- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- delete duplicates records based on field
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
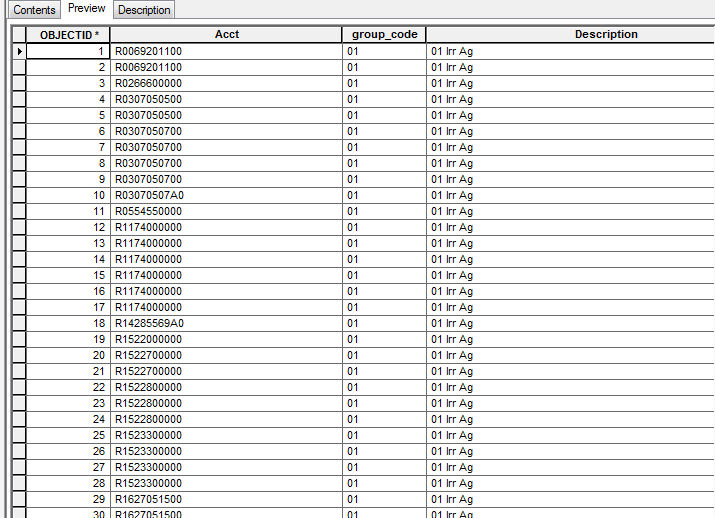
I need to be able to delete duplicate records but keep one only if it has a certain attribute in a certain field in a table. so i need to keep one of each "Acct" row but only if it has "01" in the Group _code. I need to be able to do this in arcpy python because i get this table weekly so i would like to schedule this task. Attached is a pic of the table i am working with.
I think i can iterate the "group_code" field and append the value and "Acct" to a dictionary.
I have the following but i am not sure how to select and remove duplicates. I would appreciate some help with some code.
import arcpy
from arcpy import env
env.overwriteOutput = 1
env.workspace = r"C:\GIS\LandValue.gdb"
fc = "LandValue3"
dict = {}
with arcpy.da.SearchCursor(fc, ["Acct", "group_code"]) as cursor:
for row in cursor:
dict[row[0]] = row[1]
del cursorSolved! Go to Solution.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I wasn't referring to a specific bug but supposing that one exists. You can look over the ArcGIS 10.4 Issues Addressed List and ArcGIS 10.4.1 Issues Addressed List, but I didn't see anything on those lists that jumped out at me. That said, not every bug that gets addressed is listed in those documents. It might be worth contacting Esri Support to see if they can track down a known bug and tell you what release it was addressed.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
It was my pc, i restarted my pc and recreated the file geodatabase and ran the script and it did what it was suppose to do.
Sorry about that and thanks for the help!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I built a similar tool that deletes duplicate geometries. It looks a little like this:
#Variables
feature = r'...path to feature...'
field = "field"
field_set = set()
count = 0
with arcpy.da.UpdateCursor(feature, [field]) as cursor:
for row in cursor:
if row[0] not in field_set:
field_set.add(row[0])
else:
count+=1
cursor.deleteRow()
arcpy.AddMessage('\n'+str(count) + ' duplicates removed from the ' + str(field) + ' field.\n')I haven't tested it on a field duplicate, only the 'SHAPE@XY' token. But, I successfully got it to work with the geometries.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks to both of you Joshua and Mitch for sharing some code it does delete the duplicates but i need it to only keep one of the Acct with 01 in the group_code field and the highest value in the value filed. unless i am not seeing something in your code...?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
#Variables feature = r'...path to feature...' field = "field" field_set = set() count = 0 with arcpy.da.UpdateCursor(feature, ['ACCT','group_code']) as cursor: for row in cursor: if row[0] not in field_set: if str(row[1]) != "01": field_set.add(row[0]) else: count+=1 cursor.deleteRow() arcpy.AddMessage('\n'+str(count) + ' duplicates removed from the ' + str(field) + ' field.\n')
This script will delete a duplicated record of the 'ACCT' field, ONLY WHERE 'group_code' does not equal "01".
Is this what you're looking to do? Also, I'm not sure about the highest value thing... that's tricky.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Partly yes, thank you for post
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »