just one single. Let me test Insert Cursor.