- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Adding Labels Using Related Data
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello,
I've tried to utilize the code I found posted by Richard Fairhurst that allows you to create labels based on data contained within a related table to no avail. I keep getting the veritable "No features found. Could not verify expression". Everyone's favorite error message. BTW...a big shout out to Richard for posting this code and doing all he can to help others with this quest.
I am attempting to add the information contained under the Table field "Name" to individual polygons.
Any insight on what I am doing wrong would be most appreciated.
Thank you.
Jeff
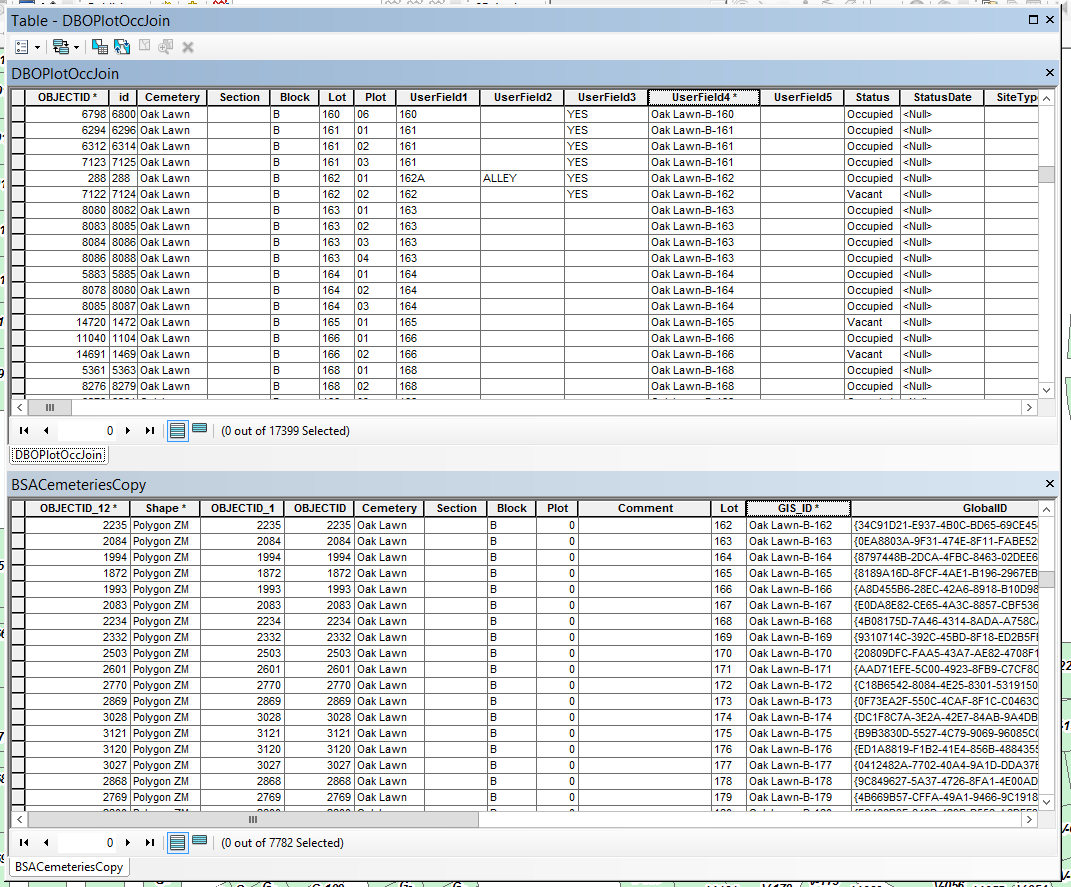
Here is the logistics of my relationship class setup:
Origin Table: DBOPlotOccJoin
Primary Key: UserField4
Foreign Key: GIS_ID
Destination Table: BSACemeteriesCopy
Table Label Field: Name
Here is Richard's python code that I have augmented:
# Initialize a global dictionary for a related feature class/table
relateDict = {}
def FindLabel ( [UserField4] 😞
# declare the dictionary global so it can be built once and used for all labels
global relateDict
# only populate the dictionary if it has no keys
if len(relateDict) == 0:
# Provide the path and table name to the relate feature class/table
relateFC = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\DBOPlotOccJoin"
# create a field list with the relate field first (POLYID),
# followed by sort field(s) (SCHOOLID), then label field(s) (CROSS_STREET)
relateFieldsList = ["GIS_ID", "Name"]
# process a da search cursor to transfer the data to the dictionary
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
# store the key value in a variable so the relate value
# is only read from the row once, improving speed
relateKey = relateRow[0]
# if the relate key of the current row isn't found
# create the key and make it's value a list of a list of field values
if not relateKey in relateDict:
# [searchRow[1:]] is a list containing
# a list of the field values after the key.
relateDict[relateKey] = [relateRow[1:]]
else:
# if the relate key is already in the dictionary
# append the next list of field values to the
# existing list associated with the key
relateDict[relateKey].append(relateRow[1:])
# delete the cursor, and row to make sure all locks release
del relateRows, relateRow
# store the current label feature's relate key field value
# so that it is only read once, improving speed
labelKey = [UserField4]
# start building a label expression.
# My label has a bold key value header in a larger font
expression = '<FNT name="Arial" size="12"><BOL>{}</BOL></FNT>'.format(labelKey)
# determine if the label key is in the dictionary
if labelKey in relateDict:
# sort the list of the list of fields
sortedList = sorted(relateDict[labelKey])
# add a record count to the label header in bold regular font
expression += '\n<FNT name="Arial" size="10"><BOL>School Count = {}</BOL></FNT>'.format(len(sortedList))
# process the sorted list
for fieldValues in sortedList:
# append related data to the label expression
expression += '\n{0} - {1} - {2} - {3}'.format(fieldValues[0], fieldValues[1], fieldValues[2], fieldValues[3])
# clean up the list variables after completing the for loop
del sortedList, fieldValues
else:
expression += '\n<FNT name="Arial" size="10"><BOL>School Count = 0</BOL></FNT>'
# return the label expression to display
return expression
Solved! Go to Solution.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Did it print a message just before the error? It should have printed something like: "Bad geometry for xxxx-x-xxx". The "AttributeError: 'NoneType' object has no attribute 'extent'" indicates the last feature processed had null or missing geometry.
There is a check geometry tool in the ArcToolbox (Data Management Tools > Features > Check Geometry). Use "R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\BSACemeteriesCopy" as the feature to check. It should find the features with bad geometry.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
No. There was no message of an error.
I checked the geometry and it appears I have 12 issues; 9 self intersections and 3 null geometry.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I do have a couple follow-up questions...I'd like to add additional field outputs beyond Cemetery, Plot and Name.
I've created two additional fields in DBOPlotOccJoin; one called Vettxt (text field featuring binary 0 or 1, Vet or not) and the other called OccLoc (featuring the entire Cemetery-Block-Lot-Plot as text). I have tried a few things that seemed "logical" of where to place these to be added as output fields but they don't seem to come over after the code is run. If I want them added along with Cemetery, Plot and Name, where should they go in the code?
Also, I would like to add BirthDate and DeathDate. Do I need to convert them to text or just change string to date and modify the Born and Died call outs?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Since these fields are in the DBOPlotOccJoin table, they would be added after the birth and death dates. The Vettxt is type Boolean or Integer? Is the OccLoc field a duplicate of the UserField4, or is it a bit different?
Regarding BirthDate and DeathDate fields, are they type date, or something custom? Sometimes cemetery markers do not give a complete date, so I am curious if there are any rules for handling such dates.
I'll take a fresh look at the code and make some suggestions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
That would be great, Randy.
The Vettxt is actually a text field. It was numeric as another field but I converted it to text.
The OccLoc field is text and is just a tidier version with better dashes.
The BirthDate and DeathDate fields are dates at present. It appears they had more luck recording the death dates than the birth dates. A few null values in the birth dates.
Thanks again,
Jeff
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here is the latest "original" code that I have from you if that helps. I commented out the sections we discussed earlier but everything else is the same...minus the fields I have tried to add to no avail.
import arcpy # if not in python window
import os
# Prep work : set up some parameters
# feature with geometry - specifically polygons
fc = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\BSACemeteriesCopy"
# related table with data
relateFC = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\DBOPlotOccJoin"
relateFieldsList = ["UserField4", "Name"] # Born and Died are optional, others can be added
# new point feature we will create
outPath = r'R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb'
outName = 'AGO_cemetery'
outFields = ['SHAPE@X', 'SHAPE@Y', 'Cemetery', 'Plot', 'Name']
# full path to new feature
outFC = os.path.join(outPath, outName)
# Step 1 : create a new feature
# spatial reference for new feature
sr = arcpy.Describe(fc).SpatialReference # same spatial reference as source feature
# create the new feature
arcpy.CreateFeatureclass_management(out_path = outPath, out_name = outName, geometry_type = "POINT",
template = "#", has_m = "DISABLED", has_z = "DISABLED",
spatial_reference = sr)
# create fields (all text): Cemetery, Plot, Name, Born, Died
arcpy.AddField_management(in_table = outFC, field_name = 'Cemetery',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Cemetery", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Plot',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Plot", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Name',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Name", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
#arcpy.AddField_management(in_table = outFC, field_name = 'BirthDate',
#field_type = "STRING", field_precision = "#", field_scale = "#",
#field_length = 20, field_alias = "BirthDate", field_is_nullable = "NULLABLE",
#field_is_required = "NON_REQUIRED", field_domain = "#")
#arcpy.AddField_management(in_table = outFC, field_name = 'DeathDate',
#field_type = "STRING", field_precision = "#", field_scale = "#",
#field_length = 20, field_alias = "DeathDate", field_is_nullable = "NULLABLE",
#field_is_required = "NON_REQUIRED", field_domain = "#")
# Step 2 : build the related dictionary
relateDict = {}
# read the related table's data into a dictionary
# the key will be the first field in the relateFieldsList
# the value will be a list of tuples starting with the second field in the relatedFields list and using index [0]
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
relateKey = relateRow[0]
if not relateKey in relateDict:
relateDict[relateKey] = [relateRow[1:]]
else:
relateDict[relateKey].append(relateRow[1:])
del relateRows, relateRow # clean up
# Step 3 : populate the new feature
# ready an insert cursor and loop through source feature and dictionary
insertCursor = arcpy.da.InsertCursor(outFC, outFields)
with arcpy.da.SearchCursor(fc,['SHAPE@', 'Cemetery', 'GIS_ID']) as cursor:
for row in cursor:
labelKey = row[2] # the link
if labelKey in relateDict:
sortedList = sorted(relateDict[labelKey])
listCount = len(sortedList)
# calculate values for point geometry
xstep = (row[0].extent.XMax - row[0].extent.XMin)/listCount
ystep = (row[0].extent.YMax - row[0].extent.YMin)/listCount
xmin = row[0].extent.XMin + (xstep/2) # x coord for first point
ymin = row[0].extent.YMin + (ystep/2) # y coord for first point
# final data
for fieldValues in sortedList:
name = fieldValues[0]
# assuming the dates are type text/string and not type date
# otherwise some conversion will be required
#born = fieldValues[1]
#died = fieldValues[2]
# print(xmin, ymin, row[1], labelKey, name) # if printing, remove: born, died
insertCursor.insertRow([xmin, ymin, row[1], labelKey, name])# remove: born, died
xmin += xstep # add step to x coord
ymin += ystep # add step to y coord
else: # not in dictionary
pass # substitute with error code if necessary
del insertCursorAlso, I repaired the geometry issues and ran the above code and everything came through including our other cemetery. It works great. Thank you.
I've tried adding the additional fields that I mentioned in my previous inquiry but it refuses to carry them over. Hopefully you will be able to once again enlighten me.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here's some code to try:
import arcpy # if not in python window
import os
# set up variables
# feature with geometry - specifically polygons)
fc = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\BSACemeteriesCopy"
# related table with data
relateFC = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\DBOPlotOccJoin"
relateFieldsList = ["UserField4", "Name", "BirthDate", "DeathDate", "Vettxt", "OccLoc"]
# new point feature we will create
outPath = r'C:\Users\Randy\Documents\ArcGIS\PythonScripts\fairhurst\fairhurst.gdb'
outName = 'AGO_cemetery'
outFields = ['SHAPE@X', 'SHAPE@Y', 'Cemetery', 'Plot', 'Name', 'BirthDate', 'DeathDate', 'Vettxt', 'OccLoc']
# full path to new feature
outFC = os.path.join(outPath, outName)
# Step 1 : create a new feature
# spatial reference for new feature
sr = arcpy.Describe(fc).SpatialReference # same spatial reference as source feature
# create the new feature
arcpy.CreateFeatureclass_management(out_path = outPath, out_name = outName, geometry_type = "POINT",
template = "#", has_m = "DISABLED", has_z = "DISABLED",
spatial_reference = sr)
# create fields: Cemetery, Plot, Name, BirthDate, DeathDate, Vettxt, OccLoc
# modify the size of text fields as required
arcpy.AddField_management(in_table = outFC, field_name = 'Cemetery',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Cemetery", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Plot',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Plot", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Name',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Name", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'BirthDate',
field_type = "DATE", field_precision = "#", field_scale = "#",
field_length = "#", field_alias = "BirthDate", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'DeathDate',
field_type = "DATE", field_precision = "#", field_scale = "#",
field_length = "#", field_alias = "DeathDate", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Vettxt',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 1, field_alias = "Vettxt", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'OccLoc',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "OccLoc", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
# Step 2 : build the related dictionary
relateDict = {}
# read the related table's data into a dictionary
# the key will be the first field in the relateFieldsList
# the value will be a list of tuples starting with the second field in the relatedFields list and using index [0]
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
relateKey = relateRow[0]
if not relateKey in relateDict:
relateDict[relateKey] = [relateRow[1:]]
else:
relateDict[relateKey].append(relateRow[1:])
del relateRows, relateRow # clean up
# Step 3 : populate the new feature
# ready an insert cursor and loop through source feature and dictionary
insertCursor = arcpy.da.InsertCursor(outFC, outFields)
with arcpy.da.SearchCursor(fc,['SHAPE@', 'Cemetery', 'GIS_ID']) as cursor:
for row in cursor:
labelKey = row[2] # the link
cemetery = row[1] # cemetery name
if labelKey in relateDict:
sortedList = sorted(relateDict[labelKey])
listCount = len(sortedList)
# calculate values for point geometry
xstep = (row[0].extent.XMax - row[0].extent.XMin)/listCount
ystep = (row[0].extent.YMax - row[0].extent.YMin)/listCount
xmin = row[0].extent.XMin + (xstep/2) # x coord for first point
ymin = row[0].extent.YMin + (ystep/2) # y coord for first point
# final data
for fieldValues in sortedList:
# field values from related table : add additional processing if necessary
name = fieldValues[0]
born = fieldValues[1]
died = fieldValues[2]
vet = fieldValues[3]
occloc = fieldValues[4]
# print(xmin, ymin, cemetery, labelKey, name, born, died, vet, occloc)
insertCursor.insertRow([xmin, ymin, cemetery, labelKey, name, born, died, vet, occloc])
xmin += xstep # add step to x coord
ymin += ystep # add step to y coord
else: # not in dictionary
pass # substitute with error code if necessary
del insertCursorIn line 10 and line 15, the birth/death, veteran, and location fields have been added to the list of field names.
In Step 1 (lines 20-58), additions have been made to the fields for the output feature. Suggestions to think about, after testing the code: Since this is going to AGO, you may wish to rename the fields to something that may make more sense to the user - or at least change the alias to something more meaningful. If you rename fields you will need to make the appropriate changes to lines 10 an 15. The Vettxt being a 1 or 0 may not make sense to the end user. A true/false a Y/N may make more sense.
Lines 96-102 have been modified to include the new fields. Other than that, I think the remaining code is mostly the same. Hope this helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Randy,
Thank you again for your assistance. I ran the above code and received the following error message:
Executing: OccupantPtsEnhanced
Start Time: Thu Oct 29 06:38:15 2020
Running script OccupantPtsEnhanced...
Failed script OccupantPtsEnhanced...
Traceback (most recent call last):
File "R:\Jeff\City_Projects\Cemetery\OccupantPtsEnhanced.py", line 86, in <module>
sortedList = sorted(relateDict[labelKey])
TypeError: can't compare datetime.datetime to NoneType
Failed to execute (OccupantPtsEnhanced).
Failed at Thu Oct 29 06:38:21 2020 (Elapsed Time: 5.61 seconds)
Hopefully this will make some sense to you.
Thanks.
Jeff
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The sorted function is trying to sort the relateDict by all fields. Since some of the dates are null values, the function can't determine which should come first. You can either leave it unsorted or sort it only by the first element which is the name.
# Replace the line:
sortedList = sorted(relateDict[labelKey])
# With this to leave unsorted:
sortedList = relateDict[labelKey]
# Or with this to sort only by first element (name) by using the key parameter:
sortedList = sorted(relateDict[labelKey], key=lambda x: x[0])I would suggest leaving unsorted for now; use line 5.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
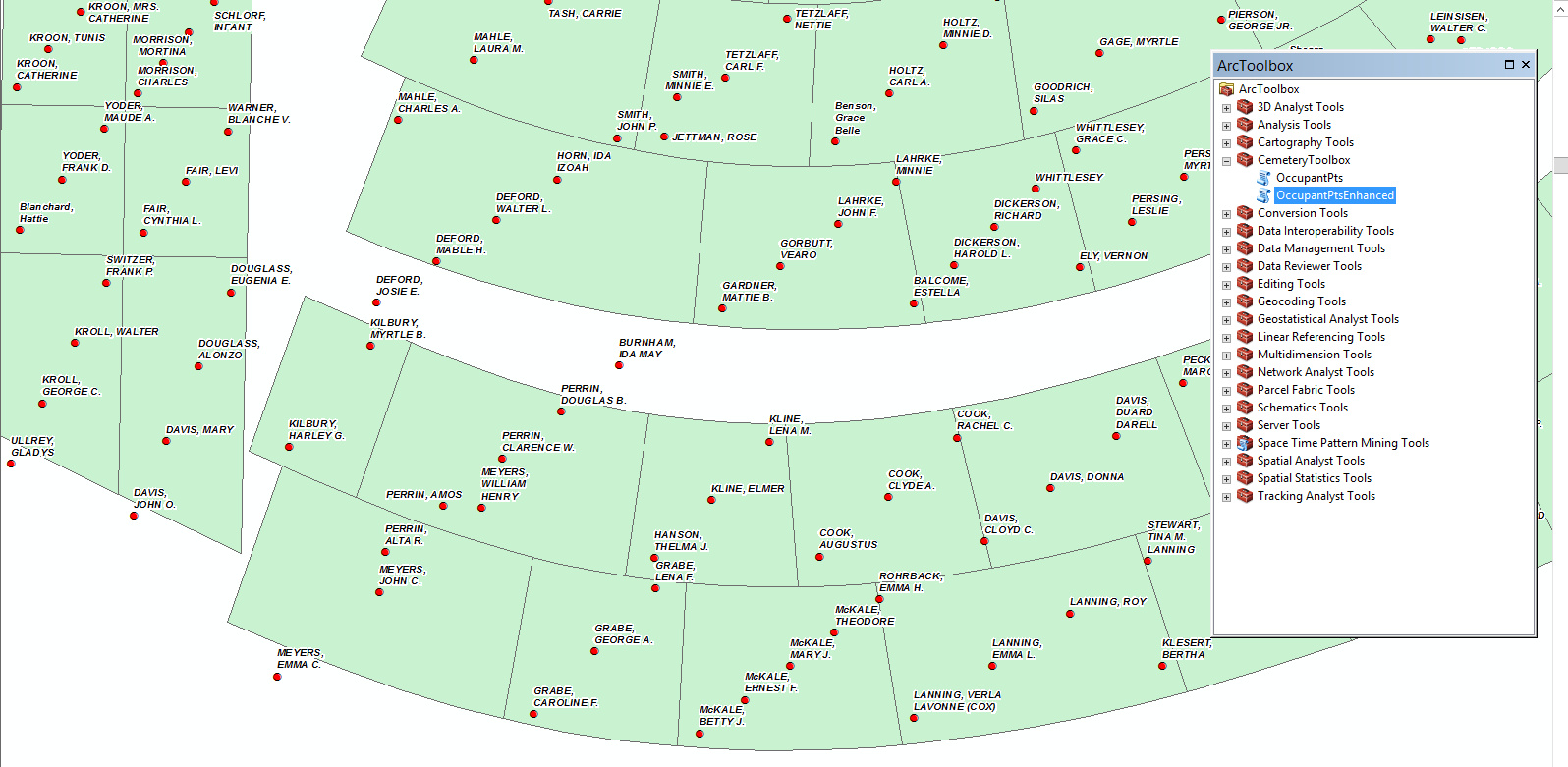
That worked perfectly, Randy. I attached a screen capture to show you how the points appear after the code is executed. They are all more or less inside the polygons. I can go around to each polygon and relocate those points that fell outside their respective boundary.
Thank you again for all your hard work! I really appreciate your assistance and this will go along way to helping us better manage our cemetery plots. With Veterans Day coming up it couldn't have come at a better time.
Jeff
- « Previous
- Next »
- « Previous
- Next »