- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- da.InsertCursor and Parsing Large Text file
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
da.InsertCursor and Parsing Large Text file
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have a very large text file (~5 GB, ~30 million lines) that I need to parse and then output some of the data to a new point feature class. I cannot figure out how to proceed with the da.InsertCursor.
I've created the feature class so the fields are in the required order. There is an if statement that parses out the required lines of the file. The units in the text file are Feet, however I need rounded Metres in the output and the output field for that information must be Long. The round command returns float but my final value in the Tree_Height output must be long - can the float value be mapped into the long field? Converting from Feet to Metres is simple multiplication, but I believe my field types might be messed up then?
The index positions of the Lat and Long fields in the source file are 5 and 6.
The index position of the Description field in the source file is 1.
The index position of the Tree_Height (in Feet) in the source file is 9.
The index position of the Code in the source file is 2 - this is the link between the user-inputted codes and the codes in the if statement. The if statement works, but after that....
Can someone help me set up the da.InsertCursor so that these operations can (a) get done and (b) get done efficiently? I've been fumbling with lists of fields and tuples of things and am not making any progress. Have looked at help files and Penn State's online courses but still no joy.....
import arcpy, os
treesfile = arcpy.GetParameterAsText(0)
codes = arcpy.GetParameterAsText(1).split(",") # user types in comma-delimited wildlife codes for the AOI
arcpy.env.workspace = arcpy.GetParameterAsText(2)
sr = arcpy.SpatialReference(4326)
arcpy.env.overwriteOutput = True
Filtered_Trees = arcpy.CreateFeatureclass_management(arcpy.env.workspace, "Filtered_Trees", "POINT", "", "DISABLED", "DISABLED", sr)
arcpy.AddField_management(Filtered_Trees, "Lat", "DOUBLE", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
arcpy.AddField_management(Filtered_Trees, "Long", "DOUBLE", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
arcpy.AddField_management(Filtered_Trees, "Description", "TEXT", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
arcpy.AddField_management(Filtered_Trees, "Tree_Height", "LONG", "", "", "", "", "NULLABLE", "NON_REQUIRED", "") # height value must be rounded and in Metres.
# there are many more fields but you get the idea
with open(treesfile, 'r') as file:
for line in file:
values = line.split("\t")
if values[2] in codes and float(values[9]) >= 100:
# now I am stuck... - Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
It is difficult to provide a specific suggestion because you haven't shared complete structure information of the data file and your code snippet states, "there are many more field but you get the idea." Are you transferring all the columns/fields from the CSV into the feature class when you insert a record of just some of the fields? The insert cursor requires that the length of the row you are inserting matches the number of fields you define in the cursor, so knowing which fields are being inserted is important.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Ah, yes I guess the casual-ness doesn't lend itself to getting the full picture across, sorry about that. I didn't want to further bog down my question but I see that the missing information is pertinent.
My input file is tab-delimited (which I have accounted for) and has ~50 fields of which I am only interested in 10. I've created the Feature Class to have those 10 fields. 3 of the fields need to be transformed, converted from feet to meters and then rounded to have no decimal places (I only included one of those fields in the example because the methodology would be identical). I could do this in 2 steps by creating an imperial field in the output file, populating the metric field via field calculator, then deleting the imperial field but was hoping to do it in one step to save that file maintenance at the end.
I have the index positions of all the input file fields and I know the order in which they should be inserted into the Feature Class. For example, for the 4 fields in my original post the index positions are [5], [6], [9], [4]. (The Lat and Long fields [5] [6] are required in the output file and will also be used with the SHAPE@XY token to create the point geometry.)
The if statement filters only records whose code has been specified by the user and tree height is >= 100 ft.
This bottom part of this post from Stack Exchange looks promising, but I haven't been able to test it out yet and I clearly am not entirely sure what I'm doing just yet.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If it is a csv file, there is little point creating a bunch of fields... just read the file.
To read the file, you can use numpy (lines 1, 6, 8). You need to describe your input columns.
lat and lon are doubles (f8), Desc is a text column (unicode 50 characters), hght is an integer (i4)
Line 8, reads the tree.csv file, skips the first row since that was column text headers, the data type was described on line 6 and it is a comma-delimited file.
arcpy needs a featureclass name (line 10), then it use the data access Numpyarraytofeatureclass method to create a point featureclass (fc) from an array (a), which uses the longitude, latitude fields to make the point geometry... and every file needs a spatial reference (back to line 4, which is a GCS-WGS84)
import numpy as np
import arcpy
SR = arcpy.SpatialReference(4326)
dt = [('lat', 'f8'), ('lon', 'f8'), ('Desc', 'U50'), ('hght', 'i4')]
a = np.genfromtxt("c:/temp/tree.csv", skip_header=1, dtype=dt, delimiter=",")
fc = r"C:\Arc_projects\Polygon_lineTools\Polygon_lineTools.gdb\trees"
arcpy.da.NumPyArrayToFeatureClass(a, fc, shape_fields=['lon', 'lat'], spatial_reference=SR)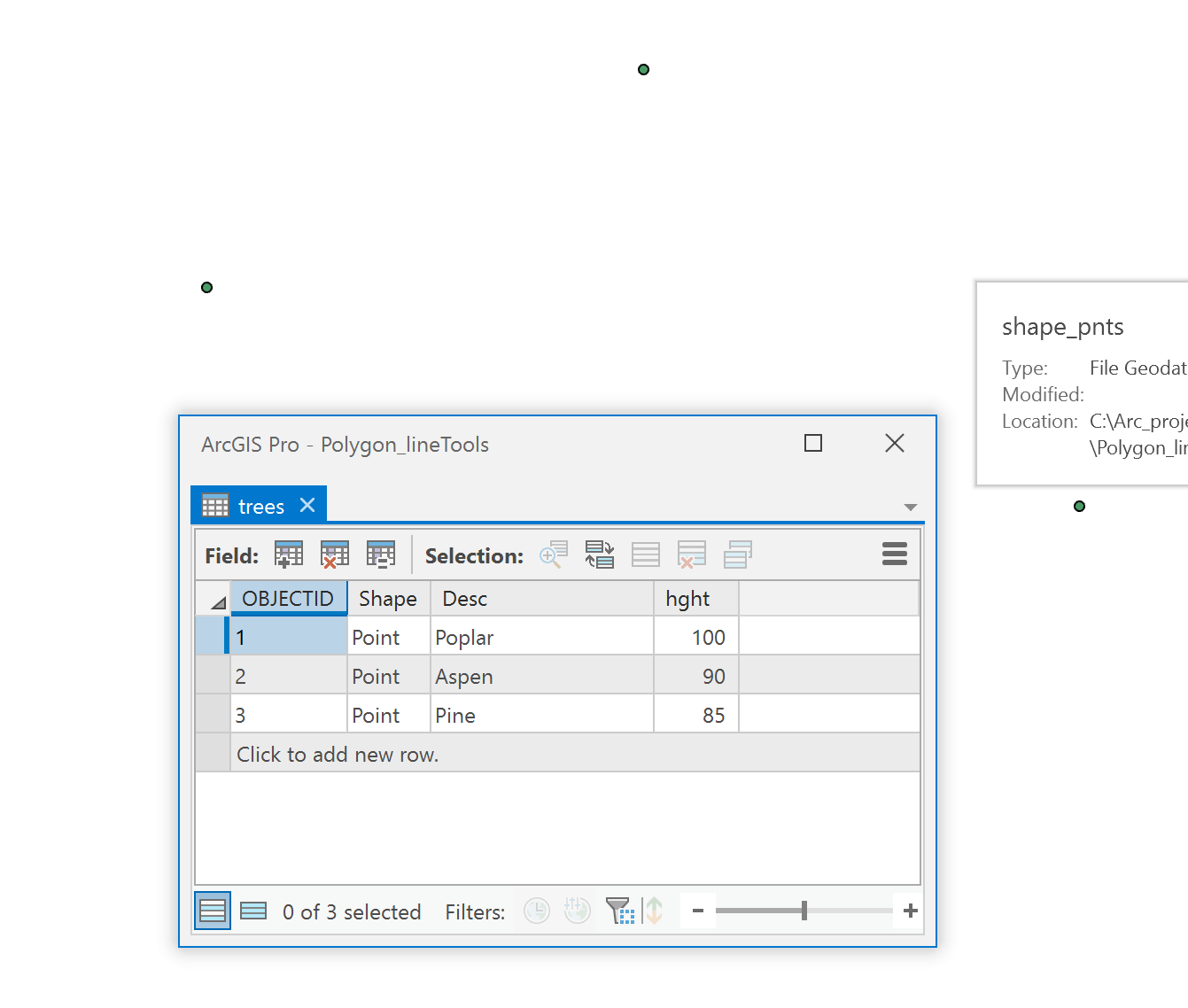
If you can describe your fields better and whether there are null values in them (ie blanks) and whether each column contains the same data type (ie... no spreadsheet mixing text and numbers in columns), then I can provide further help.
If you have a large number of columns to skip, you only need to record their names and column position, the rest will be skipped.
dt = 'f8,f8,U20,i4,i4,f8,U5'
n = ['lat', 'lon', 'desc', 'hght', 'junk2', 'another', 'again']
a0 = np.genfromtxt("c:/temp/tree.csv", dtype=dt, skip_header=1, delimiter=",",
names=n, usecols=[0, 1, 2, 3, 5, 6, 8])
a0
array([(45. , -75. , 'Poplar', 100, 1, 1., 'd'),
(45.1 , -75.1, 'Aspen', 90, 2, 2., 'e'),
(45.05, -75.2, 'Pine', 85, 3, 3., 'f')],
dtype=[('lat', '<f8'), ('lon', '<f8'), ('desc', '<U20'), ('hght', '<i4'),
('junk2', '<i4'), ('another', '<f8'), ('again', '<U5')])
#--- out it goes to a featureclass as beforeAlso, reading that in one go is going to be iffy, so chunking might be better or you might have to get into memory mapping to read portions from disk.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan; your suggestions are different from what I was expecting so it might take me a bit longer to understand, but I'm willing to try them out, thanks. Glad to have some different routes to try.
For more reference information: I am writing this to replace a standalone VB parser that wrote to a new text file which was then manually ingested to Arc using the Add XY Data function in Catalog. I have a bit of time so I thought I'd try to migrate that process into the Arc environment and create the output file all in one go. The VB parser is legacy from many years ago and chunked the data. I'm using 10.3 but am making the leap to 10.6 or 10.7 soon. Input file is tab-delimited. My input file does not mix data types within columns. The format of the output file is important because other processes after this depend on the field types - 5 fields are required by further process while the other 5 fields are needed just for reference. There is no header on the file but I know the schema. Some fields use -999 as a null while others have blank space - but all the fields I need to perform further tasks on will be 100% populated with real information (this is a condition of the file when it is created and is defined in the schema).
As for the memory issue - I thought the reason for processing the file line-by-line was to avoid the memory issues? That's what all the guidance and help I could find online said, that reading the file in one go was a bad move and that the easy solution was to process a line, dump it, process the next line, etc.... I could be misunderstanding your process and the guidance I read though... Or perhaps line-by-line isn't available in the method you're suggesting?
Thanks, hope this additional information helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Also the if statement I'm using is crucial to finding the needles in the haystack and then only processing and outputting the needles... Can it be incorporated using your method?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- The big issue was how many fields out of the identified do you actually need (ie their index numbers as in my second example). with either approach it sounds like there is a lot of baggage in the file to get rid of
- Once those are assembled, then it looked like you want to parse the records based on some threshold criteria
You can prune while you gather, but you don't want to process... ie you don't want to make the jam while you are picking the strawberries, just leave the rotten ones
- this whole insertcursor as you go can be done all at once, You will end up with a point featureclass with a defined coordinate system
The stuff that is purely numpy is obvious and documented, the arcpy (ie the numpyarray2f...) is less so, but it works and is a great addition and largely underused
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for all your help on this. I have done some more reading and just want to make sure I understand the method here... It looks much more simple and lightweight than what I was doing previously so I'm glad to try this out.
For your bullet points:
1. You are right about the baggage - each time this is run, it will only return maybe 0.25% of the data from the input file, hence the tool's necessity. I understand that the field widths have a big impact on memory usage with this method, so I'd have to constrain those really see if all the fields I output currently are crucial to my goals for this... There may be one or two that I can drop; they are integers so it won't save a lot of room but every little bit helps I suppose. In your example would the code create a massive array of my specified columns for the entire file? Or does it work one line at a time? I am confusing myself I think.
2. If I have the metaphor right, can I do the pruning before the gathering - just leave the rotten berries on the plant? ie can the if statement come before the array so lines that don't meet the threshold don't even get considered? Or is that just not how it works? Or does the array need to be completely created before I pick and choose the data to come out of it and into my featureclass? Pick every berry, throw out the bad ones, then make the jam.... Or does something else need to happen altogether?
3. Do you mean that the insertcursor business is compatible with your code, or that the insertcursor is a separate function that will also achieve the same result?
I will do much more reading on this...... btw I was never all that good with Avenue back when I was in school, but that was my fault and not my instructor's, he tried his best with me and I'm still doing GIS so that's good 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Alan, a small sample of the data could be useful to demonstrate the points
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
OK, that would go a long way to me understanding this. I will attach 100 lines of the data Friday morning. Will have to condition and anonymize it but for these purposes it will be good to go. Appreciate it