- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Is it possible to use a Group By function in t...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Is it possible to use a Group By function in the arcpy Update cursor?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Is it possible to use a Group By function in the arcpy Update cursor?
I was playing around with the update cursor today but could not get the Group By function to work within it.
For each group of records in my dataset I need to perform a field calculation based on an existing field.
I can set up this calculation with no problem in the cursor.
Technically speaking, the calculation will only be accurate when the records are
grouped.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Since I mentioned 9.7. itertools — Functions creating iterators for efficient looping — Python 2.7.13 documentation , and it can be used in this case, I thought I would share an example:
from itertools import cycle, groupby
tbl = # path to sorted table
fields = ["Field1","Field2","Field3","NewID","GuyIndex","Value"]
with arcpy.da.UpdateCursor(tbl,fields) as cur:
for k,g in groupby(cur, key=lambda x: x[3]):
ctr = cycle(range(3))
for row in g:
i = next(ctr)
cur.updateRow(row[:4] + [i, row[i]])The above assumes there are no more than 3 records per NewID. If there are, the code will have to be updated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Do you mean SQL GROUP BY or itertools.groupby ?
The more information you can share about your data structure and results you are after, the more specific and useful the feedback.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
GROUP BY doesn't make much sense within the context of an UPDATE. It's also not clear from your question whether this is a modern Data Access UpdateCursor or the deprecated kind, what version of ArcGIS is in use, and whether your data is file geodatabase, non-geodatabase (shapefile or other) or RDBMS.
- V
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for the responses.
I am using ArcGIS 10.3 and I am using a file geodatabase.
Below I have included the script I am working on with some notes on the data structure and results I wish to obtain. I have just left out the file paths below.
"""
This script attributes the relevant value from one of three fields (Field1, Field2, Field3) to the 'Value' field.
If the GuyIndex value is 0 then the 'Value' should be equal to Field1.
If the GuyIndex value is 1 then the 'Value' should be equal to Field2.
If the GuyIndex value is 2 then the 'Value' should be equal to Field3.
Note: The above process should be performed on unique sets of values from the 'NewID field'
I am not sure how to implement this.
I was hoping I could Group By based on the 'NewID' field using the Update Cursor. However I cannot get this to work.
"""
"""
Sort POINT_X by Ascending method.
This will allow me to assign the index values based on ascending POINT_X values.
"""
Sorted = arcpy.Sort_management(Shapefile,"Sorted","POINT_X ASCENDING","UR")
"""
Add a new field "GuyIndex" to be populated in the update cursor
"""
arcpy.AddField_management(Sorted,"GuyIndex","SHORT","","","","","NULLABLE","NON_REQUIRED","")
"""
Specifying fields to be used in the update cursor.
"""
CursorFields = ['GuyIndex','Value','Field1','Field2','Field3']
"""
Add the Index attribute to assign an ascending attribute to the records.
Because the dataset was sorted already '0' will be assigned to the 1st record in the table (smallest Point_X value),
1 being assigned to the second record in the table and so on.
Note: Ultimately I want to perform this on each group of 'NewID's. (not included below)
"""
i = 0
cur = arcpy.UpdateCursor(Sorted, CursorFields)
for row in cur:
row.GuyIndex = i
i += 1
if row.getValue(CursorFields[0]) == 0:
row.Value = row.getValue(CursorFields[2])
elif row.getValue(CursorFields[0]) == 1:
row.Value = row.getValue(CursorFields[3])
elif row.getValue(CursorFields[0]) == 2:
row.Value = row.getValue(CursorFields[4])
cur.updateRow(row)
del row, cur
print "Complete"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
First of all when posting code on GeoNet please use the steps as described in Posting code with Syntax Highlighting on GeoNet or see this blog /blogs/dan_patterson/2016/08/14/script-formatting written by Dan Patterson. Your code became invalid since there are no indentations where they should be.
From what I understand you have the GuyIndex start from 0 and increment with each feature. If you have more than 3 features in your featureclass the value field will not be populated for those features.
Also the grouping part of you case is not completely clear to me. Can you make it visible in some way in order to understand it?
Als noticed that you are using the old and slow arcpy.UpdateCursor. It is recommended to use the UpdateCursor—Help | ArcGIS Desktop instead.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Many thanks for your tip regarding properly adding code to the forum.
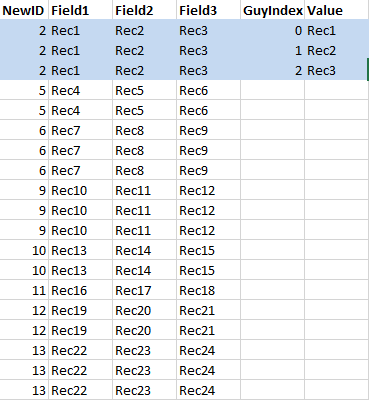
Please see below a subset of the data that I am working with.
I want my code to take a group of features as shown in the highlighted selection below and assign the 'GuyIndex' and 'Value' attributes. Then I want to move on to the next group of features (e.g. 'NewID' = 5) and do the same task for this group of records.
I hope this clarifies what my intended outcome is.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I think you could probably use something like this (I haven't tested it out).
def main():
import arcpy
fc = r'path to your input featureclass'
fc_sorted = r'path to your output sorted featureclass'
fld_index = 'GuyIndex'
fld_value = 'Value'
fld1 = 'Field1'
fld2 = 'Field2'
fld3 = 'Field3'
fld_id = 'NewID'
arcpy.Sort_management(fc, fc_sorted, "POINT_X ASCENDING","UR")
arcpy.AddField_management(fc_sorted, fld_index, "SHORT")
flds = (fld_id, fld_index, fld_value, fld1, fld2, fld3)
i = 0
prev_new_id = -1
cnt_item = 0
with arcpy.da.UpdateCursor(fc_sorted, flds) as curs:
for row in curs:
new_id = row[0]
row[1] = i
if new_id == prev_new_id:
# same group
cnt_item += 1
if cnt_item > 3:
# in case there are more than 3 elements in a group, start over
cnt_item = 1
row[2] = row[cnt_item + 2]
else:
# new group
cnt_item = 1
row[2] = row[cnt_item + 2]
curs.updateRow(row)
prev_new_id = new_id
i += 1
if __name__ == '__main__':
main()It you want me to test it, please share a sample of your data.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Since I mentioned 9.7. itertools — Functions creating iterators for efficient looping — Python 2.7.13 documentation , and it can be used in this case, I thought I would share an example:
from itertools import cycle, groupby
tbl = # path to sorted table
fields = ["Field1","Field2","Field3","NewID","GuyIndex","Value"]
with arcpy.da.UpdateCursor(tbl,fields) as cur:
for k,g in groupby(cur, key=lambda x: x[3]):
ctr = cycle(range(3))
for row in g:
i = next(ctr)
cur.updateRow(row[:4] + [i, row[i]])The above assumes there are no more than 3 records per NewID. If there are, the code will have to be updated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Can you continue on with your expected outcome for the GuyIndex and Value fields, since there are a couple of possibilities. You have in your example, 19 rows, but 21 unique values. do you allow new rows to be added? or must you truncate based on a unique count of row values.
As a side note... you should also be careful about using variables that concatenate strings and numbers..
vals = ['r1', 'r2', 'r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9', 'r10', 'r11', 'r12']
vals.sort()
['r1', 'r10', 'r11', 'r12', 'r2', 'r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9']
# ---- ooops we need a 'natural sort', ----
def natsort(lst):
"""natural sort... google it"""
import re
convert = lambda text: int(text) if text.isdigit() else text
a_key = lambda key: [convert(c) for c in re.split('([0-9]+)', key)]
return sorted(lst, key=a_key)
vals = ['r1', 'r2', 'r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9', 'r10', 'r11', 'r12']
natsort(vals)
['r1', 'r2', 'r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9', 'r10', 'r11', 'r12']
# ---- better ----
A little padding goes a long way to simplify your work .... r01, r02,... r10...
ADDENDUM
Now, if you have to fix fields...preferably by creating new ones, and repurposing old data... you can fix the errant values and pad them so that they will automatically sort.
def nat_pad(val, pad='0000'):
"""natural sort... put the import re outside of the function
:if using the field calculator
: calculator expression- nat_pad(!data_field!, pad='a bunch of 0s')
"""
import re
txt = re.split('([0-9]+)', val)
l_val = len(str(val))
txt_out = "{}{}{}".format(txt[0], pad[:-l_val], txt[1])
return txt_out
# ---- this can be used in a new field to reclassifiy inputs so that
# natural sorting is supported without additional effort ------
c = ['r1', 'r1', 'r1', 'r4', 'r4', 'r7', 'r7', 'r7', 'r10', 'r10']
[nat_pad(i) for i in c]
['r001', 'r001', 'r001', 'r004', 'r004', 'r007', 'r007', 'r007', 'r010', 'r010']