- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Conditionally deleting records
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Im trying to come up with a way to conditionally delete some records in a table. For instance, i have variably shaped polygons that when spatially joined with a point feature class tend to result in excess points on the larger polygons. I would like to set up a definition query to select and eventually delete every other or even every 2 out of 3 rows IF (and only if) there are, say more than 10 occurrences of that record. Im trying to implement this in arcmap via a python/sql query. Im sure there is way to do this in the output file (.csv) but I would like to maintain the integrity of the data in arcmap prior to exporting it.
Any help on how to go about doing this?
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Try the following in the interactive Python window (modify Lines #05 & #08). The code will select the records to keep, which you can invert to select the records to delete.
from collections import Counter
from itertools import groupby
from operator import itemgetter
fc = # path to feature class
group_size = 4
case_fields = ["Account_Nu"]
sort_field = "Image_Date" # Insert name of field with image dates
sql_orderby = "ORDER BY {}, {}".format(", ".join(case_fields), sort_field)
fl = arcpy.MakeFeatureLayer_management(fc, "fl").getOutput(0)
oidName = arcpy.Describe(fl).OIDFieldName
oids = []
with arcpy.da.SearchCursor(fl, "*", sql_clause=(None, sql_orderby)) as cur:
oidField = cur.fields.index(oidName)
case_func = itemgetter(
*(cur.fields.index(fld) for fld in case_fields)
)
count = Counter(case_func(row) for row in cur)
cur.reset()
for key, group in groupby(cur, case_func):
group_step = (
slice(None)
if count[key] < group_size else
slice(count[key]%group_size,None,count[key]//group_size)
)
oids += [row[oidField] for row in list(group)[group_step]]
fl.setSelectionSet("NEW_SELECTION", oids)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I see what you are after, but it is hard to respond in abstract concepts. If you can describe the structure of your data, and/or provide sample data, you will get better and more specific responses.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
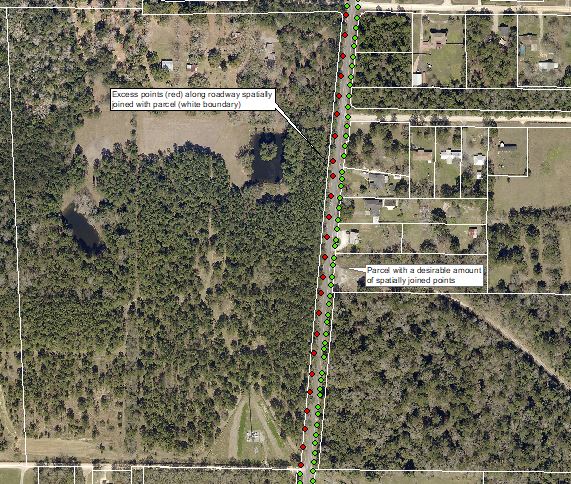
Hopefully this help to provide some context. Im working with parcel data and gps tagged photos. After a spatial join the photo points are associated with a parcel or rather an "Account_Nu". Below is an example of a typical scenario where one parcel may grab 20 points and the adjacent parcel grabs 3 or 4 based upon the length of existing road frontage. 3 or 4 pictures per parcel is desirable but anything over 10 is a bit excessive. I can parse these points down by running the delete identical tool but im limited to about a 10 ft buffer. The reason being is some parcels only have 30 or 40 ft of road frontage and im trying to at least get a couple points per parcel, any larger buffer and i could exclude entire parcels all together. The goal is to indiscriminately delete every other (or every 2 out of 3) point to still provide coverage but keep it trimmed as best as possible.
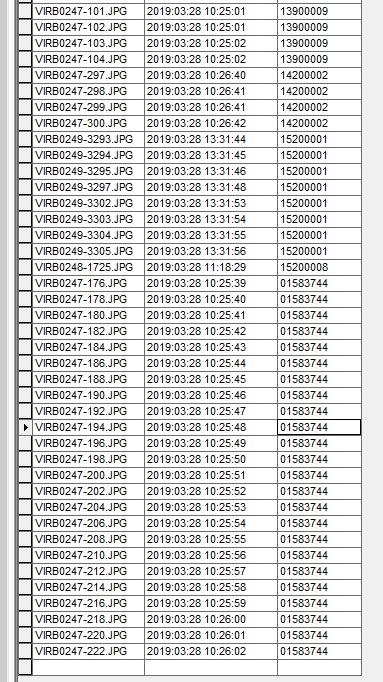
Below is a snapshot of the table, the "Account_Nu" being the primary field used to clean up the data. As you can see, multiple Account_Nu's are associated with many JPGs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Try the following in the interactive Python window (modify Lines #05 & #08). The code will select the records to keep, which you can invert to select the records to delete.
from collections import Counter
from itertools import groupby
from operator import itemgetter
fc = # path to feature class
group_size = 4
case_fields = ["Account_Nu"]
sort_field = "Image_Date" # Insert name of field with image dates
sql_orderby = "ORDER BY {}, {}".format(", ".join(case_fields), sort_field)
fl = arcpy.MakeFeatureLayer_management(fc, "fl").getOutput(0)
oidName = arcpy.Describe(fl).OIDFieldName
oids = []
with arcpy.da.SearchCursor(fl, "*", sql_clause=(None, sql_orderby)) as cur:
oidField = cur.fields.index(oidName)
case_func = itemgetter(
*(cur.fields.index(fld) for fld in case_fields)
)
count = Counter(case_func(row) for row in cur)
cur.reset()
for key, group in groupby(cur, case_func):
group_step = (
slice(None)
if count[key] < group_size else
slice(count[key]%group_size,None,count[key]//group_size)
)
oids += [row[oidField] for row in list(group)[group_step]]
fl.setSelectionSet("NEW_SELECTION", oids)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Bear with me as i dont have a good working understanding of Python.
for line 5 my path looks like this...
fc = ("x:\\Street_Level_Photography\\Street_Level_Photography.gdb\\Export_Output")
and im getting the following: Error 000732: Input Features: Dataset x:/Street_Level_Photography/Street_Level_Photography.gdb/Export_Output does not exist or is not supported
Im guessing there is a syntax error. Im not sure if this makes a difference but the data is not stored locally, should i use the server name rather than the drive name? Server name would be gemini, my drive name is x
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Is it a lower case x or and upper case X? that'll make a difference. Just as a matter of style, when setting paths, I prefer to use the 'r' functionality in python which allows you enter raw text. I'm lazy and would rather let the computer escape special characters like the \ .
fc = r'C:\path\to\gdb\featureclass'- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
As Joe Borgione points out, you are currently setting fc to a tuple containing a string, not a string.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
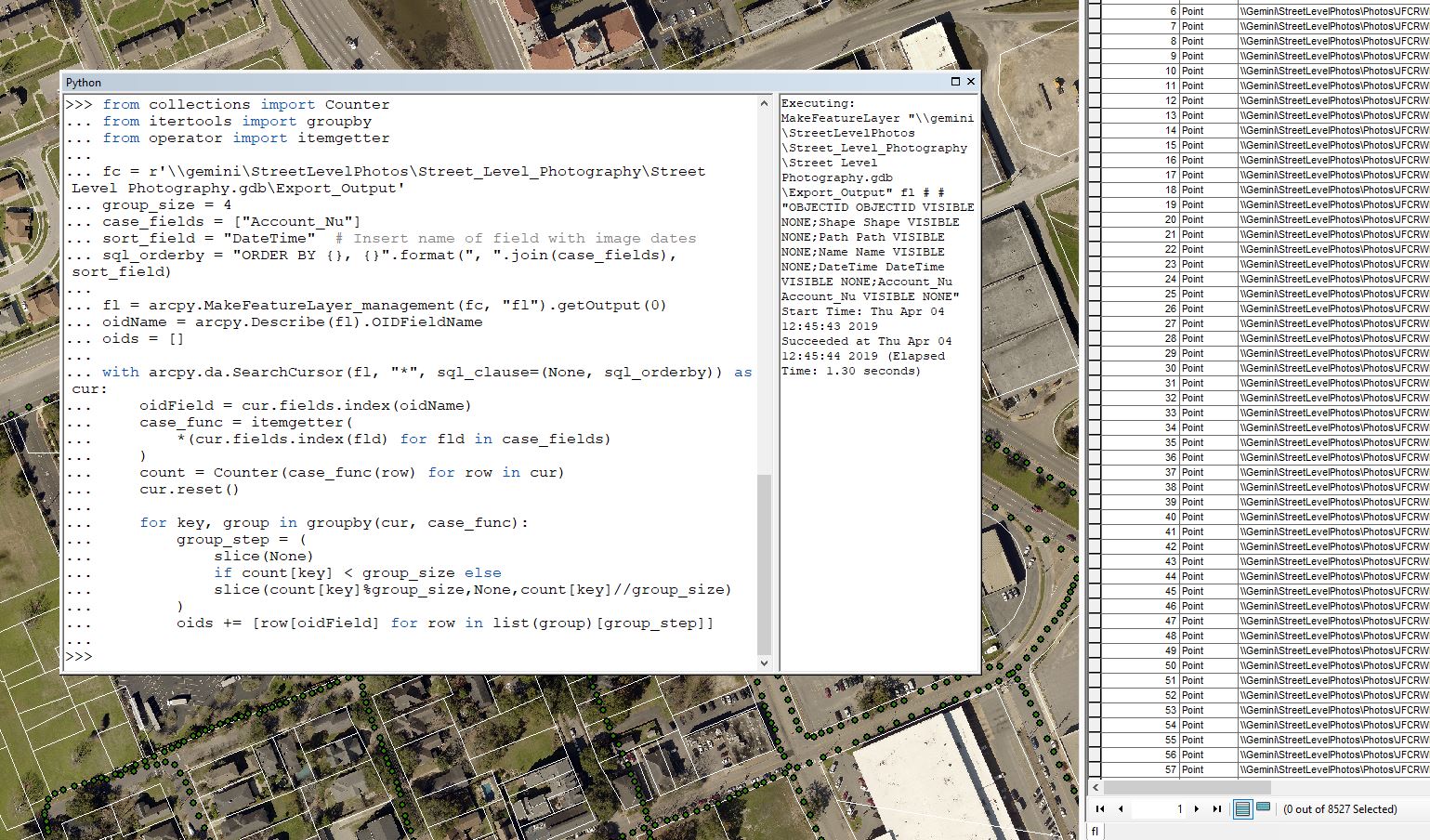
I was able to get it to the code run successfully and create the feature layer output, however the new feature layer (fl) is just a copy of the original feature class. 8527 records input, 8527 records output.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Feature layer and table views are not copies of data, they are views of data. If you have a feature class open in ArcMap, you are looking at a feature layer, often times it has the same name as the feature class it is referencing.
The code as written should be creating a new feature layer, which is appears to be doing, but it should also be selecting some records from that feature layer. If you open up the attribute table of the fl feature layer, are any records selected?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
There were no records selected. Here is the results window if it helps