- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- One to many join with cursors using dictionaries a...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
One to many join with cursors using dictionaries and lists - script is not inserting 'many joins' correctly
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am an enthusiastic dabbler in Python and I have (enthusiastically) attempted to write a script to create a one-to-many join to populate rows in the source table (Table1) from data in the join table (Table2).
(I have attached a diagram which explains this process)
The tables will have two ID values - one will have duplicates (ID1) and the other will be unique (ID2).
Table1 has unique IDs which will be duplicated after processing (ID1).
Table2 has two ID fields - there are duplicate ID1's and unique values for ID2.
I need to populate rows from table2 to table1.
The first match will populate the existing row in table1.
All subsequent matches to ID1 will be populated as new rows.
My script currently processes the one-to-many join successfully...but only when there is a maximum of 1 duplicate.
When there is more than 1 new row to insert, my script inserts all rows as duplicates of the 'final matched' row.
If there is anybody who can spot the error in my code or point me in the right direction, I would be really grateful as I have been stuck at this roadblock for a while now....
Thank you for taking the time to read about my troubles
Megan
import arcpy
arcpy.env.overwriteOutput = True
aprx = arcpy.mp.ArcGISProject(r'C:\sample_aprx.aprx')
m = aprx.listMaps("Map")[0]
# Source table to populate - contains unique ID1's and no ID2 data
table1 = r'C:\sample_aprx.gdb\table1'
table1_fields_update
table1_fields = ["ID1","ID2","FIELD1","FIELD2","FIELD3","FIELD4","FIELD5"]
# Source table - dictionary with unique keys for ID1
table1_dict = {r[0]: (r) for r in arcpy.da.SearchCursor(table1,table1_fields)}
# Join table - duplicate ID1's and unique ID2's
table2 = r'C:\sample_aprx.gdb\table2'
table2_fields = ["ID1","ID2","FIELD3","FIELD4","FIELD5"]
# Join table - dictionary with unique tuples (ID1, ID2) as keys
table2_dict = {(r[:2]): (r[2:]) for r in arcpy.da.SearchCursor(table2,table2_fields)}
# List to store rows that need to be inserted
InsertRows_list = []
with arcpy.da.UpdateCursor(table1, table1_fields) as UpdateCursor:
for row in UpdateCursor:
rowStatus = ""
# create list of table2 records that match to ID1 in table1
table2match_list = [(k, table2_dict[k]) for k in table2_dict if k[0] == row[0]]
for table2match in table2match_list:
# if "ID2" is already populated from table2, then mark this row as a new row to insert
if row[1] is not None:
rowStatus = "Insert"
# Assign data from table2 to table1
# updating fields: ID2, FIELD3, FIELD4, FIELD5
row[1], row[4], row[5], row[6] = table2match[0][1], table2match[1][0], table2match[1][1], table2match[1][2]
############# This part of the script doesn't work.
############# The result 'InsertRows_list' will append 'dupe' table rows to insert (it always dupes the 'last' matched row from table2match_list)
# Data that needs to be inserted as new rows is appended to a list, to be processed later
if rowStatus == "Insert"
InsertRows_list.append(row)
# If row has not already been populated, then update the existing row in table1
else:
UpdateCursor.updateRow(row)
# Insert all new rows
with arcpy.da.InsertCursor(table1, table1_fields) as InsertCursor:
for table2_row_data in InsertRows_list:
# Retrive the existing row in table1 that matches ID1
table1_row_data = table1_dict.get(row[0])
# New row is joined with data from table1 and table2
new_join_row = (table1_row_data[0],table2_row_data[1],table1_row_data[2],table1_row_data[3],table2_row_data[0],table2_row_data[1],table2_row_data[2])
InsertCursor.insertRow(new_join_row)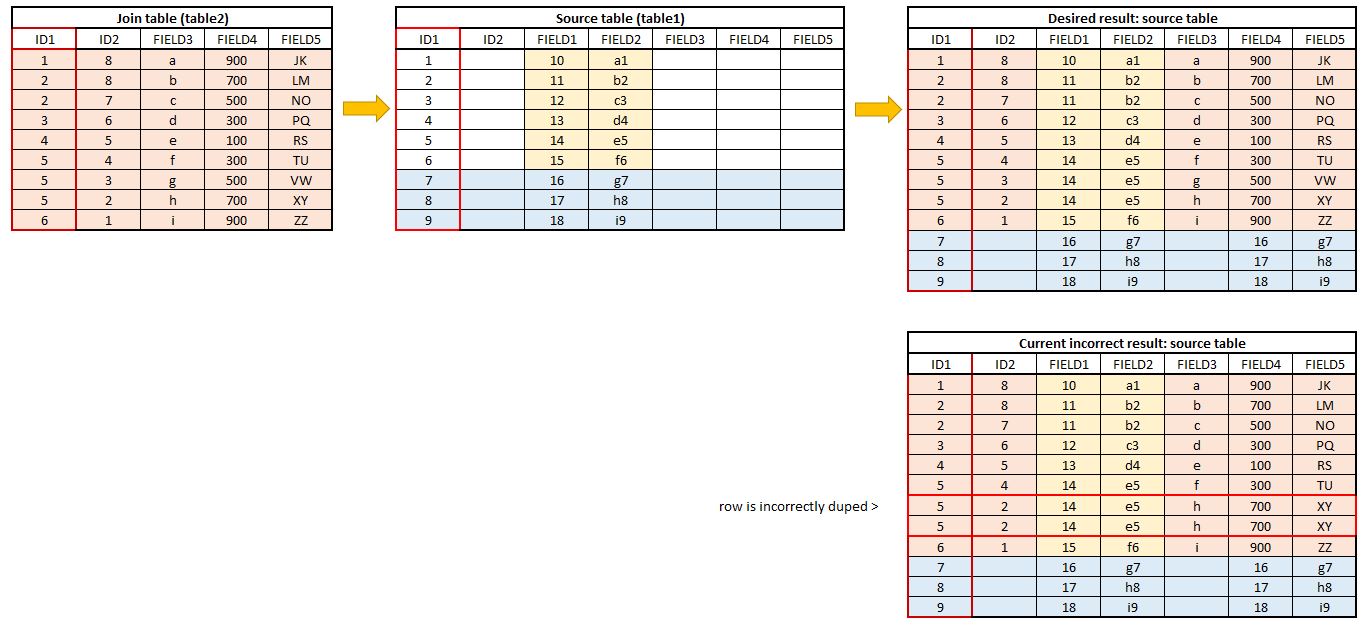{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am unsure of the purpose of your 'continue' statement on line 54. What is the result if you removing/comment it
In fact, if the only time you need to updatecursor is when update is the operative, I don't see the purpose of the lines 49-54 since the could be consolidated to appending to the list if 'update' and updating the cursor if 'insert'
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You are correct about the continue statement - it is redundant & provides same result and there is redundancy in code. Noted & updated.
The reason why I append to a new list separately before running the insert cursor is because I read that nesting a cursor inside another cursor doesn't work. I was facing this issue and then separating the processes solved this issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I do not follow all of what the code is doing, but I cannot find a declaration of the rowStatus variable prior to line 40. It seems that you always assign this variable on the first pass, but I would assign the rowStatus variable outside of your loop prior to line 32 to make sure that an unassigned variable error condition never occurs.
The rowStatus variable does not seem to get reset in the loop, so once it is set to "Insert" it stays that way. That should mean that every time lines 49 and 50 occur the condition is true, so every row should be treated as an Insert row and the variable is effectively doing the same thing every time. You probably need to add a new line of code after lines 49 and 50 to reinitialize rowStatus, i.e.,
if rowStatus == "Insert"
InsertRows_list.append(row)
rowStatus = ""- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Yes correct, this is needed...noted and updated. Thank you 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The code behavior should have changed with that code adjustment. Is it working now? If not, what is it now doing that you don't want or not doing that you want?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Apologies, I get that the code is a bit convoluted, I'm working on that.
Assigning the rowStatus value helps the code run successfully to the end without errors.
Without it, the code encountered an error and did not finish.
Here's another explanation (pseudocode), I hope this helps.
I want to insert rows:
row 1 = "some data 1 "
row 2 = "some data 2"
row 3 = "some data 3"
row 4 = "some data 4"
row 5 = "some data 5"
But the result I'm getting is :
row 1 = "some data 1"
row 2 = "some data 5"
row 3 = "some data 5"
row 4 = "some data 5"
row 5 = "some data 5"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You had better post new code...
Also, I just glanced at your second cursor and I noticed this
InsertCursor.insertRow(row_full)
and I can't find where row_full (I could be blind though, or it is a remnant variable)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Yes, thanks for spotting and sorry for careless mistakes in code...I'll edit this and keep checking for more.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You cannot use list comprehension to populate your second dictionary when you need to store a list of records and not just a single record. Something like the following may work, but then you need to walk through the list of tuples returned by the dictionary in your other code to make comparisons and to avoid duplication.
sourceFC = "MyFC"
sourceFieldsList = ["FIELD0","FIELD1","FIELD2","FIELD3"]
# Build a summary dictionary from a da SearchCursor with unique key values storing a list of records.
valueDict = {}
with arcpy.da.SearchCursor(sourceFC, sourceFieldsList) as searchRows:
for searchRow in searchRows:
keyValue = searchRow[0]
if not keyValue in valueDict:
# assign a new keyValue entry to the dictionary storing a record in a list
valueDict[keyValue] = [searchRow[1:]]
else:
# append a record to the list if the key already exists in the dictionary
valueDict[keyValue].append(searchRow[1:])