- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Looping through layer and running a report.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Looping through layer and running a report.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I created a report in ArcMap that I would like to use to export reports for my data as PDFs, the problem is that when I run the report for all my data, there is not enough memory to handle it. One way to fix it is to select each row one by one and run the report on only the selected features. This would take a long time thought as I have over a hundred reports that would be generated.
I am wondering if it is possible to run a python script to loop through my main data table, select the record, and then run my report on that selected feature, export that report to a PDF and then continue iterating through the other features in the same way.
This is what I have so far, but I am not sure how to call the report to run in my script. Any ideas?
import arcpy
from arcpy import da
import os
#input the tank layer
inTable = arcpy.GetParameterAsText(0)
#specify output location for reports
fileLocation = arcpy.GetParameterAsText(1)
#tanks is my main data layer
tanks=da.SearchCursor(inTable)
#loop through layer
for item in tanks:
#select feature
#run report
#export report to fileLocation
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
There's a couple of things that may limit you on what can be done...
Are you using python 3 or 2? How much memory does your machine have?
You might be able to do it using threading, if you are using 3.
To set that up, you need to create a separate 'worker' script, and save it in the same folder as the main script. These are from a project I did with some sudocode changes to fit your needs. It's untested but hopefully can give you an idea of how to go about it using multi-threading, or you can take the guts of the worker function and put that in your cursor's for loop so that it creates the layer, report, and exports it one at a time.
Esri's doc on reports: Report—ArcPy | Documentation
import os
import arcpy
from arcpy import env
#-------------------------------------------------------------------------------
def worker(id, pdfoutput):
"""
This is the function that gets called and does the work of creating the report.
"""
try:
whereClause = 'OBJECTID = {}'.format(id)
fc = 'Path to featureclass'
flyr = '{}_tmp'.format(id)
_rlfloc = r'C:\...\ArcGIS_Report_Templates\Report_SCRField_v6.rlf
report = arcpy.MakeFeatureLayer_management(fc, fLyr, whereClause)
#export report to fileLocation
arcpy.mapping.ExportReport(report, _rlfloc, pdfoutput)
- or something like using exporttopdf if you can set the reports definition-
except:
# Some error occurred so return False
msg = "Error occurred while doing stuff: {}.format(arcpy.GetMessage(2))
_ret = (False, msg)
return _retThen in the main script:
# Environment Setup
import os, sys
import arcpy
import multiprocessing
from multicode import worker Change 'multicode' to the name of the other pyhton file.
fom arcpy import env
env.overwriteOutput = True
#-------------------------------------------------------------------------------
# Support functions
def get_install_path():
"""
Returns the x64 python interpreter if installed
"""
# We're running in a 64bit process
if sys.maxsize > 2**32:
return sys.exec_prefix
# We're 32 bit so see if there's a 64bit install
path = r'SOFTWARE\Python\PythonCore\2.7'
from winreg import OpenKey, QueryValue
from winreg import HKEY_LOCAL_MACHINE, KEY_READ, KEY_WOW64_64KEY
try:
with OpenKey(HKEY_LOCAL_MACHINE, path, 0, KEY_READ | KEY_WOW64_64KEY) as key:
# We have a 64bit install, so return that.
return QueryValue(key, "InstallPath").strip(os.sep)
# No 64bit, so return 32bit path
except:
return sys.exec_prefix
#-------------------------------------------------------------------------------
def createtasklist(fc):
"""
Returns a list that contains items needed for the worker function for each report
"""
# Tuples consist of the data, pdfoutput values.
jobs = []
with da.SearchCursor(fc, [flds] as cur:
for row in cur:
OBJECTID = row[0]
# set the output path of the pdf using the oid (and any other field value maybe)to make it unique
pdfoutput = 'output pdf path_{}.pdf'.format(row[0])
jobs.append((row[0], pdfoutput))
return jobs
#-------------------------------------------------------------------------------
def createpool():
"""
Sets the multiprocessing environment and returns the number of cores.
"""
multiprocessing.set_executable(os.path.join(get_install_path(), 'pythonw.exe'))
cpuNum = multiprocessing.cpu_count()
arcpy.AddMessage("\tThere are {} cpu cores on this machine".format(str(cpuNum)), 'Message')
return cpuNum
#-------------------------------------------------------------------------------
def processworkerresults(result):
"""
Interprets the results from the processing pool and displays any errors to the user
"""
# Get results of the pool and display any error messages.
failed = 0
for _stat, _msg in result:
if _stat == False:
failed += 1
arcpy.AddMessage('{}! msg: {}'.format(_stat, _msg))
# If there were any failures, display how many there were.
if failed > 0:
arcpy.AddMessage("{} workers failed!".format(str(failed))
def mainprocess(jobs, cpuNum):
"""
Starts the processing pool using the worker module and returns a list of results.
"""
with multiprocessing.Pool(processes=cpuNum) as pool:
# run jobs in job list; result is a list with return values of the worker function
result = pool.starmap(worker, jobs)
return result
#-------------------------------------------------------------------------------
def multiprocesshandler():
"""
Script controller
"""
try:
# Create a list of object IDs for clipper polygons
field, idList = createOIDlist()
# Process the number of cores, create jobs and return the the results of processing the featureclasses.
result = mainprocess(jobs=createtasklist(fc), cpuNum=createpool())
# Process the results and display any errors and total failures
processworkerresults(result)
except arcpy.ExecuteError:
# Get any errors from geoprocessing session
msg = '{}\n{}'.format(arcpy.GetMessages(2), arcpy.ExecuteError)
arcpy.AddMessage(msg)
# Capture all other errors
except Exception as e:
print(str(e))
#-------------------------------------------------------------------------------
if __name__ == '__main__':
multiprocesshandler()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
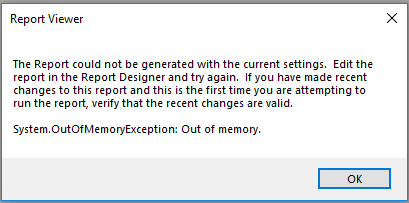
Thank you! This helped me understand what I needed to do. So I got the loop to generate reports working, but I get a System.OutOfMemoryException: Out of Memory error for some of the reports I am trying to run. My layer does have a lot of photos in it, but I thought splitting it up with this loop would help out more. I got about half my reports to run, so not bad. But does anyone know how to fix this memory issue?
#import the libraries you need
import arcpy
from arcpy import da
import os
#you tell it which layer you want to search through and which field(s) you want
fields=["OBJECTID", "Name"] #field list since I wanted more than one
tanks=da.SearchCursor("Storage", fields) #cursor
#using the cursor you established, you can loop through and do stuff
with tanks as cursor:
for item in cursor:
try:
#identify the map document
mxd = arcpy.mapping.MapDocument(r'MYPATH.mxd')
df = arcpy.mapping.ListDataFrames(mxd)[0]
#which layer you need to loop over
lyr = arcpy.mapping.ListLayers(mxd, "Storage", df)[0]
#create the pdf filename by using the Name field in Storage
filename="\\"+str(item[1])+".pdf"
#create the path for the pdf to be saved in
path=r'OUTFOLDERPATH' + filename
#this is where we search through the table to make our selections to run the report on
#I get the first value (the OBJECTID) from the cursor list
value=item[0]
#I identify that I will be searching using OBJECTID
field="OBJECTID"
#create an expression to use to select the record I want in this iteration
#it checks that "OBJECTID" is = whatever value we are on in the cursor list
exp=str(field) + "=" +str(value)
#now I make my selection from the lyr object, it uses the expression from above
point_lyr=arcpy.SelectLayerByAttribute_management(lyr,"NEW_SELECTION",exp)
#now I can run the report on the lyr, specify the report template, give it the output path, and tell it to run on the selected items only
arcpy.mapping.ExportReport(lyr, r'REPORTPATH.rlf', path, "SELECTED")
except: #i do this because i get storage errors
continueError from report viewer:
Error from Python:
Runtime error
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "c:\program files (x86)\arcgis\desktop10.7\arcpy\arcpy\utils.py", line 182, in fn_
return fn(*args, **kw)
File "c:\program files (x86)\arcgis\desktop10.7\arcpy\arcpy\mapping.py", line 532, in ExportReport
return report_source._arc_object.ExportReport(*gp_fixargs((report_layout_file, output_file, dataset_option, report_title, starting_page_number, page_range, report_definition_query, extent, field_map), True))
RuntimeError: Error in generating report- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Might be a limitation of the 32-bit architecture. Do you have background processing installed/available? I don't know if it would help, but might be an option.