- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Adding Labels Using Related Data
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello,
I've tried to utilize the code I found posted by Richard Fairhurst that allows you to create labels based on data contained within a related table to no avail. I keep getting the veritable "No features found. Could not verify expression". Everyone's favorite error message. BTW...a big shout out to Richard for posting this code and doing all he can to help others with this quest.
I am attempting to add the information contained under the Table field "Name" to individual polygons.
Any insight on what I am doing wrong would be most appreciated.
Thank you.
Jeff
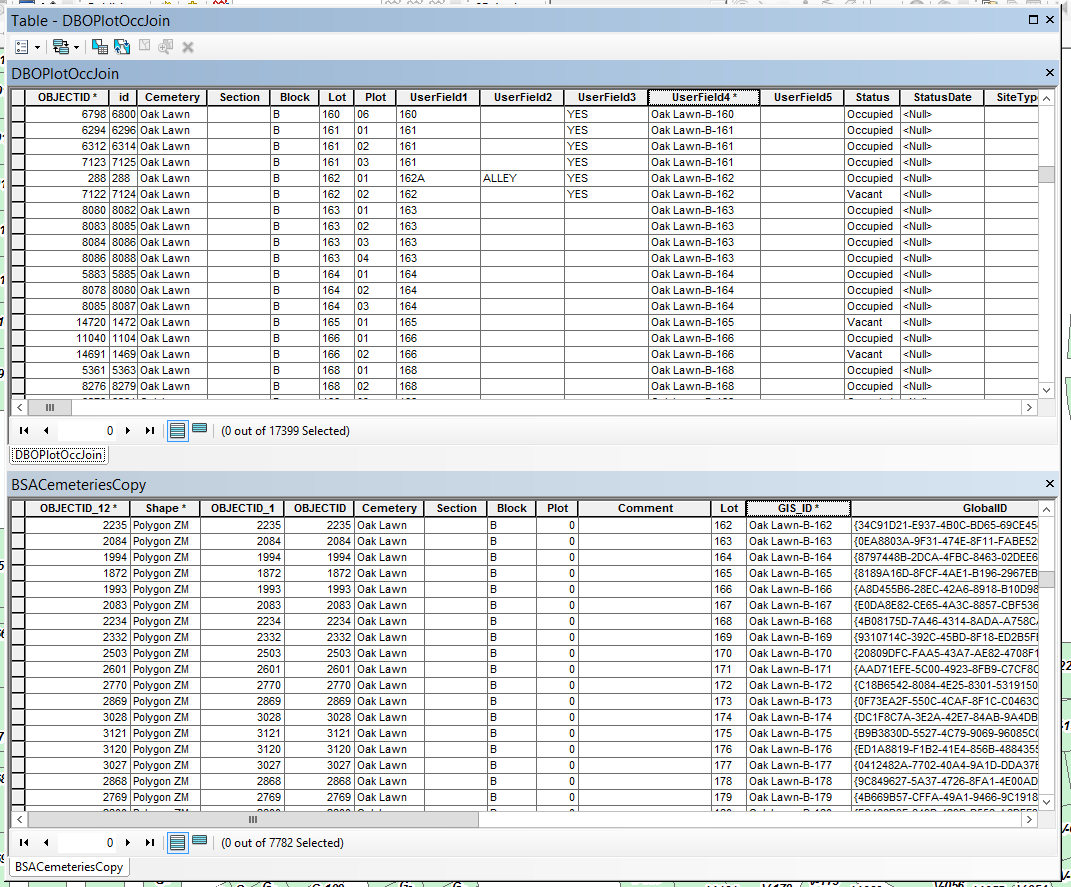
Here is the logistics of my relationship class setup:
Origin Table: DBOPlotOccJoin
Primary Key: UserField4
Foreign Key: GIS_ID
Destination Table: BSACemeteriesCopy
Table Label Field: Name
Here is Richard's python code that I have augmented:
# Initialize a global dictionary for a related feature class/table
relateDict = {}
def FindLabel ( [UserField4] 😞
# declare the dictionary global so it can be built once and used for all labels
global relateDict
# only populate the dictionary if it has no keys
if len(relateDict) == 0:
# Provide the path and table name to the relate feature class/table
relateFC = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\DBOPlotOccJoin"
# create a field list with the relate field first (POLYID),
# followed by sort field(s) (SCHOOLID), then label field(s) (CROSS_STREET)
relateFieldsList = ["GIS_ID", "Name"]
# process a da search cursor to transfer the data to the dictionary
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
# store the key value in a variable so the relate value
# is only read from the row once, improving speed
relateKey = relateRow[0]
# if the relate key of the current row isn't found
# create the key and make it's value a list of a list of field values
if not relateKey in relateDict:
# [searchRow[1:]] is a list containing
# a list of the field values after the key.
relateDict[relateKey] = [relateRow[1:]]
else:
# if the relate key is already in the dictionary
# append the next list of field values to the
# existing list associated with the key
relateDict[relateKey].append(relateRow[1:])
# delete the cursor, and row to make sure all locks release
del relateRows, relateRow
# store the current label feature's relate key field value
# so that it is only read once, improving speed
labelKey = [UserField4]
# start building a label expression.
# My label has a bold key value header in a larger font
expression = '<FNT name="Arial" size="12"><BOL>{}</BOL></FNT>'.format(labelKey)
# determine if the label key is in the dictionary
if labelKey in relateDict:
# sort the list of the list of fields
sortedList = sorted(relateDict[labelKey])
# add a record count to the label header in bold regular font
expression += '\n<FNT name="Arial" size="10"><BOL>School Count = {}</BOL></FNT>'.format(len(sortedList))
# process the sorted list
for fieldValues in sortedList:
# append related data to the label expression
expression += '\n{0} - {1} - {2} - {3}'.format(fieldValues[0], fieldValues[1], fieldValues[2], fieldValues[3])
# clean up the list variables after completing the for loop
del sortedList, fieldValues
else:
expression += '\n<FNT name="Arial" size="10"><BOL>School Count = 0</BOL></FNT>'
# return the label expression to display
return expression
Solved! Go to Solution.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Okay. Thought I would check. I will ask that exact question on the AGO forum. Thank you so much again for your time and effort on this Randy!
Jeff
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Jeff Davis and Randy Burton ,
Regarding the question "can Arcade create labels using data from related tables" I am afraid the answer is no... In the label profile Arcade has no access to related tables. You will need to add a field in the main featureset and fill it with the information of the related table(s) in order to show it as a label.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Xander,
Thanks for replying. Too bad. I was hoping to eliminate a little database work. Since it's a one to many relationship I'll not only need to add additional fields but create stacked polygons for the additional data. Doh...oh well...could be worse. I could be completely without this marvelous Randy Burton code!
Thanks again, Xander.
Jeff
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If it is helpful, I can post some code later that will read data from the feature and related table to create a new feature with one point per name that might meet your needs on AGO. You could also add dates or other information if it is in the related table.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Randy...that would be amazing if it's not too much trouble for you!!! Thank you so much!!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Here is some test code that will give you an idea how to read the data from a feature and related table and create a point feature for use on AGO. I have made some assumptions, so you will probably need to do some tweaking.
import arcpy # if not in python window
import os
# Prep work : set up some parameters
# feature with geometry - specifically polygons
fc = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\BSACemeteriesCopy"
# related table with data
relateFC = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\DBOPlotOccJoin"
relateFieldsList = ["UserField4", "Name", "Born", "Died"] # Born and Died are optional, others can be added
# new point feature we will create
outPath = r'R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb'
outName = 'AGO_cemetery'
outFields = ['SHAPE@X', 'SHAPE@Y', 'Cemetery', 'Plot', 'Name', 'Born', 'Died']
# full path to new feature
outFC = os.path.join(outPath, outName)
# Step 1 : create a new feature
# spatial reference for new feature
sr = arcpy.Describe(fc).SpatialReference # same spatial reference as source feature
# create the new feature
arcpy.CreateFeatureclass_management(out_path = outPath, out_name = outName, geometry_type = "POINT",
template = "#", has_m = "DISABLED", has_z = "DISABLED",
spatial_reference = sr)
# create fields (all text): Cemetery, Plot, Name, Born, Died
arcpy.AddField_management(in_table = outFC, field_name = 'Cemetery',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Cemetery", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Plot',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Plot", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Name',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Name", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Born',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 20, field_alias = "Born", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Died',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 20, field_alias = "Died", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
# Step 2 : build the related dictionary
relateDict = {}
# read the related table's data into a dictionary
# the key will be the first field in the relateFieldsList
# the value will be a list of tuples starting with the second field in the relatedFields list and using index [0]
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
relateKey = relateRow[0]
if not relateKey in relateDict:
relateDict[relateKey] = [relateRow[1:]]
else:
relateDict[relateKey].append(relateRow[1:])
del relateRows, relateRow # clean up
# Step 3 : populate the new feature
# ready an insert cursor and loop through source feature and dictionary
insertCursor = arcpy.da.InsertCursor(outFC, outFields)
with arcpy.da.SearchCursor(fc,['SHAPE@', 'Cemetery', 'GIS_ID']) as cursor:
for row in cursor:
labelKey = row[2] # the link
if labelKey in relateDict:
sortedList = sorted(relateDict[labelKey])
listCount = len(sortedList)
# calculate values for point geometry
xstep = (row[0].extent.XMax - row[0].extent.XMin)/listCount
ystep = (row[0].extent.YMax - row[0].extent.YMin)/listCount
xmin = row[0].extent.XMin + (xstep/2) # x coord for first point
ymin = row[0].extent.YMin + (ystep/2) # y coord for first point
# final data
for fieldValues in sortedList:
name = fieldValues[0]
# assuming the dates are type text/string and not type date
# otherwise some conversion will be required
born = fieldValues[1]
died = fieldValues[2]
# print(xmin, ymin, row[1], labelKey, name, born, died)
insertCursor.insertRow([xmin, ymin, row[1], labelKey, name, born, died])
xmin += xstep # add step to x coord
ymin += ystep # add step to y coord
else: # not in dictionary
pass # substitute with error code if necessary
del insertCursorIn the prep section (lines 4-15), the features and table are named along with the specific fields that are being accessed. Modify as needed.
Lines 20-49 create a new point feature to store the combined data from the source feature and the related table. All fields have been set as type text. It is possible that you may wish to omit the born and died fields or set them as dates. In my explorations of cemeteries and genealogy records, you don't often have a complete date for some of these events. A text field can handle a variety of situations at the cost of sorting, etc. I assumed the source feature is a polygon layer, and the new point feature will use the same spatial reference as the polygon layer. If the feature already exists, an error will occur.
Step 2 (lines 52-66) builds the relationship dictionary. It follows Richard Fairhurst's code for labels with few changes.
Step 3 (lines 69+) starts an insert cursor and combines the data from the source feature and related table. I selected the geometry data, the link to the related table, and any other fields of interest. If a link is found, points are added to the new feature; if not found, some error code can run to handle the issue.
The point geometry is calculated using the x-y min and max of the polygon's extent. The polygon is expected to be a simple rectangle or square. The number of expected points is the count of values in the dictionary (or sortedList). A proportion of the distance from x-y min to x-y max is added to the previous point. This results in a series of points being created in a lower-left to upper-right pattern. The points may not fall precisely on an individual grave.
You may need to make modifications for handling the birth and death dates in this section. In addition, modifications may be required if adding or dropping other fields.
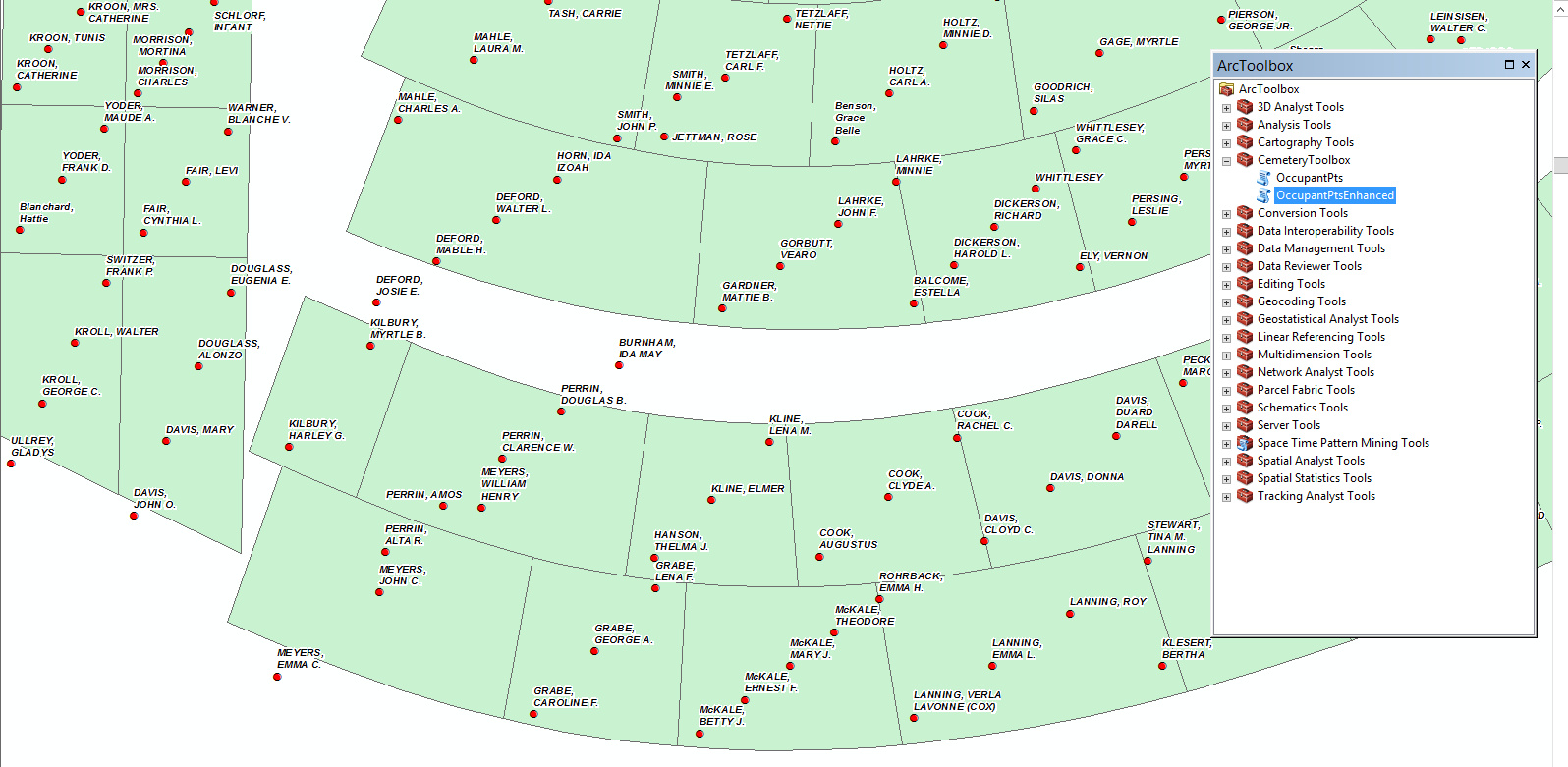
The goal would be to create a new point feature that can be published on AGO. It should have the desired attributes so that someone could search for a name, etc. The name could be used for a label.
If you do not wish to use individual points for each name, another option would be to use a single text field and concatenate the desired information into that field. Some HTML line break codes <BR/> can be added to assist in the final formatting of a label.
Hope this helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you Randy for going to so much trouble and adding such incredible detail to your code. The directions you have supplied should be very helpful. So many times I encounter code through my cloud travels that leave a little too much for me to try and decipher and in the end it becomes a lost cause.
I will attempt to implement and run it through some trials and report back.
Again, many thanks Randy and have a great weekend!
Jeff
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Randy,
I received the following error message when I attempted to run the script..."Index error: tuple index out of range".
Here is the code with some changes that I made...commenting out...etc..
Can you please take a look and see where I might have gone wrong?
Thanks.
Jeff
import arcpy # if not in python window
import os
# Prep work : set up some parameters
# feature with geometry - specifically polygons
fc = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\BSACemeteriesCopy"
# related table with data
relateFC = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\DBOPlotOccJoin"
relateFieldsList = ["UserField4", "Name"] # Born and Died are optional, others can be added
# new point feature we will create
outPath = r'R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb'
outName = 'AGO_cemetery'
outFields = ['SHAPE@X', 'SHAPE@Y', 'Cemetery', 'Plot', 'Name']
# full path to new feature
outFC = os.path.join(outPath, outName)
# Step 1 : create a new feature
# spatial reference for new feature
sr = arcpy.Describe(fc).SpatialReference # same spatial reference as source feature
# create the new feature
arcpy.CreateFeatureclass_management(out_path = outPath, out_name = outName, geometry_type = "POINT",
template = "#", has_m = "DISABLED", has_z = "DISABLED",
spatial_reference = sr)
# create fields (all text): Cemetery, Plot, Name, Born, Died
arcpy.AddField_management(in_table = outFC, field_name = 'Cemetery',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Cemetery", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Plot',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Plot", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Name',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Name", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
#arcpy.AddField_management(in_table = outFC, field_name = 'BirthDate',
#field_type = "STRING", field_precision = "#", field_scale = "#",
#field_length = 20, field_alias = "BirthDate", field_is_nullable = "NULLABLE",
#field_is_required = "NON_REQUIRED", field_domain = "#")
#arcpy.AddField_management(in_table = outFC, field_name = 'DeathDate',
#field_type = "STRING", field_precision = "#", field_scale = "#",
#field_length = 20, field_alias = "DeathDate", field_is_nullable = "NULLABLE",
#field_is_required = "NON_REQUIRED", field_domain = "#")
# Step 2 : build the related dictionary
relateDict = {}
# read the related table's data into a dictionary
# the key will be the first field in the relateFieldsList
# the value will be a list of tuples starting with the second field in the relatedFields list and using index [0]
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
relateKey = relateRow[0]
if not relateKey in relateDict:
relateDict[relateKey] = [relateRow[1:]]
else:
relateDict[relateKey].append(relateRow[1:])
del relateRows, relateRow # clean up
# Step 3 : populate the new feature
# ready an insert cursor and loop through source feature and dictionary
insertCursor = arcpy.da.InsertCursor(outFC, outFields)
with arcpy.da.SearchCursor(fc,['SHAPE@', 'Cemetery', 'GIS_ID']) as cursor:
for row in cursor:
labelKey = row[2] # the link
if labelKey in relateDict:
sortedList = sorted(relateDict[labelKey])
listCount = len(sortedList)
# calculate values for point geometry
xstep = (row[0].extent.XMax - row[0].extent.XMin)/listCount
ystep = (row[0].extent.YMax - row[0].extent.YMin)/listCount
xmin = row[0].extent.XMin + (xstep/2) # x coord for first point
ymin = row[0].extent.YMin + (ystep/2) # y coord for first point
# final data
for fieldValues in sortedList:
name = fieldValues[0]
# assuming the dates are type text/string and not type date
# otherwise some conversion will be required
born = fieldValues[1]
died = fieldValues[2]
# print(xmin, ymin, row[1], labelKey, name, born, died)
insertCursor.insertRow([xmin, ymin, row[1], labelKey, name, born, died])
xmin += xstep # add step to x coord
ymin += ystep # add step to y coord
else: # not in dictionary
pass # substitute with error code if necessary
del insertCursor
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You missed a few lines that still refer to birth and death dates. In my code example, you should also comment out or remove the references in lines 88-92:
# born = fieldValues[1]
# died = fieldValues[2]
# print(xmin, ymin, row[1], labelKey, name) # if printing, remove: born, died
insertCursor.insertRow([xmin, ymin, row[1], labelKey, name])# remove: born, diedIf you have created a new feature, you will need to either delete it or comment out the code section that creates it. Otherwise the code will error out saying the feature already exists.
It helps to use the syntax highlighter when sharing code. The best help is found here: Code Formatting... the basics++.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
import arcpy # if not in python window
import os
# Prep work : set up some parameters
# feature with geometry - specifically polygons
fc = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\BSACemeteriesCopy"
# related table with data
relateFC = r"R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb\DBOPlotOccJoin"
relateFieldsList = ["UserField4", "Name"] # Born and Died are optional, others can be added
# new point feature we will create
outPath = r'R:\Jeff\City_Projects\Cemetery\CemeteryMgmt.gdb'
outName = 'AGO_cemetery'
outFields = ['SHAPE@X', 'SHAPE@Y', 'Cemetery', 'Plot', 'Name']
# full path to new feature
outFC = os.path.join(outPath, outName)
# Step 1 : create a new feature
# spatial reference for new feature
sr = arcpy.Describe(fc).SpatialReference # same spatial reference as source feature
# create the new feature
arcpy.CreateFeatureclass_management(out_path = outPath, out_name = outName, geometry_type = "POINT",
template = "#", has_m = "DISABLED", has_z = "DISABLED",
spatial_reference = sr)
# create fields (all text): Cemetery, Plot, Name, Born, Died
arcpy.AddField_management(in_table = outFC, field_name = 'Cemetery',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Cemetery", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Plot',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Plot", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
arcpy.AddField_management(in_table = outFC, field_name = 'Name',
field_type = "STRING", field_precision = "#", field_scale = "#",
field_length = 50, field_alias = "Name", field_is_nullable = "NULLABLE",
field_is_required = "NON_REQUIRED", field_domain = "#")
#arcpy.AddField_management(in_table = outFC, field_name = 'BirthDate',
#field_type = "STRING", field_precision = "#", field_scale = "#",
#field_length = 20, field_alias = "BirthDate", field_is_nullable = "NULLABLE",
#field_is_required = "NON_REQUIRED", field_domain = "#")
#arcpy.AddField_management(in_table = outFC, field_name = 'DeathDate',
#field_type = "STRING", field_precision = "#", field_scale = "#",
#field_length = 20, field_alias = "DeathDate", field_is_nullable = "NULLABLE",
#field_is_required = "NON_REQUIRED", field_domain = "#")
# Step 2 : build the related dictionary
relateDict = {}
# read the related table's data into a dictionary
# the key will be the first field in the relateFieldsList
# the value will be a list of tuples starting with the second field in the relatedFields list and using index [0]
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
relateKey = relateRow[0]
if not relateKey in relateDict:
relateDict[relateKey] = [relateRow[1:]]
else:
relateDict[relateKey].append(relateRow[1:])
del relateRows, relateRow # clean up
# Step 3 : populate the new feature
# ready an insert cursor and loop through source feature and dictionary
insertCursor = arcpy.da.InsertCursor(outFC, outFields)
with arcpy.da.SearchCursor(fc,['SHAPE@', 'Cemetery', 'GIS_ID']) as cursor:
for row in cursor:
labelKey = row[2] # the link
if labelKey in relateDict:
sortedList = sorted(relateDict[labelKey])
listCount = len(sortedList)
# calculate values for point geometry
xstep = (row[0].extent.XMax - row[0].extent.XMin)/listCount
ystep = (row[0].extent.YMax - row[0].extent.YMin)/listCount
xmin = row[0].extent.XMin + (xstep/2) # x coord for first point
ymin = row[0].extent.YMin + (ystep/2) # y coord for first point
# final data
for fieldValues in sortedList:
name = fieldValues[0]
# assuming the dates are type text/string and not type date
# otherwise some conversion will be required
#born = fieldValues[1]
#died = fieldValues[2]
# print(xmin, ymin, row[1], labelKey, name) # if printing, remove: born, died
insertCursor.insertRow([xmin, ymin, row[1], labelKey, name])# remove: born, died
xmin += xstep # add step to x coord
ymin += ystep # add step to y coord
else: # not in dictionary
pass # substitute with error code if necessary
del insertCursorApologies Randy...here is the code with the syntax highlighter applied.
Jeff