- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Spatial Join help.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
When i do a spatial join from a FEMA layer and Taxparcels it get multiple Fema zones like 'AEXXXAEXAE', 'AEAEXAEAEXAEAEAEXAEXAEXAEX'. I use the following + """FEMA_ZONE "FEMA_ZONE" true false false 60 Text 0 0 ,Join,#,"""+ FEMA09 + """,FLD_ZONE,-1,-1;"""\. I know the tool is doing what it is suppose to be doing. There is multiple "X" and "AE" zones that overlap this parcel. For the most part there are hundreds like this. Is there a why for example to just put "AE,X" instead of "AEAEXAEAEXAEAEAEXAEXAEXAEX". The only thing i can think of is to write and update cursor for each different FEMA_ZONE, but that would alot of update Cursor's.
I would appreciate any help, thanks.
Solved! Go to Solution.
{kind=link}
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
cursor.updateRow(row) needs to be un-indedented (aka dedented) one level to line up with the last elif, otherwise, the update for previous conditions won't occur
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
does it return a string or a list?
are these all the conditions or are there others?
Are they all different lengths?
are they unique in their first letter? or do you have AE AD etc
are they always text or do some begin with or contain numbers?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Its a string
These are all the conditions
yes they have different lengths
In the FEMA Layer they are only 'A', 'AE', 'AH', 'AO' or 'X'
Just text ('A', 'AE', 'AH', 'AO' or 'X')
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
and there is no separator in the result at all? like a space? I am just trying to figure out how they all got concatenated together in the first place
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
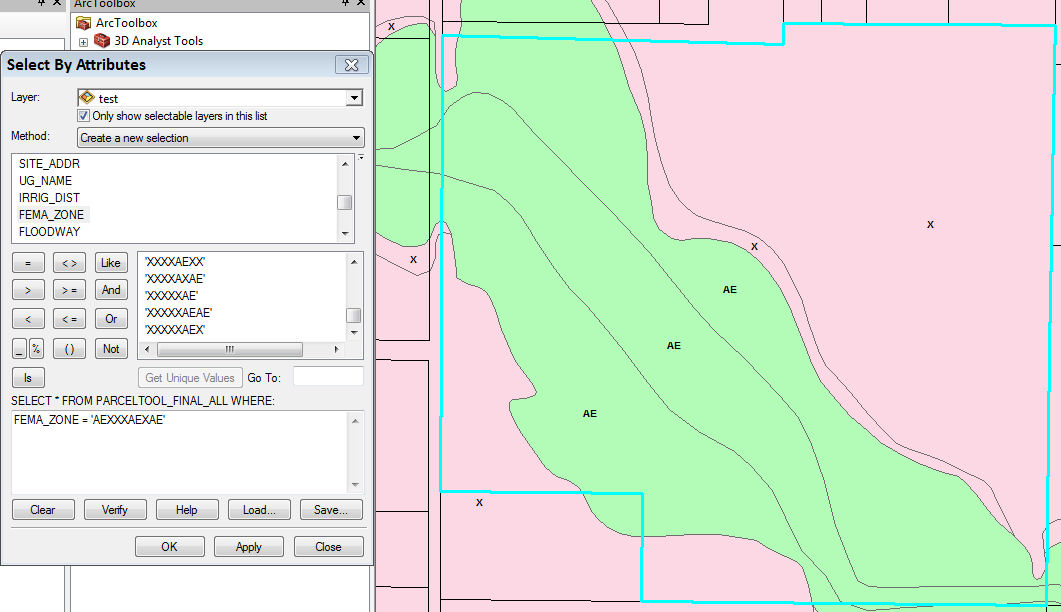
No there are not separators. In the attached picture the blue highlighted is the parcel and you can see that FEMA_ZONES 'X', 'AE', 'AE', 'AE', 'X', 'X' intersect the parcel so it's adding/joining all the FEMA_ZONES into one attribute 'AEXXXAEXAE' which i believe that's what it is suppose to do. i just need it to have AE/X or AE,X i don't need all the extra AE's and X's.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The only case ruining a really simple solution is the single occurence of case 'A', but that can be overcome b y subtracting the result of the sum of all the cases that begin with 'A' from the other combinations. Here is a start
>>> combos = ['A', 'AE', 'AH', 'AO', 'X']
>>> case = "AAAEAHAHXAOAEAXAOAH"
>>> num = [[i, case.count(i)] for i in combos]
>>> num
[['A', 10], ['AE', 2], ['AH', 3], ['AO', 2], ['X', 2]]
you will notice that there are 10 occurrences of 'A' but there are 2x 'AE', 3x 'AH' and 2 x 'AO for a total of 7 leaving 3 cases of pure 'A'
case = "A A AE AH AH X AO AE A X AO AH"
so it is correct.
So You can parse that into a def from the calculation should you wish to return one of each unique value, or the dominant (ie AH in this case) or whatever. I will leave that choice up to you, hope this gets you started
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You could use Dissolve—Help | ArcGIS for Desktop on your fema dataset then use spatial join then you would only have one record for each type.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dissolving the FEMA Layer seemed to reduce the number of them but completely give me the results i am after.
Thank you for the suggestions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I've been trying to do something like this but attributes don't seem to change.
with arcpy.da.UpdateCursor("In_memory\PT_Lyr", "FEMA_ZONE") as cursor:
for row in cursor:
if row[0] in ['AEX','AEXX']:
row[0] = 'AE/X'
elif row[0] in ['AAEAEXX','AAEX','AAEAEX']:
row[0] = 'A/AE/X'
elif row[0] in ['AAE','AAEAE']:
row[0] = 'A/AE'
cursor.updateRow(row)
del row- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
cursor.updateRow(row) needs to be un-indedented (aka dedented) one level to line up with the last elif, otherwise, the update for previous conditions won't occur