- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Import CSV
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a loaded processing question and looking for some ideas...below is what I need to do...
I am importing a CSV file which ultimately will be a feature class. So if we start with the END result (Feature class) and I am looking to import a CSV file the question arises.....Can I append a CSV File to a Feature Class....I say no because there is no geometry in the CSV file other than Lat Long...SO that would bring us full circle (Assuming that the Master Feature Class already exists) to the beginning where I would have create a Staging feature class from the CSV and then append into the Master Feature Class housing all the records.
Proposed Steps:
- Delete Staging Feature Class (Used to import the CSV file)
- Import CSV file to stand alone table
- Create Event Layer via Lat Long Fields in CSV File
- Export to Feature Class (This is the Staging layer mentioned above)
- Do some field processing to new Feature Class
- Append to Master Feature Class
Any other thoughts...did that make sense?
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
OK this is the FINAL SCRIPT... I cant thank you all enough for you help...
- Reads through a Folder looking for CSV or txt files
- Reads through each CSV file
- Splits the comma delinted CSV file and write all the vales to variables
- A couple functions are called to process a couple of the variables to create new values for calculated fields that exist in the Feature Class but NOT the CSV file
- An if than statement populates a new field BearID based on a value from another field and adds this to the insert.
- Each row is inserted into the Feature Class
- Once completed the txt/csv files are moved to another folder for backup
import arcpy
import datetime
import os, fnmatch
import shutil
# Function to modify two fields into a Time variable
def getdate(Hour, Minute):
return datetime.datetime.strptime(str(Hour).zfill(2) + ' ' + str(Minute).zfill(2), '%H %M')
#Function to loop through a directory and work through one file at a time
def findFiles (path, filter):
for root, dirs, files in os.walk(path):
for file in fnmatch.filter(files, filter):
yield os.path.join(root, file)
fc = r'C:\Users\tjv36463\Desktop\BearCollar\BearLocationImports.gdb\BearCollar'
#Insert cursor for the Bikes feature class
cursor = arcpy.da.InsertCursor (fc,["CollarSeri", "Year", "Julianday", "Hour", "Minute",
"Activity", "Temperatur", "Latitude", "Longitude", "HDOP", "NumSats", "FixTime",
"Date", "_2D_3D", "BearID", "CalcDate", "CalcDate3", "FileName", "SHAPE@XY"])
#Read through each line of the csv, but skip the first row because it is the header
#The count variable skips of the first row
for textFile in findFiles(r'C:/Users/tjv36463/Desktop/BearCollar/NewFiles/', '*.txt'):
#Read through each line of the csv, but skip the first row because it is the header
#The count variable skips of the first row
count = 0
for ln in open (textFile, 'r').readlines():
if count > 0:
#Each line in the csv is a string, so turn it into a list so you can reference
#each column
lineSplit = ln.split(",")
#Use index positions to get the right column from the csv
#Make sure the data is the correct type (i.e. X and Y need to be numbers,
#not strings)
CollarSeri = long(lineSplit[0])
Year = str(lineSplit[1])
Julianday = str(lineSplit[2])
Hour = int(lineSplit[3])
Minute = int(lineSplit[4])
Activity = int(lineSplit[5])
Temperature = int(lineSplit[6])
Latitude = float(lineSplit[7])
Longitude = float(lineSplit[8])
HDOP = str(lineSplit[9])
NumSats = int(lineSplit[10])
FixTime = int(lineSplit[11])
_2D_3D = int(lineSplit[12])
Date = str(lineSplit[13])
# convert the two time fields into one field to get 4:02:00PM format
# calls Function getDate at the top
getTime = getdate(Hour, Minute)
getTime2 = str(getTime)
getTime3 = getTime2[-8:]
# concatonate Date and Time to get 6/15/2016 4:02:00PM
getDateTime = (Date + getTime3)
# set variable for the File Name in which the record was take from
FileName = str(textFile)
#print (FileName)
if CollarSeri == 32488:
BearID = "1"
else:
if CollarSeri == 32491:
BearID = "2"
else:
if CollarSeri == 32495:
BearID = "3"
else:
if CollarSeri == 32498:
BearID = "4"
else:
if CollarSeri == 32500:
BearID = "5"
else:
if CollarSeri == 32502:
BearID = "6"
else:
if CollarSeri == 32501:
BearID = "7"
else:
if CollarSeri == 33108:
BearID = "8"
else:
if CollarSeri == 32499:
BearID = "9"
else:
if CollarSeri == 32488:
BearID = "10"
else:
if CollarSeri == 32496:
BearID = "11"
else:
BearID = "0"
shapeVal = (Longitude, Latitude)
#Insert the values from csv into feature class
#The order of the fields here, matches the order of the fields in line 4
cursor.insertRow ([CollarSeri, Year, Julianday, Hour, Minute, Activity,
Temperature, Latitude, Longitude, HDOP, NumSats, FixTime, Date,
_2D_3D, BearID, getTime3, getDateTime, FileName, shapeVal])
count += 1
del cursor
## make sure that these directories exist
# move the files to new location to clear the folder for the next batch of files
dir_src = "C:\\users\\tjv36463\\Desktop\\BearCollar\\NewFiles\\"
dir_dst = "C:\\users\\tjv36463\\Desktop\\BearCollar\\MovedFiles\\"
for file in os.listdir(dir_src):
#print file # testing
src_file = os.path.join(dir_src, file)
dst_file = os.path.join(dir_dst, file)
shutil.move(src_file, dst_file)
print ("Processing Finished")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Create and Event Layer, then save the results.
Personally, I've never had luck using the Append tool with python. The field mappings are too confusing for me. 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
A trick I use for using append and other gp tools in python is to run it as a tool on the layer with your field mappings set and then in the geoprocessing results right click and "copy as python snippet" and paste it into my python code. I do this with most tools that have complicated inputs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You can do virtually anything using python / arcpy 
So, if you want to go directly from your input csv and append the records into an existing fc, that is no problem.
But your step outlined, are basically what you would do manually using a series of steps (or build a model).
No problem with either approach.
Is your target fc in the same coordinate system as the coordinates in the csv?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I would recommend looking into using a Data Access module InsertCursor. You can read through the lines of your CSV and insert them into an existing feature class. Since you have the latitude and longitude in the CSV, you can enter in the geometry using the SHAPE@XY token.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This may get you started...
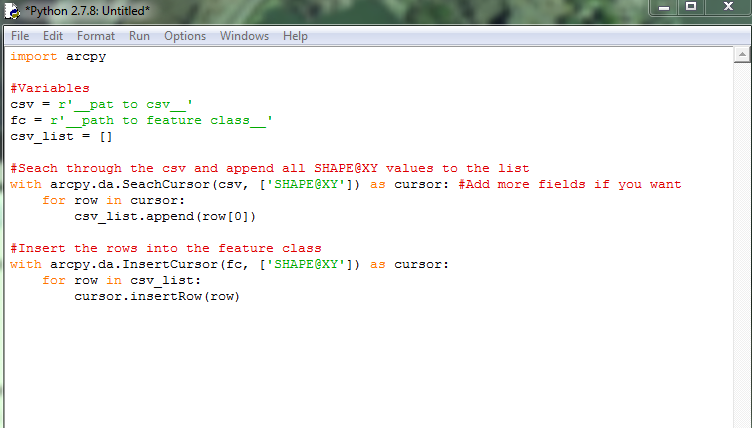
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
How does it know what fields my XY Coordinates are in?
Add fields like this?
#search
....snip (csv, ['SHAPEXY'], [date], [field1], [field2]) as cursor: ...snip
# Insert
....snip (fc, ['SHAPEXY'], [date], [field1], [field2]) as cursor: ...snip
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Jay,
Don't forget the '@' in the SHAPE@XY. Please format it like this:
... (csv, ["SHAPE@XY", "Date", "Field_1", "Field_2"]) as cursor
Each field is exasperated by quotations, not brackets.
ArcPy reads the geometries stored in the feature without them being an actual attribute.
Please read Brittany White's response above for a more in depth look into the InserCursor function and the SHAPE@XY token.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a CSV file I dont think I can use SHAPE@XY. DO I use the two XY FIelds somehow in the script?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If I understand your end goal correctly, you should be able to use Python to:
1. Read through each row in your csv
2. Insert each row from your csv into your feature class
The way you will write your geometry is using the SHAPE@XY token. Looking at the InsertCursor documentation, the SHAPE@XY expects "a tuple of the feature's centroid x,y coordinates". Your csv has an X field and Y field, so you can use that to create the tuple that will be passed to the cursor.
Here is an example of reading through the lines of a csv that has a header row of "X,Y,ADDRESS,TERMINAL_NUMBER,NUMBER_OF_BIKES":
import arcpy
#Insert cursor for the Bikes feature class
cursor = arcpy.da.InsertCursor ("bikes",["X", "Y","Address","SHAPE@XY"])
#Read through each line of the csv, but skip the first row because it is the header
#The count variable skips of the first row
count =0
for ln in open (r"C:\Path\To\File.csv", 'r').readlines():
if count > 0:
#Each line in the csv is a string, so turn it into a list so you can reference each column
lineSplit = ln.split (",")
#Use index positions to get the right column from the csv
#Make sure the data is the correct type (i.e. X and Y need to be numbers, not strings)
xVal = float(lineSplit[0])
yVal = float(lineSplit[1])
addVal = lineSplit[2]
shapeVal = (xVal, yVal)
#Insert the values from csv into feature class
#The order of the fields here, matches the order of the fields in line 4
cursor.insertRow([xVal, yVal, addVal, shapeVal])
count += 1
del cursor