- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Script running slow, how to speed up?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a script that is creates a buffer around points, converts the round buffers to squares, clips a road layers with the square, then calculates the length for the clipped roads and exports data to a csv file. I have run this script before and it took roughly 3 days to complete. This time when I ran the code it's projected to take a month to mine the data. I have no idea why it might be slowing down and could really use some help figuring this out. Does anyone know how I could speed up this process?
# -*- coding: utf-8 -*-
# ---------------------------------------------------------------------------
# 2_TrapStatsAndFloatingRoadDensity.py
# Altered on: 2015-6-2 10:00 am
# Created by: L.M.Blackburn
# ArcGIS 10.1
# Notes: iterates thru orders shapefiles and creates a buffer
# around each point. The round buffer is converted to a feature envelope
# which makes a square polygon around the point. This square is used to
# clip the roads layer. Then I calculate length for the clipped roads by adding
# a field and calculating geometry. Run statistics to get the sum length
# of roads in each square. export sum length, block name, centroid of
# square out to a text file
# (2nd script for 4th part of analysis)
# Needed data: Order sublayer from VRP
# List of fields to drop
# Roads network to get length data
# ---------------------------------------------------------------------------
# Import arcpy module
import arcpy, os, sys, traceback, csv
# Set the necessary product code
import arceditor
import arcinfo
# Set workspace environment - this is where the solved route layers are located
arcpy.env.workspace = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15cont\\Orders\\'
arcpy.env.overwriteOutput = True
# --------------------Set local variables ------------------
# ---workspace for order layers
ordersLyr = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15cont\\Orders\\'
# ---workspace for buffer layers
bufferLyr = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15cont\\Buffers\\'
# ---set default buffer distance
bufDefault = "6000 Meters"
# ---workspace for envelope layers
envelopeLyr = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15cont\\Envelopes\\'
# ---workspace for route layers
routeWkspc = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15cont\\Routes\\'
# ---set workspace path for clipped roads
outDataPath = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15cont\\ClipRoads\\'
# ---set road layer - for use in clip & length
Road = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\RoadsForSnap\\SDC Edge Source.shp'
# ---fields to delete from Orders layers
dropFields = ["Descriptio", "ServiceTim", "TimeWind_1", "TimeWind_2", "TimeWind_3", "TimeWindow", "MaxViolati", "MaxViola_1", \
"PickupQuan", "DeliveryQu", "Revenue", "SpecialtyN", "Assignment", "RouteName", "ViolatedCo", "CumulTrave", \
"CumulDista", "CumulTime", "ArriveCurb", "DepartCurb", "DepartTime", "WaitTime", "ViolationT", "CumulWaitT", \
"CumulViola", "ArriveTime", "SourceID", "SourceOID", "PosAlong", "SideOfEdge", "CurbApproa", "Status"]
try:
print 'Opening CSV file...'
# Step 1 - Create table for output data
# Needed fields: From script [Block, Scale, Sequence, FromPrevTr, FromPrevDi, totTime, totDist, x, y, totalRdLength]
CSVFile = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15cont\\AllTrapsData_June2.csv'
f = open (CSVFile, "wb")
w = csv.writer(f, delimiter=',', lineterminator='\n')
fieldNames = ['Block', 'Scale', 'BufferType', 'Sequence', 'FromPrevTr', 'FromPrevDi', 'x', 'y', 'bufferDist','totTime', \
'totDist', 'totalRdLength', '\n']
w.writerow(fieldNames)
# Step 2 - Loop through files in orders folder
# Create variable to hold orders feature class files
'''
orderList = arcpy.ListFiles("*.shp")
# Loop through layers & break name into segments to be used when naming orders lyrs
print 'Creating Buffers...'
for shp in orderList:
lyrs = arcpy.mapping.Layer(ordersLyr + shp)
splitName =shp.split('_')
block = splitName[0]
scale = splitName[1].rstrip('.shp')
# define buffer distance
if scale == "1K":
bufDist = "1000 Meters"
elif scale == "2K":
bufDist = "2000 Meters"
elif scale == "3K":
bufDist = "3000 Meters"
elif scale == "4K":
bufDist = "4000 Meters"
elif scale == "6K":
bufDist = "6000 Meters"
elif scale == "500":
bufDist = "500 Meters"
else:
bufDist = bufDefault
print 'Order: ' + shp + ', Buffer: ' + bufDist
# Jump into orderLayers to delete unneeded fields & add XY
arcpy.DeleteField_management(shp, dropFields)
arcpy.AddXY_management(shp)
# Step 4 - Run buffer on order layers
arcpy.Buffer_analysis(shp, bufferLyr + 'buf' + '_' + block + '_' + scale, bufDist, 'FULL', 'ROUND', 'NONE', '#')
arcpy.Buffer_analysis(shp, bufferLyr + 'buf2' + '_' + block + '_' + scale, bufDefault, 'FULL', 'ROUND', 'NONE', '#')
bufferList = []
for dpath, dnames, fnames in arcpy.da.Walk(bufferLyr, datatype = 'FeatureClass', type = 'Polygon'):
for files in fnames:
bufferList.append(os.path.join(files))
# Step 5 - Run feature envelope to polygon on buffer layers
print 'Converting round buffers to squares...'
for bufShp in bufferList:
bufSplitName = bufShp.split('_')
blockID = bufSplitName[1]
scaleID = bufSplitName[2].rstrip('.shp')
bufID = bufSplitName[0]
print 'Buffer: ' + bufShp + ' Block: ' + blockID + ' Scale: ' + scaleID + ' BufferType: ' + bufID
arcpy.FeatureEnvelopeToPolygon_management(bufferLyr + bufShp, envelopeLyr + bufID + '_' + blockID + '_' + scaleID, 'SINGLEPART')
'''
# Step 6 - Calculate totalTime and totalDistance using insert cursor
# loop through each record in the table - calculate values and...
# use selected features to clip roads layer & calculate geometry
# add values to the CSV table
print 'Populating CSV file...'
envelopeList = []
for dirpath, dirnames, filenames in arcpy.da.Walk(envelopeLyr, datatype = 'FeatureClass', type = 'Polygon'):
for filename in filenames:
envelopeList.append(os.path.join(filename))
for eLayer in envelopeList:
eLayerName = eLayer.split('_')
blockEID = eLayerName[1]
scaleEID = eLayerName[2].rstrip('.shp')
bufEID = eLayerName[0]
print 'eLayer: ' + eLayer + ' Block: ' + blockEID + ' Scale: ' + scaleEID + ' BufferType: ' + bufEID
eLyrPath = envelopeLyr + eLayer
#Make a layer from the feature class - needed for selecting records to be used in the clipping
arcpy.MakeFeatureLayer_management(eLyrPath, "clipLayer")
# use search cursor to grab data row by row to populate CSV file
with arcpy.da.SearchCursor(eLyrPath, ("Sequence", "FromPrevTr", "FromPrevDi", "POINT_X", "POINT_Y",
"BUFF_DIST")) as cursor:
for row in cursor:
dataList = []
dataList.append(str(blockEID))
dataList.append(str(scaleEID))
dataList.append(str(bufEID))
dataList.append(str(row[0]))
dataList.append(str(row[1]))
dataList.append(str(row[2]))
dataList.append(str(row[3]))
dataList.append(str(row[4]))
dataList.append(str(row[5]))
n = int(row[0])
sN = "=" + str(n)
n2 = n +1
sel = "=" + str(n2)
prevTime = float(row[1])
prevDist = float(row[2])
# print sN
postTime = ""
# use a nested search to get values for total time and total distance
# there are some cases where the below expression will be false in that
# event we will need to cacluclate the distance to the depot or just leave
# the values for prevTime & prevDist as place holders, otherwise I end up with
# road length being written in the wrong field
expression = arcpy.AddFieldDelimiters(eLyrPath, "Sequence")+ sel
for row2 in arcpy.da.SearchCursor(eLyrPath, ("FromPrevTr", "FromPrevDi"), expression):
postTime = row2[0]
totTime = prevTime + float(postTime)
# print totTime
dataList.append(str(totTime))
postDist = row2[1]
# print postDist
totDist = prevDist + float(postDist)
# print totDist
dataList.append(str(totDist))
# if above for loop yeilds no results, calculate postTime and postDist differently
# grab DepotVisits layer - if VisitType = "End" then grab values for "FromPrevTravelTime" & "FromPrevDistance"
if postTime == "":
#select corresponding route layer file and grab sublayer: DepotVisits
print "extracting time & distance to Depot"
routeLyr = arcpy.mapping.Layer(routeWkspc + "TrapRoute_" + blockEID + "_" + scaleEID + ".lyr")
if routeLyr.isGroupLayer:
for sublyrs in routeLyr:
# print sublyrs.name
if sublyrs.name == 'Depot Visits':
arcpy.MakeFeatureLayer_management(sublyrs, "depotVisits")
qLast = "= 2"
expression2 = arcpy.AddFieldDelimiters("depotVisits", "VisitType")+ qLast
for row3 in arcpy.da.SearchCursor("depotVisits", ("FromPrevTravelTime", "FromPrevDistance"), expression2):
postTime2 = row3[0]
totTime2 = prevTime + float(postTime2)
# print ("Depot Visit Time: {0}, {1}, {2}".format(prevTime, postTime2, totTime2))
dataList.append(str(totTime2))
postDist2 = row3[1]
totDist2 = prevDist + float(postDist2)
# print ("Depot Visit Distance: {0}, {1}, {2}".format(prevDist, postDist2, totDist2))
dataList.append(str(totDist2))
# select single record to use when clipping - this selection must be on a layer not fc
# always create where clause using AddFieldDelimiters
seqField = "Sequence"
where_clause = arcpy.AddFieldDelimiters("clipLayer", seqField)+ sN
arcpy.SelectLayerByAttribute_management("clipLayer", "NEW_SELECTION", where_clause)
# Clip roads w/ selected polygon - for this I will need a search cursor
clipRoads = outDataPath + 'rdsClip_' + blockEID + '_' + scaleEID + '_' + bufEID + '_' + str(n)
arcpy.Clip_analysis(Road, "clipLayer", clipRoads)
clipRoadsShp = clipRoads + ".shp"
# Use geometry/length to get the total length of clipped roads(in meters)
g = arcpy.Geometry()
geometryList = arcpy.CopyFeatures_management(clipRoadsShp, g)
length = 0
for geometry in geometryList:
length +=geometry.length
# append length (meters) at end of line to csv dataList
dataList.append(str(length))
# dataList.append('\r\n')
# print length
# Write dataList to csv file ---- may need to dedent this one more time ---
w.writerow(dataList)
# print dataList
print 'Script complete'
f.close()
except:
if arcpy.Exists(CSVFile):
w.writerow(dataList)
print 'Data written in CSV file'
f.close()
print 'Program failed.'
print 'Check python errors.'
tb = sys.exc_info()[2]
tbinfo = traceback.format_tb(tb)[0]
pymsg = "PYTHON ERRORS:\nTraceback Info:\n" + tbinfo + "\nError Info:\n " + str(sys.exc_type) + ": " + str(sys.exc_value) + "\n"
msgs = "ARCPY ERRORS:\n" + arcpy.GetMessages(2) + "\n"
arcpy.AddError(msgs)
arcpy.AddError(pymsg)
print msgs
print pymsg
arcpy.AddMessage(arcpy.GetMessages(1))
print arcpy.GetMessages(1)
# print ("Points to select: {0}, Radius: {1}".format(centroidPath, radius))
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
# -*- coding: utf-8 -*-
# ---------------------------------------------------------------------------
# 2_FastTrapStatsAndFloatingRoadDensity.py
# Altered on: 2015-6-8 10:00 am
# Created by: L.M.Blackburn
# ArcGIS 10.1
# Notes: Buffers and envelopes were created in first run-through of this code.
# Now, I calculate length for the clipped roads by adding
# a field and calculating geometry. Run statistics to get the sum length
# of roads in each square. export sum length, block name, centroid of
# square out to a text file. I'm making edits on this version to run
# the code on Citrix and to speed up the entire process using dictionary
# keys instead of nested cursors.
# (2nd script for 4th part of analysis)
# Needed data: Order sublayer from VRP
# List of fields to drop
# Roads network to get length data
# ---------------------------------------------------------------------------
# Import arcpy module
import arcpy, os, sys, traceback, csv
from time import strftime
# Set the necessary product code
import arceditor
import arcinfo
# Set workspace environment - this is where the solved route layers are located
arcpy.env.workspace = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15\\Orders\\'
arcpy.env.overwriteOutput = True
# --------------------Set local variables ------------------
# ---workspace for order layers
ordersLyr = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15\\Orders\\'
# ---workspace for buffer layers
bufferLyr = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15\\Buffers\\'
# ---set default buffer distance
bufDefault = "6000 Meters"
# ---workspace for envelope layers
envelopeLyr = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15\\Envelopes\\'
# ---workspace for route layers
routeWkspc = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15\\Routes\\'
# ---set workspace path for clipped roads
outDataPath = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15\\ClipRoad\\'
# ---set road layer - for use in clip & length
Road = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\RoadsForSnap\\SDC Edge Source.shp'
# ---fields to delete from Orders layers
dropFields = ["Descriptio", "ServiceTim", "TimeWind_1", "TimeWind_2", "TimeWind_3", "TimeWindow", "MaxViolati", "MaxViola_1", \
"PickupQuan", "DeliveryQu", "Revenue", "SpecialtyN", "Assignment", "RouteName", "ViolatedCo", "CumulTrave", \
"CumulDista", "CumulTime", "ArriveCurb", "DepartCurb", "DepartTime", "WaitTime", "ViolationT", "CumulWaitT", \
"CumulViola", "ArriveTime", "SourceID", "SourceOID", "PosAlong", "SideOfEdge", "CurbApproa", "Status"]
# ---fields for CSV file
fieldNames = ['Block', 'Scale', 'BufferType', 'Sequence', 'FromPrevTr', 'FromPrevDi', 'x', 'y', 'bufferDist','totTime', \
'totDist', 'totalRdLength', '\n']
# ---List of fields from envelope layer from which to extract data
sourceFieldsList = ["Sequence", "FromPrevTr", "FromPrevDi", "POINT_X", "POINT_Y", "BUFF_DIST"]
try:
print 'Script started at: ' + strftime("%Y-%m-%d %H:%M:%S")
print 'Opening CSV file...'
# Step 1 - Create table for output data
# Needed fields: From script [Block, Scale, Sequence, FromPrevTr, FromPrevDi, totTime, totDist, x, y, totalRdLength]
with open('F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15\\AllTrapsData_June9_new.csv', "wb") as f:
w = csv.writer(f, delimiter=',', lineterminator='\n')
w.writerow(fieldNames)
# Calculate totalTime and totalDistance using insert cursor
# loop through each record in the table - calculate values and...
# use selected features to clip roads layer & calculate geometry
# add values to the CSV table
print 'Populating CSV file...'
envelopeList = []
for dirpath, dirnames, filenames in arcpy.da.Walk(envelopeLyr, datatype = 'FeatureClass', type = 'Polygon'):
for filename in filenames:
envelopeList.append(os.path.join(filename))
for eLayer in envelopeList:
eLayerName = eLayer.split('_')
blockEID = eLayerName[1]
scaleEID = eLayerName[2].rstrip('.shp')
bufEID = eLayerName[0]
#print 'eLayer: ' + eLayer + ' Block: ' + blockEID + ' Scale: ' + scaleEID + ' BufferType: ' + bufEID
eLyrPath = envelopeLyr + eLayer
#Make a layer from the feature class - needed for selecting records to be used in the clipping
arcpy.MakeFeatureLayer_management(eLyrPath, "clipLayer")
#-----------------------pasted code below----------------------
sourceFC = None
#select corresponding route layer file and grab sublayer: DepotVisits
print 'extracting time & distance to points. eLayer: ' + eLayer + ' Block: ' + blockEID + ' Scale: ' + scaleEID + ' BufferType: ' + bufEID
routeLyr = arcpy.mapping.Layer(routeWkspc + "TrapRoute_" + blockEID + "_" + scaleEID + ".lyr")
if routeLyr.isGroupLayer:
for sublyrs in routeLyr:
# print sublyrs.name
if sublyrs.name == 'Depot Visits':
arcpy.MakeFeatureLayer_management(sublyrs, "depotVisits")
sourceFC = "depotVisits"
qLast = "= 2"
expression2 = arcpy.AddFieldDelimiters("depotVisits", "VisitType")+qLast
depotFieldsList = ["VisitType", "FromPrevTravelTime", "FromPrevDistance"]
depotVisitsDict = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(sourceFC, depotFieldsList, expression2)}
sourceFC = eLyrPath
# Use list comprehension to build a dictionary from a da SearchCursor
sequenceDict = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(sourceFC, sourceFieldsList)}
for key in sequenceDict:
dataList = []
dataList.append(str(blockEID))
dataList.append(str(scaleEID))
dataList.append(str(bufEID))
dataList.append(str(key))
dataList.append(str(list(sequenceDict[key])[0]))
dataList.append(str(list(sequenceDict[key])[1]))
dataList.append(str(list(sequenceDict[key])[2]))
dataList.append(str(list(sequenceDict[key])[3]))
dataList.append(str(list(sequenceDict[key])[4]))
n = int(key)
sN = "=" + str(n)
n2 = n +1
sel = "=" + str(n2)
prevTime = float(list(sequenceDict[key])[0])
prevDist = float(list(sequenceDict[key])[1])
#print prevTime
#print prevDist
postTime = ""
# use a nested search to get values for total time and total distance
# this loop is not running - I am not getting these values written to
# the CSV table
if n2 in sequenceDict:
#values = list(sequenceDict[n2])
#for row2 in values:
postTime = float(sequenceDict[n2][0])
totTime = prevTime + postTime
dataList.append(str(totTime))
postDist = float(sequenceDict[n2][1])
totDist = prevDist + float(postDist)
dataList.append(str(totDist))
# if above for loop yeilds no results, calculate postTime and postDist differently
# grab DepotVisits layer - if VisitType = "End" then grab values for "FromPrevTravelTime" & "FromPrevDistance"
if postTime == "":
#select corresponding route layer file and grab sublayer: DepotVisits
print "extracting time & distance to Depot"
if 2 in depotVisitsDict:
row3 = list(depotVisitsDict[2])
postTime2 = row3[1]
totTime2 = prevTime + float(postTime2)
print ("Depot Visit Time: {0}, {1}, {2}".format(prevTime, postTime2, totTime2))
dataList.append(str(totTime2))
postDist2 = row3[2]
totDist2 = prevDist + float(postDist2)
# print ("Depot Visit Distance: {0}, {1}, {2}".format(prevDist, postDist2, totDist2))
dataList.append(str(totDist2))
# ----------------------pasted code above----------------------
print "Sequence: " + sN + ", Block: " + blockEID + ", Scale: " + scaleEID
# select single record to use when clipping - this selection must be on a layer not fc
# always create where clause using AddFieldDelimiters
seqField = "Sequence"
where_clause = arcpy.AddFieldDelimiters("clipLayer", seqField)+ sN
arcpy.SelectLayerByAttribute_management("clipLayer", "NEW_SELECTION", where_clause)
# Clip roads w/ selected polygon - for this I will need a search cursor
#clipRoads = outDataPath + 'rdsClip_' + blockEID + '_' + scaleEID + '_' + bufEID + '_' + str(n)
#arcpy.Clip_analysis(Road, "clipLayer", clipRoads)
#clipRoadsShp = clipRoads + ".shp"
clipRoadsShp = arcpy.Clip_analysis(Road, "clipLayer", "in_memory")
# Use geometry/length to get the total length of clipped roads(in meters)
print "calculating road lengths...."
g = arcpy.Geometry()
geometryList = arcpy.CopyFeatures_management(clipRoadsShp, g)
length = 0
for geometry in geometryList:
length +=geometry.length
# append length (meters) at end of line to csv dataList
dataList.append(str(length))
# dataList.append('\r\n')
#print length
arcpy.Delete_management(clipRoadsShp)
# Write dataList to csv file ---- may need to dedent this one more time ---
w.writerow(dataList)
# print dataList
print 'Script completed at: ' + strftime("%Y-%m-%d %H:%M:%S")
f.close()
except:
f.close()
print 'Program failed at: ' + strftime("%Y-%m-%d %H:%M:%S")
print 'Check python errors.'
tb = sys.exc_info()[2]
tbinfo = traceback.format_tb(tb)[0]
pymsg = "PYTHON ERRORS:\nTraceback Info:\n" + tbinfo + "\nError Info:\n " + str(sys.exc_type) + ": " + str(sys.exc_value) + "\n"
msgs = "ARCPY ERRORS:\n" + arcpy.GetMessages(2) + "\n"
arcpy.AddError(msgs)
arcpy.AddError(pymsg)
print msgs
print pymsg
arcpy.AddMessage(arcpy.GetMessages(1))
print arcpy.GetMessages(1)
# print ("Points to select: {0}, Radius: {1}".format(centroidPath, radius))
Thanks so much, Richard, for all the time you are devoting to my problem! The above code is currently working, though it's still slow.
I have 360 polygon layers in the envelopeList that I am using to clip a roads layer. Each layer in the envelopeList has multiple polygons and I am calculating the length of roads that fall inside each polygon (which corresponds to the sequence field ID) to add to the CSV file. I suppose this could be done for all of the polygons in a layer instead of one polygon at a time, then join the data back using the sequence id and a dictionary?
My original code was created by me in whatever manner I could make it work. I do not have formal programming experience and I am a wildlife biologist by training, so I have learned python on my own as I need to mine data for work. I am sure that my code is not elegant, but I am learning a ton! I know there are always many ways of getting at the same end result, and I simply use whatever methods I understand. So, if there's a better way, I am all ears! I would much rather have this process through my files in days instead of weeks! So any time saving tips are greatly appreciated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
clipping one record at a time adds two minutes per loop! And calculating the geometry only takes a second. So, if there's a better way to perform the clip that would save me a ton of time!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I don't use clip much for my work, so I cannot be sure what result occurs if you did all of the envelops against all of the sequence polygons at once for one of the 360 envelope layers, but that is worth a try. The set up of the dictionary for the output can use the One To Many approach to compile a summary of lengths directly for all clipped shapes based on the sequence IDs rather than a list of lists. So for example it can be structured like:
envelopeFieldsList = ["Sequence", "Shape@"]
envelopeDict = {}
with arcpy.da.SearchCursor(envelopeFC, envelopeFieldsList) as envelopes:
for envelope in envelopes:
relatekey = envelope[0]
geometry = envelope[1]
if relatekey in envelopeDict:
envelopeDict[relatekey] += geometry.length
else:
envelopeDict[relatekey] = geometry.length
I would expect that you would have many envelopes clipping the same sequence polygon, so the code above would probably have to be modified to keep track of an envelope ID field for each summarized value in addition to the Sequence number I would need to know more about the output of the multiple envelope clip from your data before proposing how to do that.
Of course you should time the multiple envelope clip to be sure that the batch process saves time by avoiding the clip set up steps of the individualized process. Figure out how many objects in both layers are being clipped and multiply that by the 2 minutes you have measured for a single envelope to compare to the time spent doing the batch process. If there is a significant time savings than that approach is worthwhile, but if it is negligible than the clip operation needs to be reexamined to find out if there are alternative ways to reach the final goal. For example, Intersect may work and may (or may not) be faster.
Also look at the help here. It may work faster to do clip geometry operations directly on geometry objects using geometry envelopes rather than using the clip tool. There is a good chance this would save some time, since it would not waste time creating a feature class schema or outputting a feature class to disk or memory, since you can don't seem to need that and could handle the field schema through integrating dictionary data.
Anyway, code optimization usually is a result of the process we are going through, You have to start with what you know and what works and then isolate speed bottlenecks and develop alternatives until further optimization becomes impossible or too costly for the potential benefit. It is normally a learning experience. Necessity is the mother of invention.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
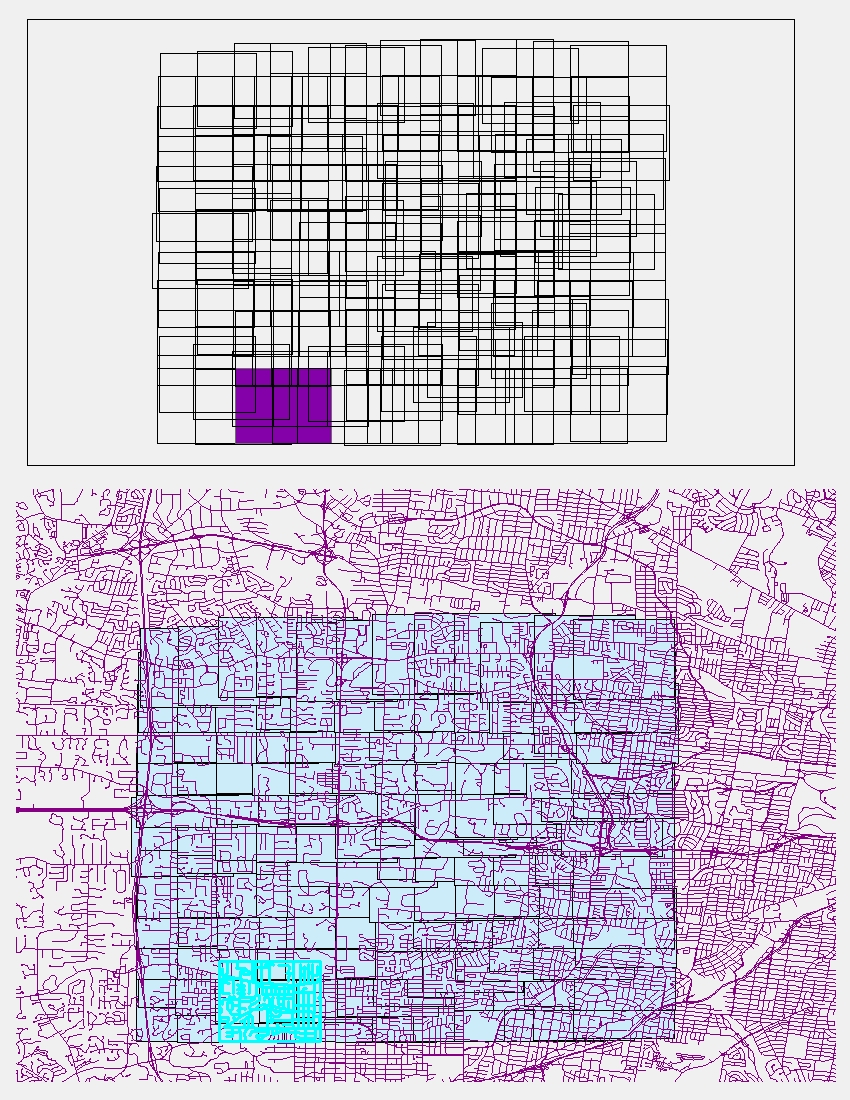
Thanks Richard for all of your time and for walking me through all these new (to me) techniques. I attached a jpg that will hopefully show you what I am trying to accomplish. The top image is one of my "envelope" layers with one record (aka. sequence id) shown in purple out of 144 records. The bottom image shows the envelope layer with the road layer that is being clipped. What I want to return for each sequence is the length of the roads that are inside that individual polygon. This is why I used a clip and not simply a selection. When I perform a selection (which is done in the bottom image), I do not get a complete record of the roads that fall inside the selected polygon. Some roads are left out, as shown below. What I am ultimately trying to determine is the road density inside each polygon and to compute that I need to know the total length of roads that are inside of the polygon. Let me know if you have any ideas on getting at this data in a different manner, as the clipping and selecting both seem to take up lots of time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am not sure I understand what I am seeing regarding the difference between clip and selection. I don't really understand the analysis taking place with this code, so I am not sure what is best to suggest. It also seems like you are getting the lengths of the n2 sequence, not the n sequence, and I am not sure why.
In any case, if every road must ultimately be intersected by every envelope, please try the Intersection tool with an output of Lines. Output to a file geodatbase feature class, not a shapefile (stop using shapefiles, I beg you), so that the length of the roads is automatically provided for you. Keep track of the time it takes to process to make sure it completes in much less time than 288 minutes (I expect it will take roughly 5 to 10 minutes).
Then open the feature class table view, select one of the sequence IDs you already know the length for and get the statistics of the length field (right click, statistics). If it is the same length (you should ignore any difference below 1/10th of a meter or at most 1/100th of a meter, since file geodatabases provide higher precision shapes than shapefiles), we can run intersect before any of the loops we have been altering and can use that output for all sequence lengths in the final step using the dictionary summary I mentioned. If I am right, this will eliminate days of processing to complete your entire dataset.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Richard,
I know it's a crazy analysis. I am data mining in order to build a model that will help lessen surveillance trapping costs of the gypsy moth. I used Network analyst to create a number of routes, at multiple distances between traps, in various locations in the US. Now I am going into the routing data and extracting information on the time it takes to visit each trap location. So, I am populating a CSV table that has the following data: block, scale (distance between traps), sequence (order of trap placement along route), time from previous trap, distance from previous trap, x, y, total time, total distance and road length.
The envelope layers have all of the data from the trap placement/routing. So, from those layers I am grabbing the time and distance from the previous trap for sequence N and adding that value to the time and distance from the previous trap for sequence N+1. So yes, I am using both N and N+1 data and combining them to eventually get the average time and distance for each and every trap location. When the sequence is the last one along a route, I need to grab the value from the depot visits layer (this value doesn't exist in the envelope layer).
Also for each trap location, I want to know the average road density in the local area and at the regional scale. My envelopes were created at two scales, one is for computing the local area's road density and the other is for calculating the regional road density. This is why I was doing the clipping. I am currently looking into your intersect method and agree that this might be a quicker way to go. And yes, I tend to default to shapefiles I guess that dates me, as I learned GIS at the ArcView 3.2 version. I will try to stop doing that too.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am a bit unclear on how to write the syntax for performing the intersect method. I used your suggestion, Richard, with a dictionary to store the geometries of each record in the envelope layer. However, line 7 is where I get confused (I added this and I know it's not written right). I am sure at some point I need to tell it to intersect the road layer and output lines, in order to pass the length to the dictionary. Then I need to pass the length of those lines that are intersecting the envelope back to the CSV file, via dataList.append(length). I think line 9 calculates the length and passes it back to the dictionary, though I don't understand what envelopeDict[relateKey] does. Is this just appending it to the dictionary or is it replacing the relateKey? At the moment, I am thinking this snippet of code should follow all the other dictionaries and be just above the line where the dataList is written to the CSV file.
envelopeFieldsList = ["Sequence", "Shape@"]
envelopeDict = {}
with arcpy.da.SearchCursor("clipLayer", envelopeFieldsList) as envelopes:
for envelope in envelopes:
relateKey = envelope[0]
geometry = envelope[1]
geometry.intersect(Road, 2)
if relateKey in envelopeDict:
envelopeDict[relateKey] += geometry.length
else:
envelopeDict[relateKey] = geometry.length
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I meant for you to use the Intersect_Analysis tool and intersect all envelopes against all roads before doing any dictionaries. Try the Intersect_Analysis tool. It will work, I am almost certain. This one envelope at a time approach is a bad approach. I virtually never do that. I really think that Intersecting every envelope once against every road will be faster and produce the same results. Until I have proof that won't work I am not interested in individually processing the envelopes and think that is a waste of time. Cliplayer is the complete set of the intersected roads against the complete set of envelopes and my code needed no modification (at least not until I know what the full Intersect contains).
The code is reading every road segment of the Intersect output with an envelope sequence ID and summing the road lengths, which is all your code does as far I can see. In reality this code happens before any other dictionary is created, and when you get to the part of the script that needs that length you just read the envelopeDict[sequenceID][0] value.
I am asking for you to at least test the one feature set you displayed in your picture to get a processing time and to verify that the length reported is equivalent to your currently working slow process. If it is meets your requirements for speed and accuracy, then there may be no real need to do individualized processing. If I go to the trouble to build code for more individualized processing I will require that you have done this for a comparison anyway. Otherwise you will not have done a complete set of optimization tests in my view and will have left out a critical alternative that I believe will beat any individualized process (until proven otherwise based on a comparison of speed or erroneous reported results).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for the clarification Richard. I was thinking I needed to use the polygon intersect and couldn't find any examples of using that method. I am working on adding the intersect_analysis tool now and hope to test it out shortly. It seems to do exactly what I want when performed in ArcMap. So, now it's all a matter of speed. I agree with you about doing this part first and using all the polygons in each envelope layer at one time instead of doing the polygons individually.
I am still trying to understand the dictionary, it's a bit fuzzy to me how you recall the correct field values. So, I'll have to do a bit more reading.
Thanks again for all of your time! It is so incredibly helpful to be able to get such quick feedback from such a knowledgeable group.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Richard, many thanks for all of your insight. I think this will be a much faster process. I can complete the intersect for each layer in roughly 2 minutes, which translates to about 12 hrs to complete the entire code. I'll paste the code here so you can take a look at it. I created a dictionary to hold the summary statistics and recalled the data from that dictionary at the end of my loops. Let me know if you see any glaring errors.
# --------------------Set local variables ------------------
# ---workspace for envelope layers
envelopeLyr = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15\\Envelopes\\'
# ---workspace for route layers
routeWkspc = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15\\Routes\\'
# ---set road layer - for use in clip & length
Road = 'F:\\Workspace\\Sandy\\GM_costAnalysis\\RoadsForSnap\\SDC Edge Source.shp'
# ---fields for CSV file
fieldNames = ['Block', 'Scale', 'BufferType', 'Sequence', 'FromPrevTr', 'FromPrevDi', 'x', 'y', 'bufferDist','totTime', \
'totDist', 'totalRdLength', '\n']
# ---List of fields from envelope layer from which to extract data
sourceFieldsList = ["Sequence", "FromPrevTr", "FromPrevDi", "POINT_X", "POINT_Y", "BUFF_DIST"]
try:
print 'Opening CSV file at: ' + strftime("%Y-%m-%d %H:%M:%S")
# Step 1 - Create table for output data and add field names
with open('F:\\Workspace\\Sandy\\GM_costAnalysis\\analysisMay15\\AllTrapsData_Speedy_June11.csv', "wb") as f:
w = csv.writer(f, delimiter=',', lineterminator='\n')
w.writerow(fieldNames)
# Calculate totalTime and totalDistance using insert cursor
# loop through each record in the table - calculate values and...
# use selected features to clip roads layer & calculate geometry
print 'Creating Dictionaries...'
envelopeList = []
for dirpath, dirnames, filenames in arcpy.da.Walk(envelopeLyr, datatype = 'FeatureClass', type = 'Polygon'):
for filename in filenames:
envelopeList.append(os.path.join(filename))
for eLayer in envelopeList:
eLayerName = eLayer.split('_')
blockEID = eLayerName[1]
scaleEID = eLayerName[2].rstrip('.shp')
bufEID = eLayerName[0]
print 'eLayer: ' + eLayer + ' Block: ' + blockEID + ' Scale: ' + scaleEID + ' BufferType: ' + bufEID
eLyrPath = envelopeLyr + eLayer
#Make a layer from the feature class - needed for selecting records to be used in the clipping
arcpy.MakeFeatureLayer_management(eLyrPath, "clipLayer")
#Use Intersect_Analysis tool to clip all of the roads by the envelopes
print "intersect begins: " + strftime("%Y-%m-%d %H:%M:%S")
inFeatures = [Road, "clipLayer"]
intersectOutput = "intersect" + blockEID + "_" + scaleEID + "_" + bufEID
arcpy.Intersect_analysis(inFeatures, intersectOutput, 'ALL','1 Meter', 'LINE')
print "intersect ends: " + strftime("%Y-%m-%d %H:%M:%S")
#Use Statistics_analysis tool to get the sum length per sequence in each envelope
statsOutput = 'stats_' + blockEID + '_' + scaleEID + '_' + bufEID
statsFields = [["length_m", "SUM"]]
caseField = "Sequence"
arcpy.Statistics_analysis(intersectOutput, statsOutput, statsFields, caseField)
#Create a dictionary to hold road length data
statsFieldsList = ["Sequence", "SUM_length_m"]
statsDict = {r[0]:(r[1:])for r in arcpy.da.SearchCursor(statsOutput, statsFieldsList)}
#-----------------------code below-Thanks to Richard Fairhurst----------------------
sourceFC = None
#select corresponding route layer file and grab sublayer: DepotVisits
print 'extracting time & distance to points. BufferType: ' + bufEID
routeLyr = arcpy.mapping.Layer(routeWkspc + "TrapRoute_" + blockEID + "_" + scaleEID + ".lyr")
if routeLyr.isGroupLayer:
for sublyrs in routeLyr:
# print sublyrs.name
if sublyrs.name == 'Depot Visits':
arcpy.MakeFeatureLayer_management(sublyrs, "depotVisits")
sourceFC = "depotVisits"
qLast = "= 2"
expression2 = arcpy.AddFieldDelimiters("depotVisits", "VisitType")+qLast
depotFieldsList = ["VisitType", "FromPrevTravelTime", "FromPrevDistance"]
depotVisitsDict = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(sourceFC, depotFieldsList, expression2)}
sourceFC = eLyrPath
# Use list comprehension to build a dictionary from a da SearchCursor
sequenceDict = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(sourceFC, sourceFieldsList)}
for key in sequenceDict:
dataList = []
dataList.append(str(blockEID))
dataList.append(str(scaleEID))
dataList.append(str(bufEID))
dataList.append(str(key))
dataList.append(str(list(sequenceDict[key])[0]))
dataList.append(str(list(sequenceDict[key])[1]))
dataList.append(str(list(sequenceDict[key])[2]))
dataList.append(str(list(sequenceDict[key])[3]))
dataList.append(str(list(sequenceDict[key])[4]))
n = int(key)
sN = "=" + str(n)
n2 = n +1
sel = "=" + str(n2)
prevTime = float(list(sequenceDict[key])[0])
prevDist = float(list(sequenceDict[key])[1])
#print prevTime
#print prevDist
postTime = ""
# use a nested search to get values for total time and total distance
if n2 in sequenceDict:
#values = list(sequenceDict[n2])
#for row2 in values:
postTime = float(sequenceDict[n2][0])
totTime = prevTime + postTime
dataList.append(str(totTime))
postDist = float(sequenceDict[n2][1])
totDist = prevDist + float(postDist)
dataList.append(str(totDist))
# if above for loop yeilds no results, calculate postTime and postDist differently
# grab DepotVisits layer - if VisitType = "End" then grab values for "FromPrevTravelTime" & "FromPrevDistance"
if postTime == "":
#select corresponding route layer file and grab sublayer: DepotVisits
print "extracting time & distance to Depot"
if 2 in depotVisitsDict:
row3 = list(depotVisitsDict[2])
postTime2 = row3[0]
totTime2 = prevTime + float(postTime2)
# print ("Depot Visit Time: {0}, {1}, {2}".format(prevTime, postTime2, totTime2))
dataList.append(str(totTime2))
postDist2 = row3[1]
totDist2 = prevDist + float(postDist2)
# print ("Depot Visit Distance: {0}, {1}, {2}".format(prevDist, postDist2, totDist2))
dataList.append(str(totDist2))
# Grab road length values from the statsDict
if n in statsDict:
length = float(statsDict[0])
print length
dataList.append(str(length))
# Write dataList to csv file ---- may need to dedent this one more time ---
w.writerow(dataList)
print 'Road length calculated ' + strftime("%Y-%m-%d %H:%M:%S")
# print dataList
print 'Script completed at: ' + strftime("%Y-%m-%d %H:%M:%S")
f.close()