- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Compare two tables field values using wildcard
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Compare two tables field values using wildcard
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello, I'm currently working with one feature class table containing 400 000 objects and one database table containing 700 objects. I'm currently working in ArcMap 10.4 and using a Geodatabase with Python 2.7. What I'm trying to do is match the database table containing 700 objects against the FC. What I want is to match them, treating all 700 objects as wildcars %700 ojects%, and match those towards the FC that contains text from the table. I have 2 tables with 1 column in each that im trying to match. I have not yet found a good way to treat all rows in a column as wildcard to search against another column.
This is my code so far. This only will print out what the database table values. Next i wanted to get the FC values and compare them. I've read about maybe using a dictionary to make it easier to extract values but I've yet to figure out how.
import arcpy, unicodedata, datetime, openpyxl
arcpy.env.workspace =r"C:\Users\kaaper\Documents\DataDrivenPages\DataDrivenPages.gdb"
def rows_as_dicts(cursor):
colnames = cursor.fields
for row in cursor:
yield dict(zip(colnames, row)
with arcpy.da.SearchCursor(r"C:\Users\kaaper\Documents\DataDrivenPages\DataDrivenPages.gdb\Ordbok", '*') as sc:
for row in rows_as_dicts(sc):
print row['field']Any input will be appreciated.
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I've run the code through all 400 000 records now, it only took around 10 minutes. But it seems that when removing comma it took the two words and merged them into one, so "ås, åsen" became "åsåsen", but other places the comma remained to so that the texts were treated as two separate words. I ended up with 40 000 matches, which i believe is a bit low, and I suspect it's because of that. But i can see if it's just an easy fix with space between the commas and text in the attributes. But this is really helpful nonetheless, thank you very much.
EDIT: Looking over again, it seems none of the words separated by comma has been matched. Which explains why there are so few matches at least, it seems in the last part of the code when it removes comma, is when it goes wrong. text = text.replace(',','') and when it replaces space as well text = text.replace(' ',''). Is this part needed to read the text correctly? Or does it still read the two words separated by comma as unique texts if i remove these two?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Per Olav Kaasa ,
That should not happen. I will look into that, but the idea is that the text is being stripped from everything that is between brackets, and that a comma is replaced by a space. If it encounters a double space that is replaced by a single place. It did notice that I replace the dash and the semicolon by an empty string and that may have caused two texts to be merged. I will check, but you could replace lines 65 to 69 by this (no correction for the comma though):
text = text.replace('"','')
text = text.replace(';',' ') # changed
text = text.replace('-',' ') # changed
text = text.replace(',',' ')
text = text.replace(' ','')- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I found out why it happend now, I applied the changes you made, but also made a tiny change to where it replaces comma with space. The next line of code removes places with double space, which in turn merges words with comma since they now had double space from the earlier code. I can also mention that I got 340 000 matches, so it seems everything works as it should now.
text = text.replace('"','')
text = text.replace(';',' ')
text = text.replace('-','')
text = text.replace(',','') #Changed, removed space
text = text.replace(' ','')- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Actually I think it would be better to have the comma to be replace by a space and the double space changed to a single space. However, if it works for you, it is OK. If the question is answered, can you mark the post that answered the question as the correct answer?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I just saw that myself, but it seems that it works with removing space, but both will work fine. Thank you very much for your help, this will be very useful in future tasks as well.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello, again, I'm currently working with the data and it seems that I have to make some changes to the script, to adapt it to the new parameters. Currently I want to search all text from "Ordbok" that have lowercase text and uppercase text differently. All text that starts with lowercase will be matched against text from "Navn" that's to the left of them and not both sides like earlier. The other text that starts with uppercase will only be matched against any text that's to the right. I tried looking through the script, but I'm not that versatile in Python yet, so I couldn't see where i should put the code for this. I'm guessing it's where "def FindMatches(lst_items, lst_dct):" starts, but again, I'm not sure. It would help me better understand what the script does as well so i can edit it later if needed.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Can you provide some examples of what is matched currently and how this should be changed?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This is how it currently looks after using the script. As you can see with for example "Tverreggi" is matched against "eggi" and "egg". With the new method, it would only match against "eggi" since it wouldnt count the right side of the text as wildcard.
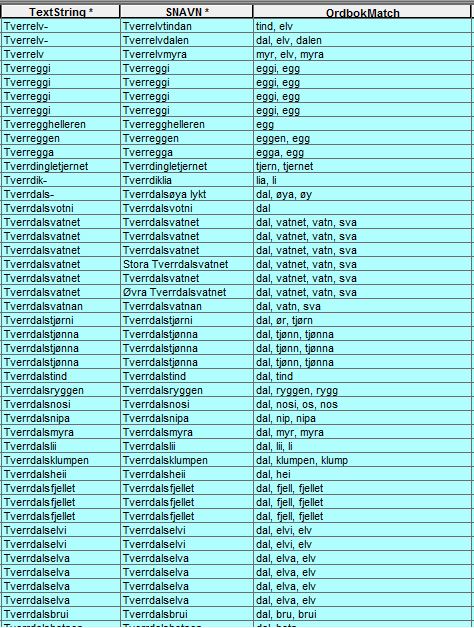
This is what i want(below), where as in the first example "Tverrdalstind" matched against both "dal" and "tind", it will now only match against "tind", since "dal" is not the end of the word and the new search will only check for wildcards on the left side of the text in "Ordbok", so if it has text on the right, it won't match. The other example shows text from "Ordbok" with capital letter at the start and therefore matches against the first part of the text "Nordrelandet" and "Nordre" since it only will search for the right side wildcards. This will give me fewer and more precise matches that I can use.
| SNAVN | OrdbokMatch |
|---|---|
| Tverrelvmyra | myra |
| Tverrdalstind | tind |
| Nordrelandet | Nordre |
Tverrdalstjønna | tjønna |
| Tverrdalselva | elva |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for the comprehensive explanation. If I understand correctly, when a value starts with an uppercase character, it should check the string using a "startswith" and when it is lowercase it should use "endswith".
It will check later what changes are required in the script to achieve this.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I made some changes to the code and this is what I get as result:
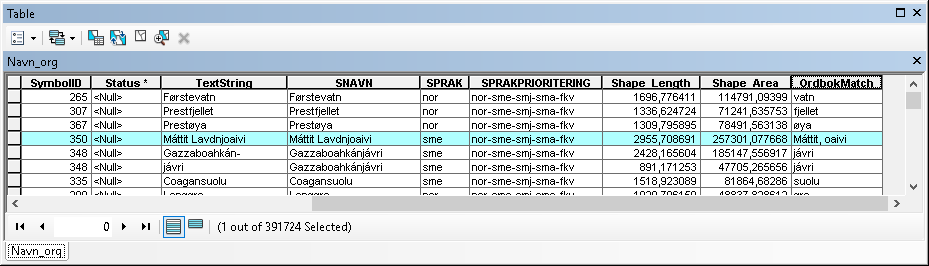
The code I used is posted below:
# -*- coding: utf-8 -*-
def main():
import arcpy
# settings (first uncompress geodatabase data!)
fc_anno = r'C:\GeoNet\SearchWildcard\gdb\TestBase.gdb\Navn_org'
fld_anno = 'SNAVN' # field to match with dictionary
fld_out = 'OrdbokMatch' # output field name
tbl = r'C:\GeoNet\SearchWildcard\gdb\TestBase.gdb\Ordbok'
fld_tbl = 'field' # dictionary data
# create dictionary list
lst_dct = [stripText2list(r[0]) for r in arcpy.da.SearchCursor(tbl, (fld_tbl))]
# Add output field to annotation
AddField(fc_anno, fld_out, "TEXT", 100)
# loop through annotation and update output field
cnt = 0
# dct_hits = {}
with arcpy.da.UpdateCursor(fc_anno, (fld_anno, fld_out)) as curs:
for row in curs:
cnt += 1
if cnt % 5000 == 0:
print "Processing row:", cnt
snavn = row[0]
lst_items = stripText2list(snavn)
result = FindMatches(lst_items, lst_dct)
row[1] = result
curs.updateRow(row)
def FindMatches(lst_items, lst_dct):
result = None
data = []
for lst_validate in lst_dct:
for validate in lst_validate:
for item in lst_items:
# if validate.upper() in item.upper():
if validate.istitle():
# first character is upper case, check start of string
if item.startswith(validate):
data.append(validate)
else:
# lower case, check end of string
if item.endswith(validate):
data.append(validate)
if len(data) > 0:
data = list(set(data))
result = data[0]
for data_item in data[1:]:
result += ", " + data_item
return result
def AddField(fc, fld_name, fld_type, fld_length=None):
if len(arcpy.ListFields(fc, fld_name)) == 0:
arcpy.AddField_management(fc, fld_name, fld_type, None, None, fld_length)
def stripText2list(text):
text_ori = text
lst_ok = []
if text is None:
return lst_ok
else:
s = text.find('(')
if s != -1:
e = text.find(')')
if e == -1:
e = len(text)-1
text = text[0:s] + text[e:len(text)-1]
text = text.replace('"','')
text = text.replace(';',' ')
text = text.replace('-',' ')
text = text.replace(',',' ')
while ' ' in text:
text = text.replace(' ',' ')
lst = text.split(' ')
for a in lst:
a = a.strip()
if a != '':
if a[0] != '(':
if a[-1:] != ')':
lst_ok.append(a)
return lst_ok
if __name__ == '__main__':
main()Modifications mainly on line 40 - 48 and I changed the 72 to 78 (due to something we discussed earlier)