- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Python hashlib to compare shapefiles\feature c...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Python hashlib to compare shapefiles\feature classes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'd like to find out if anyone within the community has used Python hashlib to compare shapefiles or feature classes. Would you need to compare the geometry and records to figure out if the shapefiles or feature classes are the same. Any advice in how I can use python hashes to compare shapefiles or feature classes will be appreciated.
Regards
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi
I attempted this a few years back, the code from my tool is attached.
Really I was wanting to mimic the ChangeDetector transformer in Data Interoperability/FME.
If you have real work to do buy Data Interoperability or FME, or if you are working with polyline features the new Detect Feature Changes tool (Advanced) might do the trick.
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
closure on this Peter?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Unfortunately, the Feature Compare tool is not smartest tool there is... If I compare two files which are the same, then the result is as expected:
FeatureClass: Shape types are the same. FeatureClass: Feature types are the same. Table: Table row counts are the same. FeatureClass: Feature class extents are the same. GeometryDef: GeometryDefs are the same. Field: Field properties are the same. Table: Table row counts are the same. SpatialReference: Spatial references are the same. Table: Rows are the same.
However if I would delete feature 2 from the featureclass, like this:
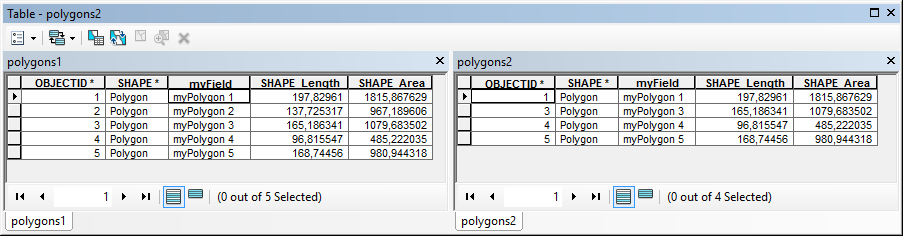
... and run the tool sorting on the common field (myField) you will notice that it compares based on the row number, not on the value in the sort field. It just sorts and compares row 2 from the base features to row 2 from the test features and will find that everything is different starting from record 2...
So hashing might be a solution...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
now... if we would hash it like this and compare both featureclasses...
import arcpy
def main():
fc1 = r"C:\GeoNet\FeatureCompare\test.gdb\polygons1"
fc2 = r"C:\GeoNet\FeatureCompare\test.gdb\polygons2"
# create dictionary for each featureclass
flds1 = getFields(fc1)
dct_fc1 = {getHashFeature(r, r[1], flds1):r[0] for r in arcpy.da.SearchCursor(fc1, flds1)}
flds2 = getFields(fc2)
dct_fc2 = {getHashFeature(r, r[1], flds2):r[0] for r in arcpy.da.SearchCursor(fc2, flds2)}
for h2, oid2 in dct_fc2.items():
if h2 in dct_fc1:
print "OID {0} from fc2 corresponds to OID {1} in fc1".format(oid2, dct_fc1[h2])
else:
print "OID {0} from fc2 has no match with features in fc1".format(oid2)
for h1, oid1 in dct_fc1.items():
if h1 in dct_fc2:
print "OID {0} from fc1 corresponds to OID {1} in fc2".format(oid1, dct_fc2[h1])
else:
print "OID {0} from fc1 has no match with features in fc2".format(oid1)
def getFields(fc):
"""Get all fields without fields to exclude like OID, Geometry, """
flds_exclude = getFieldsExclude(fc)
flds = [fld.name for fld in arcpy.ListFields(fc) if fld.name not in flds_exclude]
flds.insert(0,"SHAPE@")
flds.insert(0,"OID@")
return flds
def getFieldsExclude(fc):
"""List of fields to exclude"""
lst = []
props = ["OIDFieldName", "shapeFieldName", "areaFieldName", "lengthFieldName"]
desc = arcpy.Describe(fc)
for prop in props:
if hasattr(desc, prop):
lst.append(eval("desc.{0}".format(prop)))
return lst
def getHashFeature(row, geom, flds):
"""Hash feature (without OID, length and area fields)"""
# row: OBJECTID, SHAPE, other flds
# md5, sha1, sha224, sha256, sha384, sha512
import hashlib
dct = {}
for fld in flds[2:]:
dct[fld] = row[flds.index(fld)]
dct[flds[1]] = geom.JSON
h = hashlib.sha512(str(dct))
return h.hexdigest()
if __name__ == '__main__':
main()It returns this:
OID 3 from fc2 corresponds to OID 3 in fc1 OID 5 from fc2 corresponds to OID 5 in fc1 OID 4 from fc2 corresponds to OID 4 in fc1 OID 1 from fc2 corresponds to OID 1 in fc1 OID 3 from fc1 corresponds to OID 3 in fc2 OID 5 from fc1 corresponds to OID 5 in fc2 OID 4 from fc1 corresponds to OID 4 in fc2 OID 2 from fc1 has no match with features in fc2 OID 1 from fc1 corresponds to OID 1 in fc2
...it matches the features based on the hash (sha512) generated.
However, don't get your hopes up to high since the code is terribly slow...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi
I attempted this a few years back, the code from my tool is attached.
Really I was wanting to mimic the ChangeDetector transformer in Data Interoperability/FME.
If you have real work to do buy Data Interoperability or FME, or if you are working with polyline features the new Detect Feature Changes tool (Advanced) might do the trick.
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Bruce Harold looks promising. Will definitely have a look at it. Thanks for sharing!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I wasn't able to generate my own comparison tool, so I ended up utilizing FME Software.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
To bad to hear that you couldn't create the tool, but FME is a very good alternative. You may want to mark the answer by Harold as correct answer
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I've been trying for a while to come up with something similar and even converted Bruce's code to use multiprocessing. Below is the code that shows the most promise it will process 67000+ features and compare against 67000+ features in about a minute.
#Script to compare 2 feature classes #Author Wes Miller import arcpy import numpy as np import datetime #Print start time and date dt = datetime.datetime.now() print dt #The Feature Class to Check originFC = arcpy.GetParameterAsText(0) #The feature class with updates needed for feature class above changeFC = arcpy.GetParameterAsText(1) origDesc = arcpy.Describe(originFC) oidName = origDesc.oidFieldName field_names = arcpy.GetParameterAsText(2)#Example: "Shape","TMS","OWNERNAME","TOTBDGVAL","DISTRICT","ADD1","ADD2","ADD3","MAP","BLOCK","PARCEL","CALCULATED_ACREAGE","ADDR_SITE" originFCarr = arcpy.da.FeatureClassToNumPyArray(originFC,(field_names),null_value=-9999) originFCarrID = arcpy.da.FeatureClassToNumPyArray(originFC,(oidName)) changeFCarr = arcpy.da.FeatureClassToNumPyArray(changeFC,(field_names),null_value=-9999) changeFCarrID = arcpy.da.FeatureClassToNumPyArray(changeFC,(oidName)) print "Arrays Complete" count = 0 deletesarr = np.where(np.invert(np.in1d(originFCarr,changeFCarr))) addsarr = np.where(np.invert(np.in1d(changeFCarr,originFCarr))) adds = [] for each in addsarr[0]: adds.append(changeFCarrID[each][0]) deletes = [] for each in deletesarr[0]: deletes.append(originFCarrID[each][0]) #Current Outputs are printed here for testing purposes print adds print print deletes ndt = datetime.datetime.now() print ndt