- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: In this example, how do I write a Python scrip...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
In this example, how do I write a Python script to accomplish this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
In this example, how do I write a Python script to accomplish this result:
Site ID
SIte A 0001
Site A 0001
SIte A 0001
Site A 0001
Site B 0002
SIte B 0002
Site B 0002
Site C 0003
SIte D 0004
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Yes, I did, and got something like this:
| FIELD | NEED TO BE |
| xxx_ 9999TUNK10_ | xxx_ 9999TUNK10_001 |
| xxx_ 9999TUNK10_ | xxx_ 9999TUNK10_002 |
| xxx_ 9999TUNK10_ | xxx_ 9999TUNK10_003 |
| xxx_ 9999BANK12_ | xxx_ 9999BANK12_002 |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
# lines 7... change to
cnt += 0 # ---- try changing this
ret = "{} {:04.0f}".format(val, cnt)
else:
cnt += 1 # ---- and this
ret = "{} {:04.0f}".format(val, cnt)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I got an error: 999999 : Error executing function.
999999 : Error executing function.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
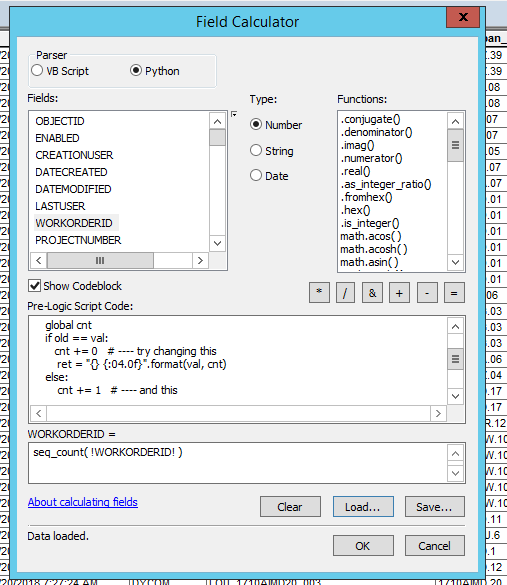
show your field calculator dialog with the function and your expression filled in
Any of you other peeps want to leap in... lots of viewers... no suggestions from the gallery??? You can take over if you want
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Peeping in.....
A dictionary solution could look like something like this:
data = ['xxx_9999TUNK10_',
'xxx_9999TUNK10_',
'xxx_9999TUNK10_',
'xxx_9999BANK12_',
'xxx_9999BANK17_',
'xxx_9999BANK1_',
'xxx_9999BANK20_',
'xxx_9999BANK20_',
'xxx_9999BANK20_',
'xxx_9999BANK30_' ]
d = {}
cnt = 0
for row in data:
if row not in d.keys():
cnt += 1
d[row] = cnt
print "{}{:04.0f}".format(row, cnt)
else:
print "{}{:04.0f}".format(row, d[row])
'''
Results:
xxx_9999TUNK10_0001
xxx_9999TUNK10_0001
xxx_9999TUNK10_0001
xxx_9999BANK12_0002
xxx_9999BANK17_0003
xxx_9999BANK1_0004
xxx_9999BANK20_0005
xxx_9999BANK20_0005
xxx_9999BANK20_0005
xxx_9999BANK30_0006
'''Is the prefixed 'xxx_' always the same, or does it vary? If it varies, you will need to do some string splitting, etc.
Is the postfixed '_' always present? If not, the formatting statement can be modified to include it.
By making the dictionary 'd' and the counter 'cnt' global, you should be able to make it work for the field calculator. The code should also work with an update cursor, should you wish to go that route.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Prefix is always the same and suffix is always present and varies. Could I
substitute the data portion with the field name?
Charles Banks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Not sure I understand your question. Would something like this do what you want?
data = ['xxx_9999TUNK10_',
'xxx_9999TUNK10_',
'xxx_9999TUNK10_',
'xxx_9999BANK12_',
'xxx_9999BANK17_',
'xxx_9999BANK1_',
'xxx_9999BANK20_',
'xxx_9999BANK20_',
'xxx_9999BANK20_',
'xxx_9999BANK30_' ]
d = {} # empty dictionary
cnt = 0 # counter
def seq_count(fname, val):
global d
global cnt
if val not in d.keys():
cnt += 1
d[val] = cnt
return "{}_{}{:04.0f}".format(fname, val, cnt)
else:
return "{}_{}{:04.0f}".format(fname, val, d[val])
fieldName = 'myField'
for item in data:
print seq_count(fieldName, item)
'''
Results:
myField_xxx_9999TUNK10_0001
myField_xxx_9999TUNK10_0001
myField_xxx_9999TUNK10_0001
myField_xxx_9999BANK12_0002
myField_xxx_9999BANK17_0003
myField_xxx_9999BANK1_0004
myField_xxx_9999BANK20_0005
myField_xxx_9999BANK20_0005
myField_xxx_9999BANK20_0005
myField_xxx_9999BANK30_0006
'''- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Yes.
Charles Banks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Sorry about the delay. Here it is:
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »