- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Adding Labels Using Related Data
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello,
I've tried to utilize the code I found posted by Richard Fairhurst that allows you to create labels based on data contained within a related table to no avail. I keep getting the veritable "No features found. Could not verify expression". Everyone's favorite error message. BTW...a big shout out to Richard for posting this code and doing all he can to help others with this quest.
I am attempting to add the information contained under the Table field "Name" to individual polygons.
Any insight on what I am doing wrong would be most appreciated.
Thank you.
Jeff
Here is the logistics of my relationship class setup:
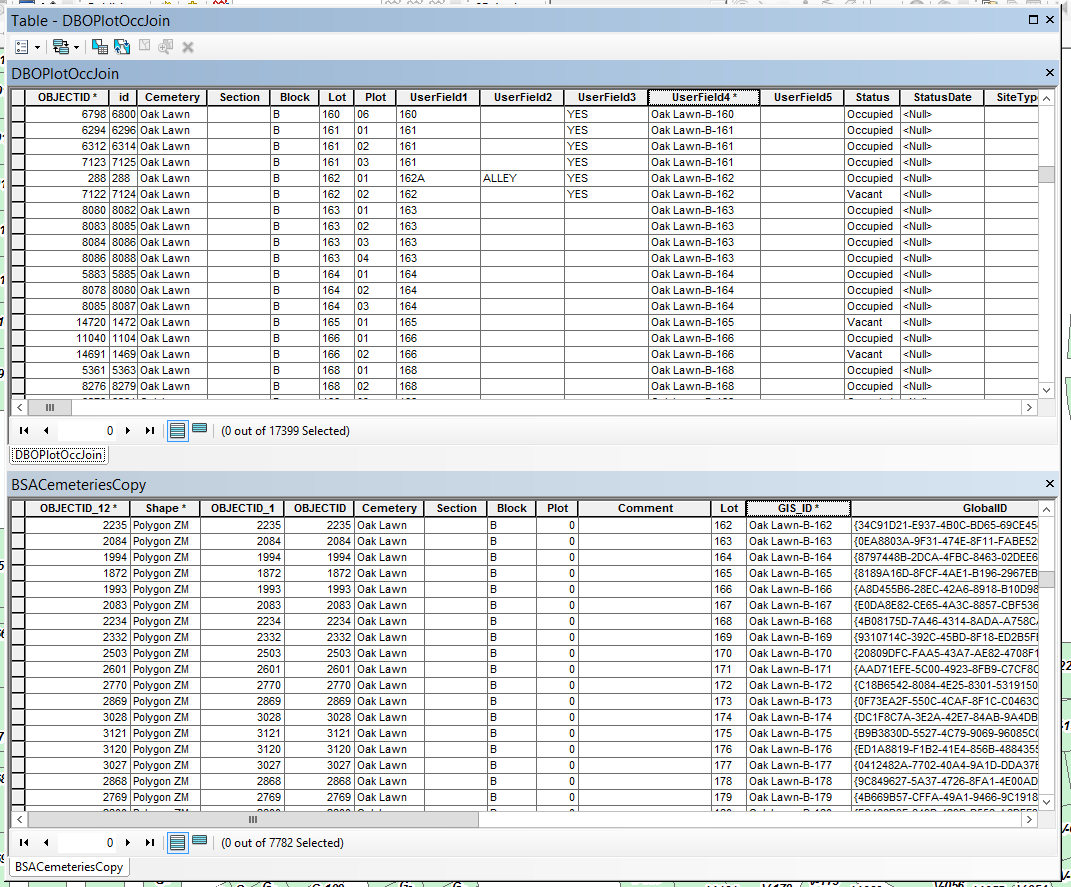
Origin Table: DBOPlotOccJoin
Primary Key: UserField4
Foreign Key: GIS_ID
Destination Table: BSACemeteriesCopy
Table Label Field: Name
Here is Richard's python code that I have augmented:
# Initialize a global dictionary for a related feature class/table
relateDict = {}
def FindLabel ( [UserField4] 😞
# declare the dictionary global so it can be built once and used for all labels
global relateDict
# only populate the dictionary if it has no keys
if len(relateDict) == 0:
# Provide the path and table name to the relate feature class/table
relateFC = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\DBOPlotOccJoin"
# create a field list with the relate field first (POLYID),
# followed by sort field(s) (SCHOOLID), then label field(s) (CROSS_STREET)
relateFieldsList = ["GIS_ID", "Name"]
# process a da search cursor to transfer the data to the dictionary
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
# store the key value in a variable so the relate value
# is only read from the row once, improving speed
relateKey = relateRow[0]
# if the relate key of the current row isn't found
# create the key and make it's value a list of a list of field values
if not relateKey in relateDict:
# [searchRow[1:]] is a list containing
# a list of the field values after the key.
relateDict[relateKey] = [relateRow[1:]]
else:
# if the relate key is already in the dictionary
# append the next list of field values to the
# existing list associated with the key
relateDict[relateKey].append(relateRow[1:])
# delete the cursor, and row to make sure all locks release
del relateRows, relateRow
# store the current label feature's relate key field value
# so that it is only read once, improving speed
labelKey = [UserField4]
# start building a label expression.
# My label has a bold key value header in a larger font
expression = '<FNT name="Arial" size="12"><BOL>{}</BOL></FNT>'.format(labelKey)
# determine if the label key is in the dictionary
if labelKey in relateDict:
# sort the list of the list of fields
sortedList = sorted(relateDict[labelKey])
# add a record count to the label header in bold regular font
expression += '\n<FNT name="Arial" size="10"><BOL>School Count = {}</BOL></FNT>'.format(len(sortedList))
# process the sorted list
for fieldValues in sortedList:
# append related data to the label expression
expression += '\n{0} - {1} - {2} - {3}'.format(fieldValues[0], fieldValues[1], fieldValues[2], fieldValues[3])
# clean up the list variables after completing the for loop
del sortedList, fieldValues
else:
expression += '\n<FNT name="Arial" size="10"><BOL>School Count = 0</BOL></FNT>'
# return the label expression to display
return expression
Solved! Go to Solution.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Randy,
Thank you for responding to my question.
I made the commenting out modifications you indicated and received a different error this time.
" no attribute 'extent'
Here is the code in case you need to see it again...
Thanks again.
Jeff
import arcpy # if not in python window
import os
# Prep work : set up some parameters
# feature with geometry - specifically polygons
fc = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\BSACemeteriesCopy"
# related table with data
relateFC = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\DBOPlotOccJoin"
relateFieldsList = ["UserField4", "Name"] # Born and Died are optional, others can be added
# new point feature we will create
outPath = r'R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb'
outName = 'AGO_cemetery'
outFields = ['SHAPE@X', 'SHAPE@Y', 'Cemetery', 'Plot', 'Name']
# full path to new feature
outFC = os.path.join(outPath, outName)
# Step 1 : create a new feature
# spatial reference for new feature
sr = arcpy.Describe(fc).SpatialReference # same spatial reference as source feature
# create the new feature
arcpy.CreateFeatureclass_management(out_path = outPath, out_name = outName, geometry_type = "POINT",
template = "#", has_m = "DISABLED", has_z = "DISABLED",
spatial_reference = sr)
# create fields (all text): Cemetery, Plot, Name, Born, Died
arcpy.AddField_management(in_table = outFC, field_name = 'Cemetery',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Cemetery", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Plot',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Plot", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Name',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Name", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
#arcpy.AddField_management(in_table = outFC, field_name = 'BirthDate',
#field_type = "STRING", field_precision = "#", field_scale = "#",
#field_length = 20, field_alias = "BirthDate", field_is_nullable = "NULLABLE",
#field_is_required = "NON_REQUIRED", field_domain = "#")
#arcpy.AddField_management(in_table = outFC, field_name = 'DeathDate',
#field_type = "STRING", field_precision = "#", field_scale = "#",
#field_length = 20, field_alias = "DeathDate", field_is_nullable = "NULLABLE",
#field_is_required = "NON_REQUIRED", field_domain = "#")
# Step 2 : build the related dictionary
relateDict = {}
# read the related table's data into a dictionary
# the key will be the first field in the relateFieldsList
# the value will be a list of tuples starting with the second field in the relatedFields list and using index [0]
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
relateKey = relateRow[0]
if not relateKey in relateDict:
relateDict[relateKey] = [relateRow[1:]]
else:
relateDict[relateKey].append(relateRow[1:])
del relateRows, relateRow # clean up
# Step 3 : populate the new feature
# ready an insert cursor and loop through source feature and dictionary
insertCursor = arcpy.da.InsertCursor(outFC, outFields)
with arcpy.da.SearchCursor(fc,['SHAPE@', 'Cemetery', 'GIS_ID']) as cursor:
for row in cursor:
labelKey = row[2] # the link
if labelKey in relateDict:
sortedList = sorted(relateDict[labelKey])
listCount = len(sortedList)
# calculate values for point geometry
xstep = (row[0].extent.XMax - row[0].extent.XMin)/listCount
ystep = (row[0].extent.YMax - row[0].extent.YMin)/listCount
xmin = row[0].extent.XMin + (xstep/2) # x coord for first point
ymin = row[0].extent.YMin + (ystep/2) # y coord for first point
# final data
for fieldValues in sortedList:
name = fieldValues[0]
# assuming the dates are type text/string and not type date
# otherwise some conversion will be required
#born = fieldValues[1]
#died = fieldValues[2]
# print(xmin, ymin, row[1], labelKey, name) # if printing, remove: born, died
insertCursor.insertRow([xmin, ymin, row[1], labelKey, name])# remove: born, died
xmin += xstep # add step to x coord
ymin += ystep # add step to y coord
else: # not in dictionary
pass # substitute with error code if necessary
del insertCursor
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Can you confirm the feature type is a polygon and not a point?
# feature with geometry - specifically polygons
fc = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\BSACemeteriesCopy"- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Randy,
Yes. BSACemeteriesCopy is a polygon feature class.
Jeff
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
With the error message coming up I didn't think to check if a point feature class was still created. Doh! I've attached a screen capture of the attribute table for AGO_cemetery. We actually have two cemeteries; Oak Lawn and Memorial Gardens. The attribute table only illustrates Oak Lawn even though the polygons for both cemeteries are included within the same feature class; BSACemeteriesCopy. Could that be the issue regarding the "extent" error message?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I suspect that at least one feature has bad or null geometry. I haven't tested it, but the following might give a clue. Insert it around line 78 - where the comment in the code matches. Of course, make sure the indentation is correct. It will probably still error on the lines following, but it may give us a clue to the issue.
# calculate values for point geometry
if row[0] is None:
print('Bad geometry for {}'.format(row[2]))If it does print a "bad geometry" message, see if ArcMap will draw the feature.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Could you provide a snapshot of how the code should look for Step 3? I'm a little confused as to where the above code should be placed and the correct indentation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The "Step 3" section would look like this:
# Step 3 : populate the new feature
# ready an insert cursor and loop through source feature and dictionary
insertCursor = arcpy.da.InsertCursor(outFC, outFields)
with arcpy.da.SearchCursor(fc,['SHAPE@', 'Cemetery', 'GIS_ID']) as cursor:
for row in cursor:
labelKey = row[2] # the link
if labelKey in relateDict:
sortedList = sorted(relateDict[labelKey])
listCount = len(sortedList)
# calculate values for point geometry
if row[0] is None:
print('Bad geometry for {}'.format(row[2]))
xstep = (row[0].extent.XMax - row[0].extent.XMin)/listCount
ystep = (row[0].extent.YMax - row[0].extent.YMin)/listCount
xmin = row[0].extent.XMin + (xstep/2) # x coord for first point
ymin = row[0].extent.YMin + (ystep/2) # y coord for first point
# final data
for fieldValues in sortedList:
name = fieldValues[0]
# assuming the dates are type text/string and not type date
# otherwise some conversion will be required
#born = fieldValues[1]
#died = fieldValues[2]
# print(xmin, ymin, row[1], labelKey, name) # if printing, remove: born, died
insertCursor.insertRow([xmin, ymin, row[1], labelKey, name])# remove: born, died
xmin += xstep # add step to x coord
ymin += ystep # add step to y coord
else: # not in dictionary
pass # substitute with error code if necessary
del insertCursorIf the geometry is null or None, then the program should print a message that contains the GIS_ID of the cemetery plot. It will then error out on the next line. Then look for the plot based on this information to see if ArcMap is able to display it.
I couldn't find the latest screen capture.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I received the following error message...
Executing: OccupantPtsRev2
Start Time: Tue Oct 27 13:53:02 2020
Running script OccupantPtsRev2...
Failed script OccupantPtsRev2...
IndentationError: unexpected indent (OccupantPtsRev2.py, line 79)
Failed to execute (OccupantPtsRev2).
Failed at Tue Oct 27 13:53:02 2020 (Elapsed Time: 0.02 seconds)
Line 79 (11 in above example) is where I inserted "if row[0] is None:" following your above indentation example.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Its possible that your IDE (or Python window in ArcMap) is getting confused over number of spaces or tabs used for indenting. Make sure the 'if row[0] is none:' lines up with the 'sorted_list..', 'list_count..' and comment lines before it. The 'print' line that follows should line up with 'name = fieldValues[0]' and comments starting about 7 lines later.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Yes. It was definitely getting confused. I made the modifications and am no longer getting the indent error but this error has arisen:
Traceback (most recent call last):
File "R:\Jeff\City_Projects\Cemetery\OccupantPtsRev2.py", line 81, in <module>
xstep = (row[0].extent.XMax - row[0].extent.XMin)/listCount
AttributeError: 'NoneType' object has no attribute 'extent'
Error corresponds to line 13 in the above you provided.