- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- update cursor invalid sql statement
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
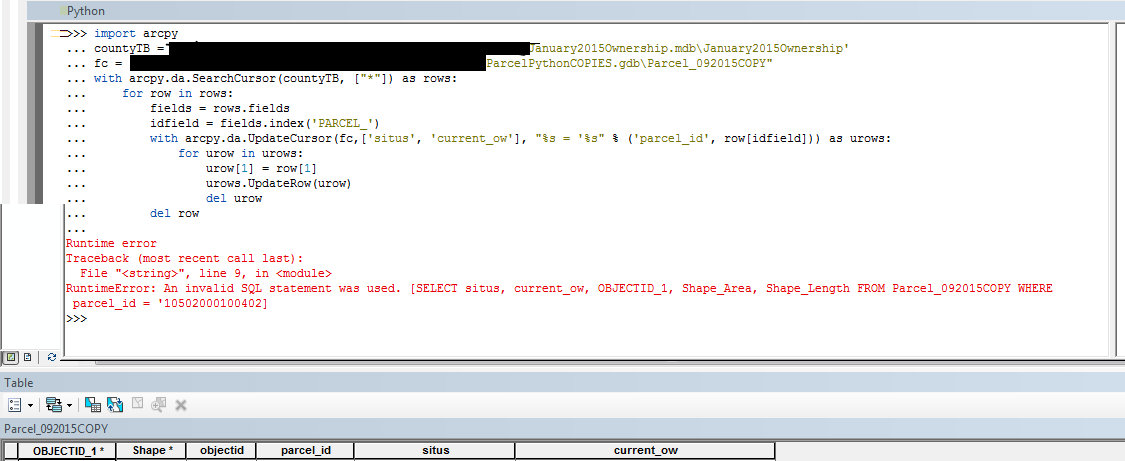
I'm new to python so forgive me if this seems like a dumb question... I work for the city and we get parcel information monthly from the county. Usually the data comes in a text file which I then put in an mdb. I'm trying to write some code to run an update our layers with the updated monthly information. Currently, I've just been trying to get a few fields to update inside a 'test' file geodatabase but I'm stuck. I get the following error message with the following code. Any ideas?
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Please post Python questions with the code in the question as text (formatted in a code block) -- It allows others to try your code without retyping it from scratch. If you need to redact pieces, be sure to explain what they were sufficiently so that suitable scaffolding can be applied.
- V
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I wasn't sure on how to do that, so thanks for the info. Here's the code.
import arcpy
countyTB =...January2015Ownership.mdb\January2015Ownership'
fc = ...ParcelPythonCOPIES.gdb\Parcel_092015COPY"
with arcpy.da.SearchCursor(countyTB, ["*"]) as rows:
for row in rows:
fields = rows.fields
idfield = fields.index('PARCEL_')
with arcpy.da.UpdateCursor(fc,['situs', 'current_ow'], "%s = %s" % ('parcel_id', row[idfield])) as urows:
for urow in urows:
urow[1] = row[1]
urows.UpdateRow(urow)
del urow
del row
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I would probably do something along the lines of:
import arcpy
countyTB = r'...January2015Ownership.mdb\January2015Ownership'
fc = r'...ParcelPythonCOPIES.gdb\Parcel_092015COPY'
# create a dictionary
dct = {r[0]: r[1] for r in arcpy.da.SearchCursor(countyTB, ('PARCEL_', 'TheOtherFieldNameAtIndex1'))}
with arcpy.da.UpdateCursor(fc, ('parcel_id', 'current_ow')) as curs:
for row in curs:
parcel_id = row[0]
if parcel_id in dct:
row[1] = dct[parcel_id]
curs.updateRow(row)You are reading all the fields of countyTB when you only seem to need two. For the copy you are reading the field 'situs' which I don't think you are using. Using a dictionary and looking up the data might make things a bit faster, but if your have a lot of features, it may be slow.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for the idea... Ultimately, there will be 12 different fields that will need to be updated. The intention of this script was to run a test on just a few fields (current_ow & situs) for 'proof of concept'.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This worked great and was very fast. However, I'm a bit confused how I can get this to cycle through multiple fields? Maybe use a getparameter to manually set the field after each cycle?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You could use a dictionary with a list of values, in stead of a dictionary with a single field as value. This would require some changes in building the dictionary and the way the values are retrieved in the update cursor, but it can be done. If the code you tested was fast, it means that you don't have that many features to process. In that case it would not be a problem to create this larger dictionary (with lists as values).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Please remember to mark your question as answered.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I was having difficulty getting the dictionaries working correctly but I stumbled onto a great blog post which was the exact thing I was looking for (link below). Thanks for everyone's help, I've learned a lot from you during this. I look forward to using python for more automation purposes in the future.
Turbo Charging Data Manipulation with Python Cursors and Dictionaries
import arcpy
...
... sourceFC = "...January2015Ownership.mdb\January2015Ownership"
...
... sourceFieldsList = ["PARCEL_","SITUS", "CURRENT_OWNER", "CO_OWNER", "OWNER_MAILADDR", "OWNER_CITY_STATE", "OWNER_ZIPCODE", "TAX_DISTRICT", "TAX_CODE", "SEC", "TOWNSHIP", "RANGE", "LEGAL"]
...
... # Use list comprehension to build a dictionary from a da SearchCursor
... valueDict = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(sourceFC, sourceFieldsList)}
...
... updateFC = "...\ParcelPythonCOPIES.gdb\TaxParcel_COPY"
...
... updateFieldsList = ['PARCELID','SITEADDRESS','OWNERNME1', 'OWNERNME2', 'PSTLADDRESS', 'PSTLCITY', 'ZIPCODE', 'TAX_DIST', 'TAX_CODE', 'SEC', 'TWN', 'RGE', 'PRPRTYDSCRP']
...
... with arcpy.da.UpdateCursor(updateFC, updateFieldsList) as updateRows:
... for updateRow in updateRows:
... # store the Join value of the row being updated in a keyValue variable
... keyValue = updateRow[0]
... # verify that the keyValue is in the Dictionary
... if keyValue in valueDict:
... # transfer the values stored under the keyValue from the dictionary to the updated fields.
... for n in range (1,len(sourceFieldsList)):
... updateRow = valueDict[keyValue][n-1]
... updateRows.updateRow(updateRow)
...
... del valueDict
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »