- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- One to many join with cursors using dictionaries a...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
One to many join with cursors using dictionaries and lists - script is not inserting 'many joins' correctly
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am an enthusiastic dabbler in Python and I have (enthusiastically) attempted to write a script to create a one-to-many join to populate rows in the source table (Table1) from data in the join table (Table2).
(I have attached a diagram which explains this process)
The tables will have two ID values - one will have duplicates (ID1) and the other will be unique (ID2).
Table1 has unique IDs which will be duplicated after processing (ID1).
Table2 has two ID fields - there are duplicate ID1's and unique values for ID2.
I need to populate rows from table2 to table1.
The first match will populate the existing row in table1.
All subsequent matches to ID1 will be populated as new rows.
My script currently processes the one-to-many join successfully...but only when there is a maximum of 1 duplicate.
When there is more than 1 new row to insert, my script inserts all rows as duplicates of the 'final matched' row.
If there is anybody who can spot the error in my code or point me in the right direction, I would be really grateful as I have been stuck at this roadblock for a while now....
Thank you for taking the time to read about my troubles
Megan
import arcpy
arcpy.env.overwriteOutput = True
aprx = arcpy.mp.ArcGISProject(r'C:\sample_aprx.aprx')
m = aprx.listMaps("Map")[0]
# Source table to populate - contains unique ID1's and no ID2 data
table1 = r'C:\sample_aprx.gdb\table1'
table1_fields_update
table1_fields = ["ID1","ID2","FIELD1","FIELD2","FIELD3","FIELD4","FIELD5"]
# Source table - dictionary with unique keys for ID1
table1_dict = {r[0]: (r) for r in arcpy.da.SearchCursor(table1,table1_fields)}
# Join table - duplicate ID1's and unique ID2's
table2 = r'C:\sample_aprx.gdb\table2'
table2_fields = ["ID1","ID2","FIELD3","FIELD4","FIELD5"]
# Join table - dictionary with unique tuples (ID1, ID2) as keys
table2_dict = {(r[:2]): (r[2:]) for r in arcpy.da.SearchCursor(table2,table2_fields)}
# List to store rows that need to be inserted
InsertRows_list = []
with arcpy.da.UpdateCursor(table1, table1_fields) as UpdateCursor:
for row in UpdateCursor:
rowStatus = ""
# create list of table2 records that match to ID1 in table1
table2match_list = [(k, table2_dict[k]) for k in table2_dict if k[0] == row[0]]
for table2match in table2match_list:
# if "ID2" is already populated from table2, then mark this row as a new row to insert
if row[1] is not None:
rowStatus = "Insert"
# Assign data from table2 to table1
# updating fields: ID2, FIELD3, FIELD4, FIELD5
row[1], row[4], row[5], row[6] = table2match[0][1], table2match[1][0], table2match[1][1], table2match[1][2]
############# This part of the script doesn't work.
############# The result 'InsertRows_list' will append 'dupe' table rows to insert (it always dupes the 'last' matched row from table2match_list)
# Data that needs to be inserted as new rows is appended to a list, to be processed later
if rowStatus == "Insert"
InsertRows_list.append(row)
# If row has not already been populated, then update the existing row in table1
else:
UpdateCursor.updateRow(row)
# Insert all new rows
with arcpy.da.InsertCursor(table1, table1_fields) as InsertCursor:
for table2_row_data in InsertRows_list:
# Retrive the existing row in table1 that matches ID1
table1_row_data = table1_dict.get(row[0])
# New row is joined with data from table1 and table2
new_join_row = (table1_row_data[0],table2_row_data[1],table1_row_data[2],table1_row_data[3],table2_row_data[0],table2_row_data[1],table2_row_data[2])
InsertCursor.insertRow(new_join_row)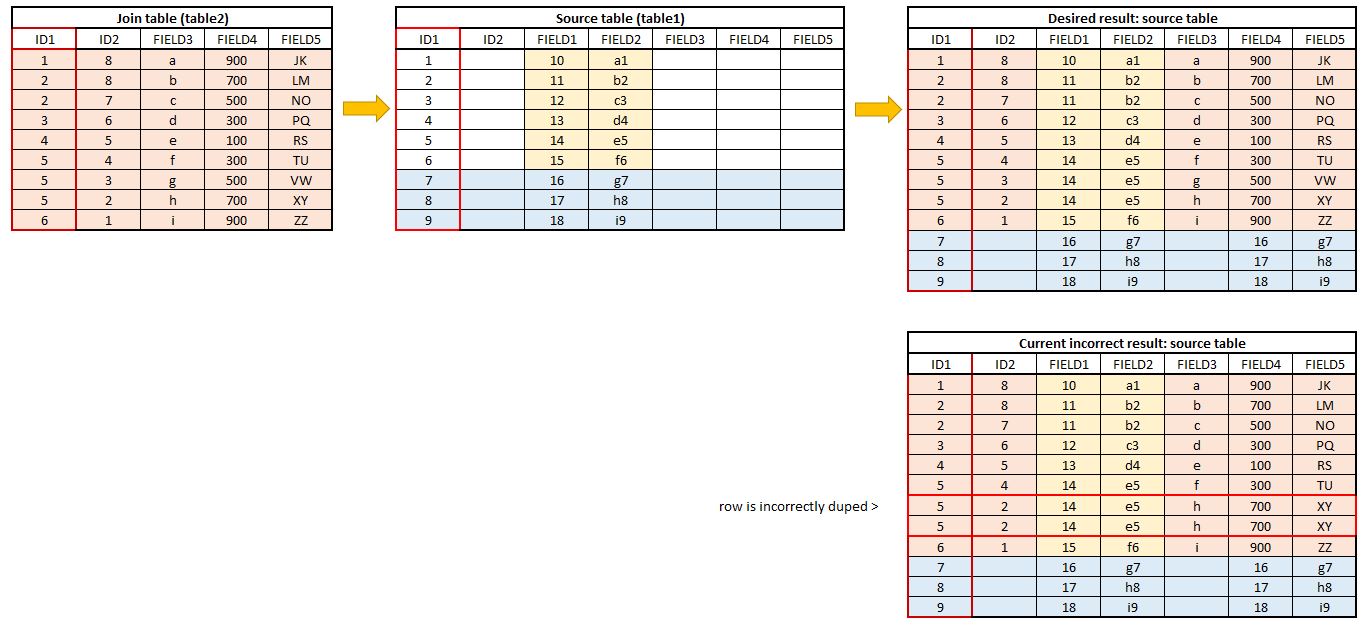{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Richard,
I've gone back and tested this, both dictionaries are working as expected with the list comprehension.
Looks like this: Dictionary = { (ID1, ID2) : (FIELD0, FIELD1, FIELD2 FIELD3 ....) }
ID1 & ID2 have successfully been assigned as dictionary keys as tuples so I think this part is working fine for handling the data.
The problem lies in the way I create the list of rows to insert. When I identify a row that needs to be inserted as a new row, I am trying to append this row to the new list so that I can insert as new rows separately with an Insert Cursor.
This is what my Insert Rows List looks like at the moment after it has been created in the code:
InsertRows_List = [ [matchrow1], [matchrow2], [matchrow5], [matchrow5], [matchrow5], [matchrow5], [matchrow5] ]
matchrow5 is incorrectly duplicated in the list - and as a result, when you run the Insert Cursor to iterate over this list, it will inevitably add these 5 duplicate rows.....maybe it is a looping problem I have having. Thanks for all the time you've spent so far on this, I'm very grateful.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You missed the point of my code. You have a dictionary with tuples, but only one tuple for only one record. You need a list of tuples, with the list containing a separate tuple for each record in table two. List comprehension only works for getting one of the records in a one to many key to record relationship, since each pass of a new record just replaces the last record. I know I am correct as I have written many scripts that do just this to handle one to many or many to many relationships. I have no real understanding of how your code creates the InsertRow, but I know that the list comprehension dictionary is the reason that only record 5 from FC2 is written to your insert record.
If 5 records in FC2 have the same key field values, the dictionary for FC2 needs to store this:
{ (ID1, ID2) : [(FIELD0, FIELD1, FIELD2 FIELD3 ....) ,(FIELD0, FIELD1, FIELD2 FIELD3 ....) ,(FIELD0, FIELD1, FIELD2 FIELD3 ....) ,(FIELD0, FIELD1, FIELD2 FIELD3 ....) ,(FIELD0, FIELD1, FIELD2 FIELD3 ....) ]}
The code I have suggested will store the 5 records of data from FC2 that all have the same key field values this way.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Normally if you don't want duplicates to appear in a list or other container, during a data collection process is to ensure that you don't add if it already exists or to remove the duplicates yet maintain order.
The python 'set' or in python 3.6, you can use dictionaries since they now retain their order (you need PRO for this)
Conceptually, these examples may get you thinking as to what you want to do when a case is met. The last example using 'toadd' to collect values, may be what you want to do
a = [6, 3, 2, 4, 3, 5, 4, 7, 9, 3] # ---- just some numbers like records in a table
set(a) # ---- set in python 3.6 gets rid of dups but sorts
{2, 3, 4, 5, 6, 7, 9}
toadd=[] # ---- lets store the results and collect as we go along
for i in a: # ---- your searchcursor... add only if a value isn't in it already
if i not in toadd:
toadd.append(i)
# ---- the big reveal... no duplicates, the order of visited preserved
toadd
[6, 3, 2, 4, 5, 7, 9]- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »