- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- perform IDW interpolation to select multiple Z fie...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
perform IDW interpolation to select multiple Z field from attribute table using ArcPy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have 12 point feature datasets for different month. I want to perform IDW interpolation.
I have created the python code but its taking only one "Z" field for different month feature datasets from the attribute. Below I have mentioned the code. How to assign here multiple Z field from each month folder (JANUARY, FEBRUARY......DECEMBER).
Point feature class from different month folder (e.g. For January Merged_001, for FEBRUARY Merged_002.......for DECEMBER Merged_012 ) and want to perform IDW interpolation and save it as on same month folder as it Z field name (Max_Temper, Min_Temper, Precipitatat, Wind, Relative_H, Solar) with month (e.g for January 001_Max_Temper, 001_Min_Temper, 001_Precipitatat, 001_Wind, 001_Relative_H, 001_Solar).
After Whatever Solar raster for different month (for January 001_Solar....for DECEMBER 012_Solar) we will get, I want to do some calculation (001_Solar * 30) *0.5 and save it 001_sr ........012_sr in Month wise folder.
Below i have attached Point shapefile also for reference purpose
Here is my code.
import arcpy
from arcpy import env
from arcpy.sa import *
arcpy.env.parallelProcessingFactor = "100%"
arcpy.env.overwriteOutput = True
# Check out the ArcGIS Spatial Analyst extension license
arcpy.CheckOutExtension("Spatial")
env.workspace = "D:\SWAT-WEATHER-DATA2\APRIL"
# Set local variables
inPointFeatures = "D:\SWAT-WEATHER-DATA2\APRIL\Merged_004.shp"
zField = "Min_Temper" #Z_Filed = Max_Temper, Min_Temper, Precipitatat, Wind, Relative_H, Solar
cellSize = 0.002298707671
power = 2
searchRadius = RadiusVariable(10, 150000)
#Mask region of interest
mask="D:\Gujarta Shape file\GUJARATSTATE.shp"
# Execute IDW
outIDW = Idw(inPointFeatures, zField, cellSize, power, searchRadius)
# Execute Mask
IDWMASk = ExtractByMask(outIDW, mask)
# Save output, except Solar Radiation raster
IDWMASk.save("004_Min_Temp.tif")
# 004_Max_Temp.tif, 004_Min_Temp.tif....Solar
#Only for Solar Radiation raster
#PAR = (IDWMASk * 30) * 0.5
#Save output, Only for Solar Radiation raster
#PAR.save("003_sr.tif")
#print done
print 'done'Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a number of observations:
- You state that you are confused about the lagSize, majorRange, partialSill and nugget. They are all part of the semivariogram. Tools to model these parameters are available with the GeoStatistical Analyst extension. More on Kriging here: How Kriging works—Help | ArcGIS for Desktop and more specifically see the topic "Understanding a semivariogram—Range, sill, and nugget". For GeoStatistical Analyst and the sensitivity of the semivariogram, see this topic: Semivariogram Sensitivity—Help | ArcGIS for Desktop
- If you don't have the tools to define the lagSize, majorRange, partialSill and nugget correctly, it is better not to specify them.
- Your fixed radius definition should be specified in map units. If you have decimal degrees a distance of 20000 decimal degrees will be "rather" big.
When I executed the tool with the default values provided by the tool (but changing to Linear drift). The snippets of the tool executions was:
arcpy.gp.Kriging_sa("Merged_004", "Max_Temper", "D:/Xander/GeoNet/Kriging/tif/krimaxtemp01.TIF", "LinearDrift 0,023729", "2,37291946411132E-02", "FIXED 0,118646 20", "D:/Xander/GeoNet/Kriging/tif/var01.TIF")
With this result.
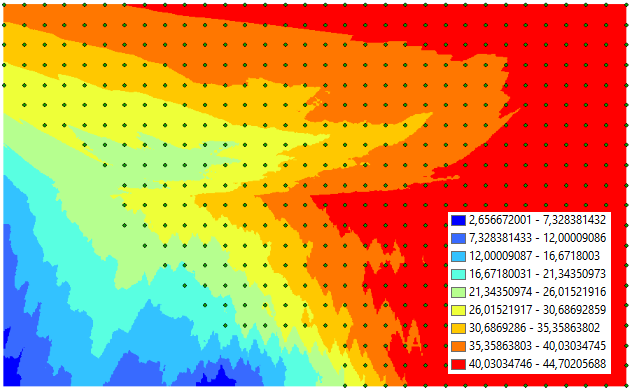
Personally, I don't think it makes much sense, but an important reason for this are the overlapping points. It would be better to get the average of the month into a single point for each location and use that instead.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
just a side note... you file paths need to be in raw format, at least (r'c:\path' ), they shouldn't contain spaces nor any character other than letters, numbers and the underscore... dashes can be problematic. The rules regarding grid workspaces are equally onerous, but I will leave that for a bit
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I downloaded the shapefile that contains the data for month 004 (April), but I noticed that you have about 514 point locations and each point location contains data for each day of the month. In this case you have 30 points at each location. When you do an IDW interpolation these values will overlay and also may make the interpolation process slower than necessary. You may want to consider summarize the data (average min and max temp, etc) for each unique location.
Also the distribution makes me think that the data originally comes from a raster format.
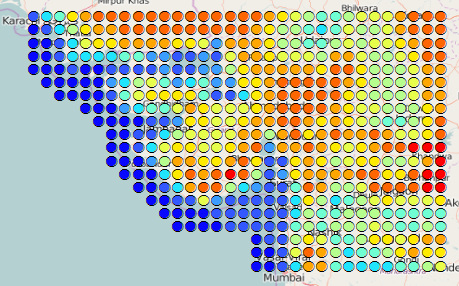
Interpolating this data as if they were individual stations, doesn't feel right. Perhaps converting them to raster (after the aggregation per location) with one location per pixel, would be a better idea. If you require a more detailed resolution you could use the Resample—Help | ArcGIS for Desktop tool, but remember that you really don't have more detail then those input points.
The get an example of how to process and calculate based on lists of data, you could have a look at this thread: Calculate list of raster from two different subfolder using ArcPy where some examples are provided.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Xander Bakker. Thank you. the point data comes from model generated output and they provides the datasets in csv format.
I don't understand, how to perform (after the aggregation per location with one location per pixel) on those data to calculate Mean value of each location for different parameters. My kind request, please guide me to the task with accurately.
Regarding interpolation daily data into a single pixel, Arc GIS has the default setting in Envs Setting: Geo-statistical Analysis : Coincident Points : Mean. So during interpolation i think its calculate the Mean value of different parameter for each location to crate a single pixel from daily data.
When i use the Arc GIS IDW tool for performing IDW then its taking some time but when i run the code in pyscripter, its not taking much time to perform interpolation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Xander correctly points out that there is no need for interpolation since the input areal units and their output values have been previously defined from the source program... they just happen to be represented by points, but they reflect an area.
...
Perhaps converting them to raster (after the aggregation per location) with one location per pixel, would be a better idea
...
If you need a finer resolution, then that should be done in the source program. Interpolation of the data you have is not necessary or appropriate.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
xander_bakker Dan_Patterson. Thank you for your kind cooperation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
To convert the points to raster, you would need to do a little fiddling with the point spacing and the origin.
Inputs to the Point to Raster tool, you would have to specify in the environments the exact cellsize of the output (equal to the spacing of the points) and also an extent which was exactly 1/2 of a cellsize offset to the west. So, in the output raster all the input points were at the centre of each output pixel.
But if you just wanted a quick picture of these points, I don't think using something like Natural neighbour interpolator would actually mess up the input data so much. And would save you a whole lot of messing about.
Perhaps Dan_Patterson would like to comment on the implications of this interp....
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
One would have to use the same interpolator as that used to generate the points in the first place. There is no assumption given that the actual points represent just that, but could be a representation of an interpolation in the first place. I always get a bit squimish about interpolating interpolations which might have been interpolated in the first place, hence, my comment about going back to source and do it again.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If I get time, I might do some testing of interpolating an interpolation....
Will feed back here..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I had a quick look at the IDW interpolation and if I use the following settings.
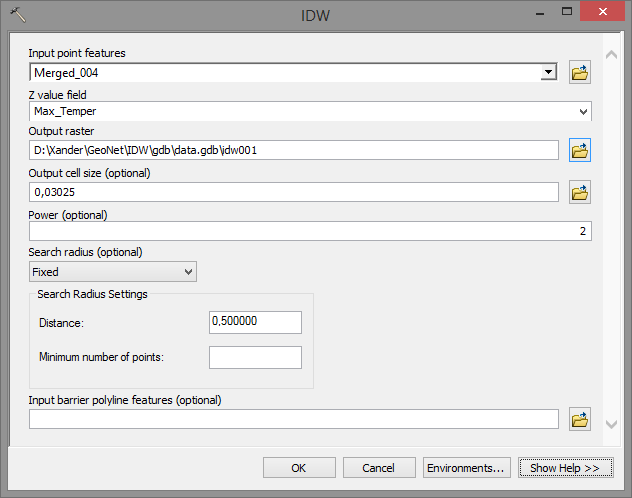
I get this result
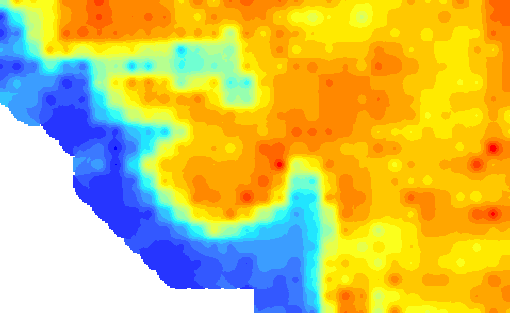
The individual points are clearly visible and generate an undesired effect. To reduce this effect you can increase the search distance:
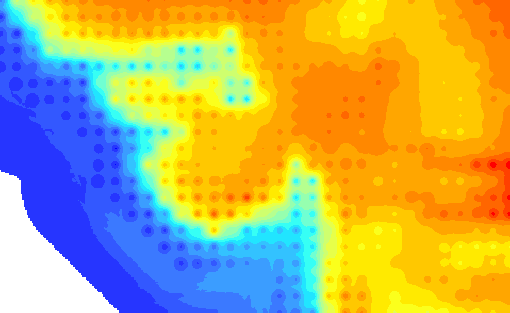
It becomes a little more smoother, but still the individual points are there. When the power is reduced to one the effect is this:

When you convert the points to raster with the "original" resolution you get this (hardly appealing) result:

If you resample this using Cubic Spline you will get this result:
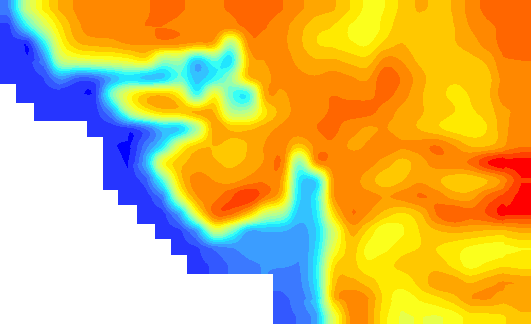
The question is; which one is closer to the "truth"...